继续之前的写编译器.
acwj意思是A Compiler Writing Journey.
之前写了scan和parser,简单的过了加减乘除的操作.
操作符优先级
现在需要定一下操作符优先级.有两种办法,都是递归下降方法
在语言语法中明确运算符优先级
使用运算符优先级表影响现有解析器
这里采用改变语法的方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17expression: additive_expression
;
additive_expression:
multiplicative_expression
| additive_expression '+' multiplicative_expression
| additive_expression '-' multiplicative_expression
;
multiplicative_expression:
number
| number '*' multiplicative_expression
| number '/' multiplicative_expression
;
number: T_INTLIT
;
可以看到先进行乘再进行加.
在代码中,定义乘除函数与加减函数.
加减法优先级较低,所以在加减函数中需要调用乘除函数.而乘除函数自然需要调用primary,这里就是取字面量的意思.
乘除函数核心代码.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
left = primary(); //取值 primary中也有scan.
tokentype = Token.token; //更新tokentype
if (tokentype == _EOF) //若读到末尾则直接返回.
{
return left;
}
// * /
//如果有乘除号 进入循环
while (tokentype == STAR || tokentype == SLASH)
{
//继续得到右边的值
scan(&Token);
right = primary(); //获取intlitnode,right是一个leaf node.
// e.g * 2 6
left = mkastnode(tok2aop(tokentype), left, right, 0); //e.g * 2 5
// Update the details of the current token.
// If no tokens left, return just the left node
tokentype = Token.token; //更新
if (tokentype == _EOF)
{
break;
} //看是否读到文件末尾 否则继续读 直到不是乘除号
}
return left;
加减函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25left = multiplicative_expr(); //首先需要调用乘除 优先级问题
tokentype = Token.token;
if(tokentype == _EOF)
{
return left;
}
//同上
while (1) //进入循环
{
scan(&Token);
right = multiplicative_expr(); //同理 先调用乘除
left = mkastnode(tok2aop(tokentype),left,right,0); // left = left + right
tokentype = Token.token;
if(tokentype == _EOF)
{
break;
}
}
return left;
这种方法缺点是需要为每种运算设置谁优先级高,比较麻烦.
还可以用Pratt Parsing.
也就是为每一种操作符设置一个优先级值.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31left = primary();
// If no tokens left, return just the left node
tokentype = Token.token;
if (tokentype == T_EOF)
return (left);
// While the precedence of this token is
// more than that of the previous token precedence
while (op_precedence(tokentype) > ptp) {
// Fetch in the next integer literal
scan(&Token);
// Recursively call binexpr() with the
// precedence of our token to build a sub-tree
right = binexpr(OpPrec[tokentype]);
// Join that sub-tree with ours. Convert the token
// into an AST operation at the same time.
left = mkastnode(arithop(tokentype), left, right, 0);
// Update the details of the current token.
// If no tokens left, return just the left node
tokentype = Token.token;
if (tokentype == T_EOF)
return (left);
}
// Return the tree we have when the precedence
// is the same or lower
return (left);
生成汇编
尝试生成汇编代码.
生成汇编也是遍历AST.1
2
3
4
5
6
7
8void generatecode(struct ASTnode *n) {
int reg;
cgpreamble();
reg= genAST(n);
cgprintint(reg); // Print the register with the result as an int
cgpostamble();
}
pre和post是汇编进出main的一般语句.同时为了打印寄存器的值使用了printint函数也在汇编pre中声明了.
另外有free,allocate寄存器。先free使寄存器值为1,再allocate使用,由置为0.allocate后又能free.
当然还有一些运算的汇编代码,比如1
2
3
4
5int cgmul(int r1,int r2) {
fprintf(Outfile,"\timulq\t%s,%s\n",reglist[r1],reglist[r2]);
free_reg(r1);
return r2;
}
减法,除法需要注意顺序.
注意除法相对麻烦1
2
3
4fprintf(Outfile, "\tmovq\t%s,%%rax\n", reglist[r1]);
fprintf(Outfile, "\tcqo\n");
fprintf(Outfile, "\tidivq\t%s\n", reglist[r2]);
fprintf(Outfile, "\tmovq\t%%rax,%s\n", reglist[r1]);
Division is also not commutative, so the previous notes apply. On the x86-64, it’s even more complicated. We need to load
%raxwith the dividend fromr1. This needs to be extended to eight bytes withcqo. Then,idivqwill divide%raxwith the divisor inr2, leaving the quotient in%rax, so we need to copy it out to eitherr1orr2. Then we can free the other register.
