唉,很久没做做题了.这里记录一下每天刷题练习.
主要刷一些简单中等题,难了我也不会.
剑指Offer 启动
09.用两个栈实现队列1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40package 用两个栈实现队列;
import java.util.ArrayDeque;
import java.util.Deque;
public class CQueue2 {
Deque<Integer> inStack;
Deque<Integer> outStack;
public CQueue2() {
inStack = new ArrayDeque<>();
outStack = new ArrayDeque<>();
}
public void appendTail(int value) {
inStack.push(value);
}
public int deleteHead() {
if(outStack.isEmpty())
{
if(inStack.isEmpty())
{
return -1;
}
else
{
while(!inStack.isEmpty())
{
outStack.push(inStack.pop());
}
return outStack.pop();
}
}
return outStack.pop();
}
}
设计一个有getMin功能的栈
1 | 实现一个特殊的栈,在实现栈的基本功能的基础上,再实现返回栈中最小元素的操作。 |
【要求】
1.pop、push、getMin 操作的时间复杂度都是 O(1)。 2.设计的栈类型可以使用现成的栈结构
设计方案
使用辅助栈,多一个存最小值的栈stackmin. 即有stackdata和stackmin
第一种
压入规则
压入数据时,stackdata直接压入;stackmin如果为空,直接压入,如果不为空,进行比较:将要压入的值和栈顶的值进行比较,如果栈顶值更小则不处理,否则压入.
弹出规则
stackdata弹出数据,将弹出的数据与stackmin顶数据比较,如果弹出数据等于stackmin栈顶数据,则同时弹出stackmin数据,否则不处理.
最小值即位stackmin中栈顶值
第二种
压入规则
压入数据时,stackdata直接压入;stackmin如果为空也直接压入,否则将栈顶数据与待压入数据比较,如果栈顶数据更小,则stackmin再压入一次栈顶数据,否则stackmin压入待压入数据.
弹出规则
两个栈都弹出
最小值也是stackmin的栈顶1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43class MinStack {
public:
stack<int>s,min_s;
MinStack() {
}
void push(int val) {
if(s.empty())
{
s.emplace(val);
min_s.emplace(val);
}
else
{
int topvalue = min_s.top();
if(topvalue>val)
{
min_s.emplace(val);
}
else{
min_s.emplace(topvalue);
}
s.emplace(val);
}
}
void pop() {
s.pop();
min_s.pop();
}
int top() {
return s.top();
}
int min() {
return min_s.top();
}
};
从尾到头打印链表
输入一个链表的头节点,从尾到头反过来返回每个节点的值(用数组返回)
设计方案
利用栈结构或者使用递归
这里使用递归1
2
3
4
5
6
7
8
9
10
11
12
13class Solution {
public:
vector<int> reversePrint(ListNode* head) {
if(!head)
{
return {};
}
vector<int> v =reversePrint(head->next);
v.push_back(head->val);
return v;
}
}
使用辅助栈结构1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Solution {
public:
vector<int> reversePrint(ListNode* head) {
stack<int> s;
for(ptr it=head;it!=nullptr;it=it->next)
{
s.push(it->val);
}
vector<int> v;
while(!s.empty())
{
int val = s.top();
s.pop();
v.push_back(val);
}
return v;
}
};
反转链表
定义一个函数,输入一个链表的头节点,反转该链表并输出反转后链表的头节点。
示例:1
2输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL
解决方案
1 | /** |
使用递归方法1
2
3
4
5
6
7
8
9
10
11
12class Solution {
public:
ListNode* reverseList(ListNode* head) {
if (!head || !head->next) {
return head;
}
ListNode* newHead = reverseList(head->next);
head->next->next = head;
head->next = nullptr;
return newHead;
}
};
复杂链表的复制
请实现 copyRandomList 函数,复制一个复杂链表。在复杂链表中,每个节点除了有一个 next 指针指向下一个节点,还有一个 random 指针指向链表中的任意节点或者 null。
解题思路
- 回溯和哈希表(或者单独使用哈希表)
1 |
|
迭代+节点拆分
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25class Solution {
public:
Node* copyRandomList(Node* head) {
if (head == nullptr) {
return nullptr;
}
for (Node* node = head; node != nullptr; node = node->next->next) {
Node* nodeNew = new Node(node->val);
nodeNew->next = node->next;
node->next = nodeNew;
}
for (Node* node = head; node != nullptr; node = node->next->next) {
Node* nodeNew = node->next;
nodeNew->random = (node->random != nullptr) ? node->random->next : nullptr;
}
Node* headNew = head->next;
for (Node* node = head; node != nullptr; node = node->next) {
Node* nodeNew = node->next;
node->next = node->next->next;
nodeNew->next = (nodeNew->next != nullptr) ? nodeNew->next->next : nullptr;
}
return headNew;
}
};
Update
Source:
- LeetCode 101: 力扣刷题指南 (第二版) | LeetCode 101 - A Grinding Guide
- 代码随想录
- 本站简介 | labuladong 的算法笔记
- 剑指Offer
- leetcode hot 100
将题型按照算法类型和使用的数据结构进行分类.
