Scrapy 下载图片 文件
1.前言
Scrapy可以说是一辆大车,我们并不需要注重个别的零件(代码),而是注重部件之间的联系。学会使用这个框架,可以说方便又快捷
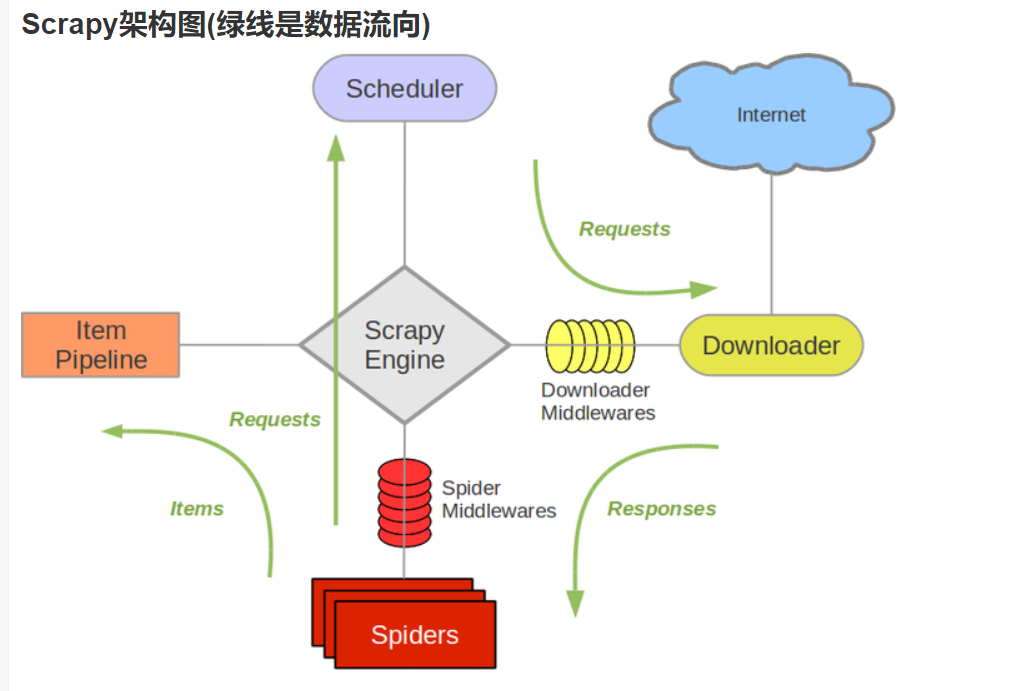
入门可以看看,也有相关书籍和官方文档(不过貌似中文文档很久没更新了)
知道了基本的操作,就可以直接上手了
如果有爬虫经验的话,一天上手完全没问题
一个范例项目1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42import scrapy
from scrapy.linkextractors import LinkExtractor
from ..items import ToscrapeBookItem
class BooksSpider(scrapy.Spider):
name = 'books'
allowed_domains = ['books.toscrape.com']
start_urls = ['http://books.toscrape.com/']
# 书籍列表页面解析
def parse(self, response):
# 提取书籍列表页面中每本书的链接
le = LinkExtractor(restrict_xpaths='//div[@class="image_container"]')
for link in le.extract_links(response):
yield scrapy.Request(link.url, callback=self.book_parse)
# 提取下一页的链接
# le = LinkExtractor(restrict_xpaths='//li[@class="next"]')
# links = le.extract_links(response)
# if links:
# next_url = links[0].url
# yield scrapy.Request(next_url, callback=self.parse)
# 书籍页面信息的解析函数
# review_rating = scrapy.Field()
# review_num = scrapy.Field()
# upc = scrapy.Field() # 编码
# stock = scrapy.Field() # 库存
def book_parse(self, response):
book = ToscrapeBookItem()
book['name'] = response.xpath("//div[contains(@class,'product_main')]//h1/text()").extract_first()
book['price'] = response.xpath("//div[contains(@class,'product_main')]//p/text()").extract_first()
book['review_rating'] = response.xpath("//p[contains(@class,'star-rating')]/@class").re_first(
'star-rating ([a-zA-Z]+)')
book['review_num'] = response.xpath("//table[contains(@class,'table')]//tr[7]/td/text()").extract_first()
book['upc'] = response.xpath("//table[contains(@class,'table')]//tr[1]/td/text()").extract_first()