增加一些语句
之前词法语法分析都是一些运算符,现在增加一些Statement.1
2
3
4
5
6statements: statement
| statement statements
;
statement: 'print' expression ';'
;
先只有print语句
An input file consists of several statements. They are either one statement, or a statement followed by more statements. Each statement starts with the keyword
statement语句是print后接binexpr再有一个分号1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23struct ASTnode *tree;
int reg;
while (1)
{
// match print
match(PRINT, "print");
tree = binexpr(0); // expr ast
reg = genAST(tree); // return reg num
// print value
genprintint(reg);
genfreeregs();
semi();
// 之前卡在这 因为 == 写成了 = :(
// 判断到达文件尾
if (Token.token == _EOF)
{
return;
}
}
之前写了binexpr,根据这个生成AST再遍历得到值.
此外还要判定identifier,以字母或_开头1
2
3
4
5
6
7
8
9
10
11
12
13
14if (isalpha(c) || '_' == c)
{
// read ident
scanident(c, Text, TEXTLEN);
// ! focus,it's =
if (tokentype = keyword(Text))
{
t->token = tokentype;
break;
}
// if this is not keyword
printf("Unrecognised symbol %s on line %d\n", Text, Line);
}
如果是关键字,设置toke类型.
此外还要设置匹配关键字1
2
3
4
5
6
7
8
9
10
11
12
13// 匹配
void match(int t, char *what)
{
if (Token.token == t)
{
scan(&Token);
}
else
{
printf("%s expected on line %d\n", what, Line);
exit(1);
}
}
*what是需要匹配的关键字,t是token的类型,比如PRINT.
当匹配成功继续读入下一个字符.
读入ident1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23int i = 0;
while (isalpha(c) || isdigit(c) || '_' == c)
{
// Error if we hit the identifier length limit,
// else append to buf[] and get next character
// lim is the identifier max length that we defined
if (lim - 1 == i)
{
printf("identifier too long on line %d\n", Line);
exit(1);
}
else if (i < lim - 1)
{
buf[i++] = c;
}
c = next();
}
// c is not included in this ident so we trace back
putback(c);
buf[i] = '\0';
return i;
当匹配首字符后,读入ident,限定ident大小.同时当读入的token不满足条件时跳出,并将其putback.方便下次读入.
同时在expr中改为遇到分号就结束,而不是文件尾.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26left = primary();
tokentype = Token.token;
if (tokentype == SEMI)
{
return left;
}
// While the precedence of this token is
// more than that of the previous token precedence
while (op_precedence(tokentype) > ptp)
{
scan(&Token);
right = binexpr(OpPrec[tokentype]);
left = mkastnode(tok2aop(tokentype), left, right, 0);
// Update the details of the current token.
// If no tokens left, return just the left node
tokentype = Token.token;
if (tokentype == SEMI)
return (left);
}
return left;
变量
我们需要
- Declare variables
- Use variables to get stored values
- Assign to variables
需要一个全局变量表1
2
3
4// Symbol table structure
struct symtable {
char *name; // Name of a symbol
};
变量表1
2
3
extern_ struct symtable Gsym[NSYMBOLS]; // Global symbol table 变量表
static int Globs = 0; // Position of next free global symbol slot 变量在变量表中位置
int findglob(char *s): Determine if the symbol s is in the global symbol table. Return its slot position or -1 if not found.static int newglob(void): Get the position of a new global symbol slot, or die if we’ve run out of positions.int addglob(char *name): Add a global symbol to the symbol table. Return the slot number in the symbol table
同时需要新的语法1
2
3
4
5
6
7
8
9
10
11statements: statement
| statement statements
;
statement: 'print' expression ';'
| 'int' identifier ';'
| identifier '=' expression ';'
;
identifier: T_IDENT
;
statementes需要更改1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// Parse one or more statements
void statements(void) {
while (1) {
switch (Token.token) {
case T_PRINT:
print_statement();
break;
case T_INT:
var_declaration();
break;
case T_IDENT:
assignment_statement();
break;
case T_EOF:
return;
default:
fatald("Syntax error, token", Token.token);
}
}
}
we will make the expression the left sub-tree of the A_ASSIGN node and save the A_LVIDENT details in the right sub-tree. Why? Because we need to evaluate the expression before we save it into the variable.