贪心算法
顾名思义,贪心算法或贪心思想 区间问题 采用贪心的策略,保证每次操作都是局部 最优的,从而使最后得到的结果是全局最优的
证明一道题能用贪心算法解决,有时远比用贪心算法解决该题更复杂。一般情况下,在简单 操作后,具有明显的从局部到整体的递推关系,或者可以通过数学归纳法推测结果时,我们才会 使用贪心算法。
121 买卖股票最佳时机
我们来假设自己来购买股票。随着时间的推移,每天我们都可以选择出售股票与否。那么,假设在第 i 天,如果我们要在今天卖股票,那么我们能赚多少钱呢?
显然,如果我们真的在买卖股票,我们肯定会想:如果我是在历史最低点买的股票就好了.在题目中,只要用一个变量记录一个历史最低价格 minprice,我们就可以假设自己的股票是在那天买的。那么我们在第 i 天卖出股票能得到的利润就是 prices[i] - minprice。
因此,我们只需要遍历价格数组一遍,记录历史最低点,然后在每一天考虑这么一个问题:如果我是在历史最低点买进的,那么我今天卖出能赚多少钱?当考虑完所有天数之时,我们就得到了最好的答案。
作者:力扣官方题解
链接:https://leetcode.cn/problems/best-time-to-buy-and-sell-stock/solutions/136684/121-mai-mai-gu-piao-de-zui-jia-shi-ji-by-leetcode-/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1 | int maxProfit = 0; |
122 买卖股票的最佳时机 II
代码随想录1
2
3
4
5
6
7
8int maxProfit = 0;
if (prices.size() < 2) {
return maxProfit;
}
for (int i = 1; i < prices.size(); i++) {
maxProfit += std::max(prices[i] - prices[i - 1], 0);
}
return maxProfit;
只需要计算有利益的区间和即可.
455分发饼干
因为饥饿度最小的孩子最容易吃饱,所以我们先考虑这个孩子。为了尽量使得剩下的饼干可 以满足饥饿度更大的孩子,所以我们应该把大于等于这个孩子饥饿度的、且大小最小的饼干给这个孩子。满足了这个孩子之后,我们采取同样的策略,考虑剩下孩子里饥饿度最小的孩子,直到 没有满足条件的饼干存在。 简而言之,这里的贪心策略是,给剩余孩子里最小饥饿度的孩子分配最小的能饱腹的饼干1
2
3
4
5
6
7
8
9
10
11
12
13int findContentChildren(vector<int> &children, vector<int> &cookies) {
sort(children.begin(), children.end());
sort(cookies.begin(), cookies.end());
int child_i = 0, cookie_i = 0;
int n_children = children.size(), n_cookies = cookies.size();
while (child_i < n_children && cookie_i < n_cookies) {
if (children[child_i] <= cookies[cookie_i]) {
++child_i;
}
++cookie_i;
}
return child_i;
}
135分发糖果
存在比较关系的贪心策略并不一定需要排序。虽然这一道题也是运用贪心策略,但我们只需 要简单的两次遍历即可:把所有孩子的糖果数初始化为;先从左往右遍历一遍,如果右边孩子 的评分比左边的高,则右边孩子的糖果数更新为左边孩子的糖果数加;再从右往左遍历一遍, 如果左边孩子的评分比右边的高,且左边孩子当前的糖果数不大于右边孩子的糖果数,则左边孩子的糖果数更新为右边孩子的糖果数加。通过这两次遍历,分配的糖果就可以满足题目要求了。 这里的贪心策略即为,在每次遍历中,只考虑并更新相邻一侧的大小关系1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17int candy(std::vector<int> &ratings) {
std::vector<int> candies(ratings.size(), 1);
for (int i = 0; i < candies.size() - 1; i++) {
// 从左到右遍历,如果右边比左边大,右边糖果比左边+1
if (ratings[i] < ratings[i + 1]) {
candies[i + 1] = candies[i] + 1;
}
// 如果左边与右边的相等,均不增加
}
for (int i = candies.size() - 1; i > 0; i--) {