book['stock'] = response.xpath("//table[contains(@class,'table')]//tr[6]/td/text()").re_first(
'\((\d+) available\)')
print(book)
yield book1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import itemadapter
from itemadapter import ItemAdapter
import openpyxl
class ToscrapeBookPipeline(object):
def __init__(self):
self.wb = openpyxl.Workbook()
self.ws = self.wb.active
def process_item(self, item, spider):
line = [item['name'], item['price'], item['review_rating'], item['review_num'], item['upc'], item['stock']]
self.ws.append(line)
return item
def close_spider(self, spider):
self.wb.save('{}.csv'.format(spider.name))
self.wb.close()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ToscrapeBookItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
price = scrapy.Field()
review_rating = scrapy.Field()
review_num = scrapy.Field()
upc = scrapy.Field() #编码
stock = scrapy.Field() #库存
注意在setting.py中打开管道以及最好把user-agent写一下
并改一下延迟1
2
3
4
5
6ITEM_PIPELINES = {
'toscrape_book.pipelines.ToscrapeBookPipeline': 300,
}
DOWNLOAD_DELAY = 1
ROBOTSTXT_OBEY = False #这个要改为False
2.下载图片和图片
接下来就是文件和图片了
- FilePipeline
- ImagePipeline
利用这两个专门的下载器,我们只用传参就行了,文件会自动下载到本地,并将下载信息存入item的一个字段
步骤
在配置文件(settings.py)中打开管道并设置下载目录
1
2
3
4ITEM_PIPELINES = {
'scrapy.pipelines.files.FilesPipeline': 1,#优先度最高
}
FILES_STORE'./project'在Scrapy解析页面时将文件下载链接收集到一个列表
赋给item的file_urls字段。FilesPipeline在处理item时会读取该项字段并进行下载
1
2
3
4
5
6
7
8def spider(scrapy.spider):
def parse(response):
item ={}
item['file_urls']=[]
for url in response.xpath('').extract():
download_url = response.urljoin(url)
item['file_urls'].append(download_url)
yield item当下载完文件后,会将信息收集到item[‘files’],信息包含:1. path(下载到本地路径)2.Checksum(文件校验和)3.url(文件的url)