Note that we evaluate the left-hand AST child first, and we get back a register number that holds the left-hand sub-tree’s value. We now pass this register number to the right-hand sub-tree. We need to do this for A_LVIDENT nodes, so that the
cgstorglob()function incg.cknows which register holds the rvalue result of the assignment expression.
这里左右是反的,由于我们是先序遍历AST,但又需要先计算右值,所以在赋值语句中,先读入identifier,创建LVIDENT节点赋值给rightreg,然后为leftreg创建expr,最后生成赋值节点.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28// identifier '=' expression ';'
struct ASTnode *left, *right, *tree;
// pos of reg
int id;
ident();
if ((id = findglob(Text)) == -1)
{
fatals("Undeclared variable", Text);
}
right = mkastleaf(A_LVIDENT, id);
match(EQUAL, "=");
// Parse the following expression
left = binexpr(0);
// Make an assignment AST tree
tree = mkastnode(A_ASSIGN, left, right, 0);
// Generate the assembly code for the assignment
genAST(tree, -1);
genfreeregs();
semi();
Also note that the AST leaf node that retrieves a variable’s value is an A_IDENT node. The leaf that saves into a variable is an A_LVIDENT node. This is the difference between rvalues and lvalues.
比较符
增加词法分析,增加genAST操作.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15case A_EQ:
return cgequal(leftreg,rightreg);
case A_NE:
return cgnotequal(leftreg,rightreg);
case A_LT:
return cglessthan(leftreg,rightreg);
case A_GT:
return cggreaterthan(leftreg,rightreg);
case A_LE:
return cglessequal(leftreg,rightreg);
case A_GE:
return cggreaterequal(leftreg,rightreg);
default:
fatald("Unknown AST operator",n->op);
}
遇到的问题
There are six x86-64 instructions which set a register to 1 or 0 based on the two flag values:
sete,setne,setg,setl,setgeandsetlein the order of the above table rows.The problem is, these instructions only set the lowest byte of a register. If the register already has bits set outside of the lowest byte, they will stay set. So we might set a variable to 1, but if it already has the value 1000 (decimal), then it will now be 1001 which is not what we want.
The solution is to andq the register after the setX instruction to get rid of the unwanted bits. In cg.c there is a general comparison function to do this:
核心代码1
2
3
4
5
6
7fprintf(Outfile,"\tcmpq\t%s,%s\n",reglist[r2],reglist[r1]);
fprintf(Outfile,"\t%s\t%s\n",how,breglist[r2]);
// 低字节与1相与 全设置为1 因为setx指令只设置低字节 高字节不变,所以需要将高字节清除
fprintf(Outfile, "\tandq\t$255,%s\n", reglist[r2]);
free_reg(r1);
return r2;
Note that we perform
because this is actually
reglist[r1] - reglist[r2]which is what we really want.
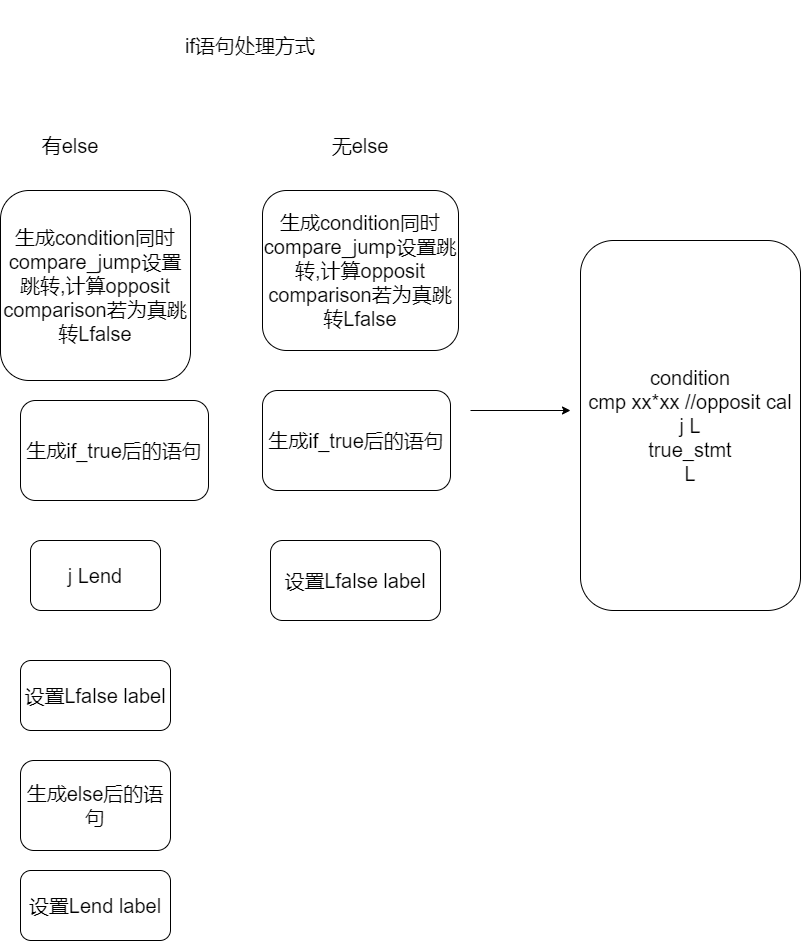
if语句
1 | if (condition is true) |
使用比较运算符1
2
3
4
5
6
7 perform the opposite comparison
jump to L1 if true
perform the first block of code
jump to L2
L1:
perform the other block of code
L2:
举一个例子
Right now, we output code to set a register based on a comparison, e.g.1
int x; x= 7 < 9; From input04
becomes1
2
3
4
5movq $7, %r8
movq $9, %r9
cmpq %r9, %r8
setl %r9b Set if less than
andq $255,%r9
But for an IF statement, we need to jump on the opposite comparison:1
if (7 < 9)
should become:1
2
3
4
5
6 movq $7,
movq $9,
cmpq ,
jge L1 Jump if greater then or equal to
....
L1:
文法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24compound_statement: '{' '}' // empty, i.e. no statement
| '{' statement '}'
| '{' statement statements '}'
;
statement: print_statement
| declaration
| assignment_statement
| if_statement
;
print_statement: 'print' expression ';' ;
declaration: 'int' identifier ';' ;
assignment_statement: identifier '=' expression ';' ;
if_statement: if_head
| if_head 'else' compound_statement
;
if_head: 'if' '(' true_false_expression ')' compound_statement ;
identifier: T_IDENT ;
Note the grammar for the IF statement: it’s either an
if_head(with no ‘else’ clause), or anif_headfollowed by a ‘else’ and acompound_statement.
解决悬挂else问题
if ast 修改ast结构以适应if
- the sub-tree that evaluates the condition
- the compound statement immediately following
- the optional compound statement after the ‘else’ keyword
实现while循环
1 | Lstart: evaluate condition |
while的BNF1
// while_statement: 'while' '(' true_false_expression ')' compound_statement ;
说实话做起来要比if简单些,主要是在if中实现了添加label和跳转的x86汇编.后面直接做词法语法分析就行了.
词法分析
while_stmt1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20struct ASTnode *while_stmt(void)
{
struct ASTnode *condAST, *bodyAST;
// match while(
match(WHILE, "while");
lparen();
condAST = binexpr(0);
if (condAST->op < A_EQ || condAST->op > A_GE)
{
fatal("Bad comparison operator");
}
rparen();
// get the ast for com_stmt
bodyAST = compound_stmt();
return mkastnode(A_WHILE, condAST, NULL, bodyAST, 0);
}
gen.c1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28static int genWHILE(struct ASTnode *n)
{
int Lstart, Lend;
// get label
Lstart = label();
Lend = label();
// generate label
cglabel(Lstart);
// 与if类似 计算n->left 满足条件跳转
genAST(n->left, Lend, n->op);
genfreeregs();
// compound stmt
genAST(n->right, NOREG, n->op);
genfreeregs();
// Finally output the jump back to the condition,
// and the end label
// 继续跳回去计算
cgjump(Lstart);
cglabel(Lend);
return NOREG;
}
for循环
BNF范式1
2
3
4
5
6for_statement: 'for' '(' preop_statement ';'
true_false_expression ';'
postop_statement ')' compound_statement ;
preop_statement: statement ; (for now)
postop_statement: statement ; (for now)
遇到的问题
The wrinkle is that the
postop_statementis parsed before thecompound_statement, but we have to generate the code for thepostop_statementafter the code for thecompound_statement.