// 从右到左遍历,如果左边比右边大,并且左边的糖果不大于右边的糖果,左边的糖果=右边的糖果+1
if (ratings[i] < ratings[i - 1] && candies[i] >= candies[i - 1]) {
candies[i - 1] = candies[i] + 1;
}
}
return std::accumulate(candies.begin(), candies.end(), 0);
}
435无重叠区间
求最少的移除区间个数,等价于尽量多保留不重叠的区间。在选择要保留区间时,区间的结尾十分重要:选择的区间结尾越小,余留给其它区间的空间就越大,就越能保留更多的区间。因此,我们采取的贪心策略为,优先保留结尾小且不相交的区间。
具体实现方法为,先把区间按照结尾的大小进行增序排序(利用 lambda 函数),每次选择结尾最小且和前一个选择的区间不重叠的区间。
在样例中,排序后的数组为 [[1,2], [1,3], [2,4]]。按照我们的贪心策略,首先初始化为区间[1,2];由于 [1,3] 与 [1,2] 相交,我们跳过该区间;由于 [2,4] 与 [1,2] 不相交,我们将其保留。因此最终保留的区间为 [[1,2], [2,4]]。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19if (intervals.size() <= 1) {
return 0;
}
// 排序,根据start
std::sort(intervals.begin(), intervals.end(),
[](const std::vector<int> &a, const std::vector<int> &b) {
return a[1] < b[1];
});
int count = 0;
// 当根据开始时间排序后,下一个的开始时间必须大于等于当前结束时间
int prevEnd = intervals[0][1];
for (int i = 0; i < intervals.size() - 1; i++) {
if (prevEnd > intervals[i + 1][0]) {
count++;
}else{
prevEnd = intervals[i + 1][1];
}
}
return count;
双指针
双指针主要用于遍历数组,两个指针指向不同的元素,从而协同完成任务。也可以延伸到多 个数组的多个指针。 若两个指针指向同一数组,遍历方向相同且不会相交,则也称为滑动窗口(两个指针包围的 区域即为当前的窗口),经常用于区间搜索。
若两个指针指向同一数组,但是遍历方向相反,则可以用来进行搜索,待搜索的数组往往是 排好序的。
167 两数之和
因为数组已经排好序,我们可以采用方向相反的双指针来寻找这两个数字,一个初始指向最 小的元素,即数组最左边,向右遍历;一个初始指向最大的元素,即数组最右边,向左遍历。 如果两个指针指向元素的和等于给定值,那么它们就是我们要的结果。如果两个指针指向元 素的和小于给定值,我们把左边的指针右移一位,使得当前的和增加一点。如果两个指针指向元 素的和大于给定值,我们把右边的指针左移一位,使得当前的和减少一点。 可以证明,对于排好序且有解的数组,双指针一定能遍历到最优解。证明方法如下:假设最 优解的两个数的位置分别是l和r。我们假设在左指针在l左边的时候,右指针已经移动到了r; 此时两个指针指向值的和小于给定值,因此左指针会一直右移直到到达l。同理,如果我们假设 在右指针在r右边的时候,左指针已经移动到了l;此时两个指针指向值的和大于给定值,因此 右指针会一直左移直到到达r。所以双指针在任何时候都不可能处于l,r之间,又因为不满足条 件时指针必须移动一个,所以最终一定会收敛在l和r。1
2
3
4
5
6
7
8
9
10
11
12
13std::vector<int> twoSum(std::vector<int> &numbers, int target) {
int i = 0, j = numbers.size() - 1;
while (i < j) {
if (numbers[i] + numbers[j] < target) {
i++;
} else if (numbers[i] + numbers[j] > target) {
j--;
} else {
return {i+1, j+1};
}
}
return {};
}
88 归并有序数组
因为这两个数组已经排好序,我们可以把两个指针分别放在两个数组的末尾,即 nums1 的 m − 1 位和 nums2 的 n − 1 位。每次将较大的那个数字复制到 nums1 的后边,然后向前移动一位。 因为我们也要定位 nums1 的末尾,所以我们还需要第三个指针,以便复制。