以上是FilePipeline的使用
图片类似
导入路径 scrapy.pipelines.images.ImagesPipeline
Item 字段 image_urls images
下载目录 IMAGES_STORE
ImagePipeline在File上增加了对图片的处理
- 生成缩略图 在settings.py中设置IMAGES_THUMBS(dict) 设置字典的每一项值(缩略图的尺寸)
1 | IMAGES_THUMBS = { |
开启该功能,下载一张图片会有三张图片
过滤掉尺寸过小的图片
在配置文件中设置IMAGES_MIN_WIDTH IMAGES_MIN_HEIGHT
分别指定图片最小的宽和高
开启该功能后小于这个尺寸的会忽略
以上资料来源于《精通Scrapy网络爬虫》(刘硕)
实验
写一波实战 爬取图片
网址 | Gelbooru
(感觉有点危险)
第一步
创建项目

1
2
3
4
5scrapy startprojct name
cd name
scrapy genspider name name.com
第二步
明确任务
爬取每一页的图片所在地址以及下一页地址(使用LinkExtractor) a href
爬取图片,使用自带的ImagePipiline
根据之前说的
开启Image.Pipeline管道 不遵守robot协议 设置下载路径
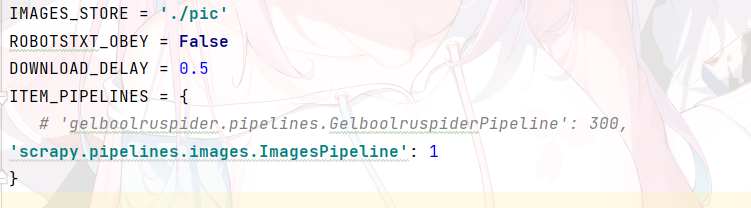
并设置一下user-agent与下载延时
大概这样
然后开写
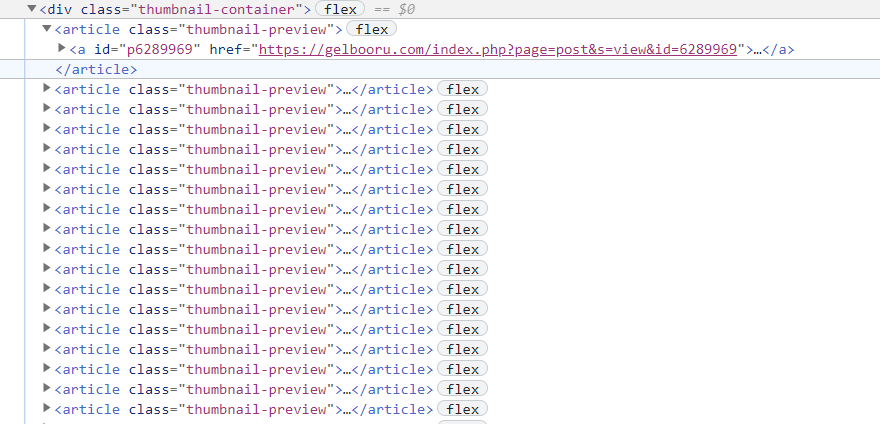
查看元素(最好 Scrapy shell),可以看到每张图片的链接在
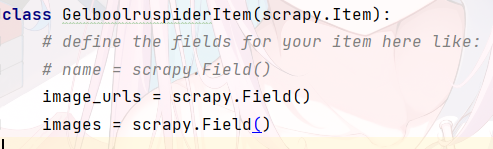
写好item,第一项是要传递的参数,图像的链接供下载
第二项会返回相关信息
根据观察发现,其实pid参数与页数相关,每一页42(其实就是图片数)
所以可以通过改变这个参数发送请求爬取每一页
如果通过获取每一页的下一页链接,我发现它是这样的,通过LinkExtractor后,因为下一页的href总会与存在的某一页的href相同,貌似会覆盖掉.也就是无法通过le.extract_links(response)[-1]得到最后一项
所以我最后没有用LinkExtractor(如果哪位朋友知道如何处理麻烦告知)
直接使用response.xpath获取链接,麻烦的地方就是要将相对地址变为绝对地址

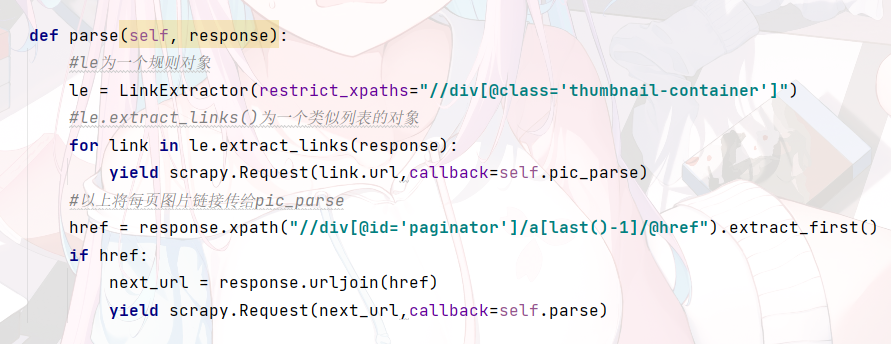
一个是parse ,用于爬取每一张图片的二级链接(首页链接的图片明显偏小)与下一页链接
另一个是pic_parse,用与获取图片链接

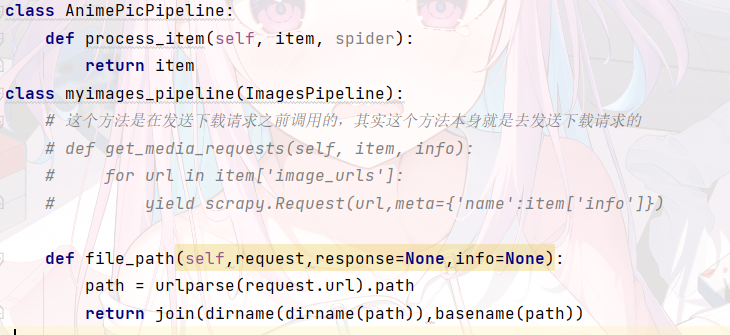
观察可知,图片链接在 这里直接获取链接,注意一定要是列表形式 我有定了两个字段想用来重命名图片名 可以复写ImagesPipeline使图片名字自定义.但我这里没写。类似下面这样 最后 scrapy crawl name 运行即可 注意 我这里没有写停止条件,即会一直爬到最后 只要写一个控制就行了 最后 如果有问题请回复 我也是才学 欢迎关注我的其它发布渠道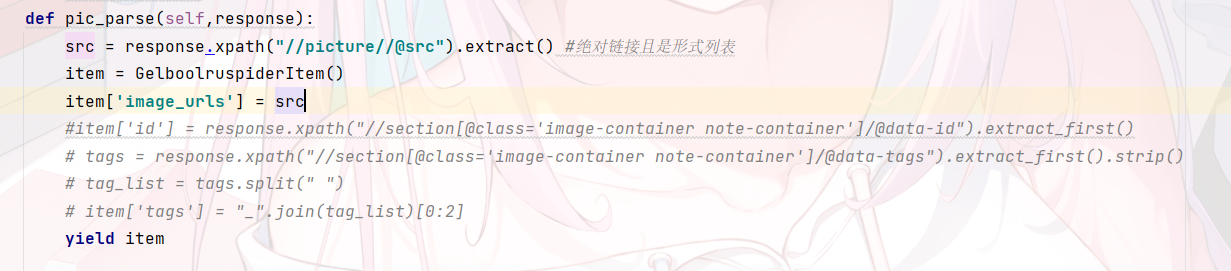
1
for i in range(1,51): url = "https://gelbooru.com/index.php?page=post&s=list&tags=all&pid={}".format(i) yield scrapy.Request(url,callback=self.parse()) #控制爬取的页数