解决
There are several ways to solve this problem. When I wrote a previous compiler, I chose to put the
compound_statementassembly code in a temporary buffer, and “play back” the buffer once I’d generated the code for thepostop_statement. In the SubC compiler, Nils makes clever use of labels and jumps to labels to “thread” the code’s execution to enforce the correct sequence.
1 | preop_statement; |
ast仍采用三节点1
2
3
4
5
6
7 A_GLUE
/ \
preop A_WHILE
/ \
decision A_GLUE
/ \
compound postop
For the FOR grammar, I only want a single statement as the
preop_statementand thepostop_statement. Right now, we have acompound_statement()function that simply loops until it hits a right curly bracket ‘}’. We need to separate this out socompound_statement()callssingle_statement()to get one statement
需要写一个single_stmt()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23static struct ASTnode *single_stmt(void)
{
switch (Token.token)
{
case PRINT:
return print_stmt();
break;
case INT:
int_decl();
return NULL;
case IDENT:
return assign_stmt();
case IF:
return if_stmt();
case WHILE:
return while_stmt();
case FOR:
return for_stmt();
default:
fatald("Syntax error, token", Token.token);
}
}
这个不需要;
将assign和print语句的分号需求也去掉.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39struct ASTnode *compound_stmt(void)
{
struct ASTnode *left = NULL;
struct ASTnode *tree;
// match {
lbrace();
while (1)
{
tree = single_stmt();
// assign,print need simicon
if (tree != NULL && (tree->op == A_PRINT || tree->op == A_ASSIGN))
{
semi();
}
// For each new tree, either save it in left
// if left is empty, or glue the left and the
// new tree together
if (tree != NULL)
{
if (left == NULL)
{
left = tree;
}
else
{
left = mkastnode(A_GLUE, left, NULL, tree, 0);
}
}
// }
if (Token.token == RBRACE)
{
rbrace();
return left;
}
}
}
在复合语句中对print和赋值语句的分号做要求.
What we need is for the single statement parser not to scan in the semicolon, but to leave that up to the compound statement parser. And we scan in semicolons for some statements (e.g. between assignment statements) and not for other statements (e.g. not between successive IF statements).
在生成ast时注意顺序1
2
3
4
5
6
7
8// Glue the compound statement and the postop tree
tree= mkastnode(A_GLUE, bodyAST, NULL, postopAST, 0);
// Make a WHILE loop with the condition and this new body
tree= mkastnode(A_WHILE, condAST, NULL, tree, 0);
// And glue the preop tree to the A_WHILE tree
return(mkastnode(A_GLUE, preopAST, NULL, tree, 0));
实现函数
需要处理的部分
- Types of data:
char,int,longetc. - The return type of each function
- The number of arguments to each function
- Variables local to a function versus global variables
首先是简单部分1
function_declaration: 'void' identifier '(' ')' compound_statement ;
即函数声明,与变量声明类似.
需要将函数名加入globsym.1
2
3
4
5
6
7
8
9
10
11
12match(T_VOID, "void");
ident();
nameslot= addglob(Text);
lparen();
rparen();
// Get the AST tree for the compound statement
tree= compound_statement();
// Return an A_FUNCTION node which has the function's nameslot
// and the compound statement sub-tree
return(mkastunary(A_FUNCTION, tree, nameslot));
在main中修改1
2
3
4
5
6
7
8scan(&Token); // Get the first token from the input
genpreamble(); // Output the preamble
while (1) { // Parse a function and
tree = function_declaration();
genAST(tree, NOREG, 0); // generate the assembly code for it
if (Token.token == T_EOF) // Stop when we have reached EOF
break;
}
生成汇编1
2
3
4
5
6case A_FUNCTION:
// generate code
cgfuncpreamble(Gsym[n->v.id].name);
genAST(n->left, NOREG, n->op);
cgfuncpostamble();
return NOREG;
增加类型
增加char
every expression has a type. This includes:
- integer literals, e.g 56 is an
int - maths expressions, e.g. 45 - 12 is an
int - variables, e.g. if we declared
xas achar, then it’s rvalue is achar
增加原型类型1
2
3
4// Primitive types
enum {
P_NONE, P_VOID, P_CHAR, P_INT
};
现阶段,none修饰控制语句,void是函数符号,char,int是变量符号.1
2
3
4
5struct ASTnode {
int op; // "Operation" to be performed on this tree
int type; // Type of any expression this tree generates
...
};
ast也有type,现在主要用于widen.
主要修改一些语句,比如primary1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34// Parse a primary factor and return an
// AST node representing it.
static struct ASTnode *primary(void) {
struct ASTnode *n;
int id;
switch (Token.token) {
case T_INTLIT:
// For an INTLIT token, make a leaf AST node for it.
// Make it a P_CHAR if it's within the P_CHAR range
if ((Token.intvalue) >= 0 && (Token.intvalue < 256))
n = mkastleaf(A_INTLIT, P_CHAR, Token.intvalue);
else
n = mkastleaf(A_INTLIT, P_INT, Token.intvalue);
break;
case T_IDENT:
// Check that this identifier exists
id = findglob(Text);
if (id == -1)
fatals("Unknown variable", Text);
// Make a leaf AST node for it
n = mkastleaf(A_IDENT, Gsym[id].type, id);
break;
default:
fatald("Syntax error, token", Token.token);
}
// Scan in the next token and return the leaf node
scan(&Token);
return (n);
}
根据值看生成CHAR类型还是INT类型节点.
print语句1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16static struct ASTnode *print_statement(void) {
struct ASTnode *tree;
int lefttype, righttype;
int reg;
...
// Parse the following expression
tree = binexpr(0);
// Ensure the two types are compatible.
lefttype = P_INT; righttype = tree->type;
if (!type_compatible(&lefttype, &righttype, 0))
fatal("Incompatible types");
// Widen the tree if required.
if (righttype) tree = mkastunary(righttype, P_INT, tree, 0);
print 后面要求是int(char其实也可以)
如果需要widen,则生成一个WIDEN节点,类型是int.
最后生成print节点,类型也是None.1
tree = mkastunary(A_PRINT,P_NONE,tree,0);
assign语句1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21static struct ASTnode *assignment_statement(void) {
struct ASTnode *left, *right, *tree;
int lefttype, righttype;
int id;
...
// Make an lvalue node for the variable
right = mkastleaf(A_LVIDENT, Gsym[id].type, id);
// Parse the following expression
left = binexpr(0);
// Ensure the two types are compatible.
lefttype = left->type;
righttype = right->type;
if (!type_compatible(&lefttype, &righttype, 1)) // Note the 1
fatal("Incompatible types");
// Widen the left if required.
if (lefttype)
left = mkastunary(lefttype, right->type, left, 0);
也是主要检查是否可以widen,而赋值语句只允许char widens to int.右值是char.
注意赋值语句中节点的right是左值,left是右值.所以onlyright设置为11
2int i;
i = 6;
这里6其实是char类型,因为6处在char范围内,但是赋值语句生成widen节点,相当于1
left = mkastunary(lefttype, right->type, left, 0);
op:WIDEN,type:int
最后返回赋值语句节点1
tree = mkastnode(A_ASSIGN,P_INT,left,NULL,right,0);
更多函数
- define a function, which we already have,
- call a function with a single value which for now cannot be used,
- return a value from a function,
- use a function call as both a statement and also an expression, and
- ensure that void functions never return a value and non-void functions must return a value.
1 | function_call: identifier '(' expression ')' ; |
后面移植到了ARM下,在Linux上安装了gcc的arm版本,可以生成arm汇编生成可执行程序.安装qemu,执行arm程序.
新的语法
1 | global_declarations : global_declarations |
Prefix Operators ‘*’ and ‘&’
With declarations out of the road, let’s now look at parsing expressions where ‘*’ and ‘&’ are operators that come before an expression. The BNF grammar looks like this:1
2
3
4prefix_expression: primary
| '*' prefix_expression
| '&' prefix_expression
;
更多操作
| ` | ` | T_LOGOR | |
|---|---|---|---|
&& | T_LOGAND | ||
| ` | ` | T_OR | |
^ | T_XOR | ||
<< | T_LSHIFT | ||
>> | T_RSHIFT | ||
++ | T_INC | ||
-- | T_DEC | ||
~ | T_INVERT | ||
! | T_LOGNO |
增加全局变量与局部变量.
Type Checking and Pointer Offsets