在以下的代码里,我们直接利用 m 和 n 当作两个数组的指针,再额外创立一个 pos 指针,起始位置为 m +n − 1。每次向左移动 m 或 n 的时候,也要向左移动 pos。这里需要注意,如果 nums1 的数字已经复制完,不要忘记把 nums2 的数字继续复制;如果 nums2 的数字已经复制完,剩余 nums1 的数字不需要改变,因为它们已经被排好序。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19void merge(std::vector<int> &nums1, int m, std::vector<int> &nums2, int n) {
int pos = m + n - 1; // 指向最后一个位置
// 将最大的元素往后放
while (m > 0 && n > 0) {
if (nums1[m - 1] > nums2[n - 1]) {
nums1[pos] = nums1[m - 1];
// 指针后移
m--;
} else {
nums1[pos] = nums2[n - 1];
n--;
}
pos--;
}
while (n) {
nums1[pos--] = nums2[n--];
}
}
二分查找
二分查找也常被称为二分法或者折半查找 ,每次查找时通过将待查找的单调区间分成两部分并只取一部分继续查找,将查找的复杂度大大减少。对于一个长度为On 的数组,二分查找的时间复杂度为Ologn。
具体到代码上,二分查找时区间的左右端取开区间还是闭区间在绝大多数时候都可以,因此 有些初学者会容易搞不清楚如何定义区间开闭性。这里笔者提供两个小诀窍,第一是尝试熟练使用一种写法,比如左闭右开(满足、等语言的习惯)或左闭右闭(便于处理边界条 件),尽量只保持这一种写法;第二是在刷题时思考如果最后区间只剩下一个数或者两个数,自 己的写法是否会陷入死循环,如果某种写法无法跳出死循环,则考虑尝试另一种写法。
此外在更新left和right时,使用left=mid+1还是left=mid有差别,如果是前者,在下一次更新mid时仍有可能为mid(下一轮循环仍可能考虑 mid 这个位置的值)
旋转数组查找数字
1 | /* |
查找峰值
1 | /* |
排序算法
虽然在和里都可以通过sort函数排序,而且刷题时很少需要自己手写排序算 法,但是熟习各种排序算法可以加深自己对算法的基本理解,以及解出由这些排序算法引申出来 的题目。这里我们展示两种复杂度为Onlogn的排序算法:快速排序和归并排序,其中前者实 际速度较快,后者可以保证相同值的元素在数组中的相对位置不变(即“稳定排序”)
快速排序
快速排序的原理并不复杂:对于当前一个未排序片段,我们先随机选择一个位置当作中枢点, 然后通过遍历操作,将所有比中枢点小的数字移动到其左侧,再将所有比中枢点大的数字移动到 其右侧。操作完成后,我们再次对中枢点左右侧的片段再次进行快速排序即可。可证明,如果中 枢点选取是随机的,那么该算法的平均复杂度可以达到Onlogn,最差情况下复杂度则为On2。 我们采用左闭右闭的二分写法,初始化条件为l=0,r=n 1。
归并排序
归并排序是典型的分治法,简单来讲,对于一个未排序片段, 我们可以先分别排序其左半侧和右半侧,然后将两侧重新组合(“治”);排序每个半侧时可以通 过递归再次把它切分成两侧(“分”)。 我们采用左闭右闭的二分写法,初始化条件为l=0,r =n 1,另外提前建立一个和 大小相同的数组,用来存储临时结果。
| 排序算法 | 最好时间复杂度 | 最坏时间复杂度 | 平均时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n) | O(n²) | O(n²) | O(1) | 是 |
| 插入排序 | O(n) | O(n²) | O(n²) | O(1) | 是 |
| 选择排序 | O(n²) | O(n²) | O(n²) | O(1) | 否 |
| 希尔排序 | O(n) | O(n²) | O(nlogn)~O(n²) | O(1) | 否 |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 是 |
| 快速排序 | O(nlogn) | O(n²) | O(nlogn) | O(logn) | 否 |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 否 |
| 计数排序 | O(n+k) | O(n+k) | O(n+k) | O(k) | 是 |
| 桶排序 | O(n+k) | O(n²) | O(n+k) | O(n+k) | 是 |
| 基数排序 | O(n×k) | O(n×k) | O(n×k) | O(n+k) | 是 |
说明:
- 稳定性:稳定的排序算法在排序过程中不会改变相等元素的相对顺序。
- 空间复杂度:表示算法在运行过程中所需的额外空间。
- 计数排序、桶排序、基数排序:适用于数据范围有限或特定场景,能达到线性时间复杂度。
快速选择
在一个未排序的数组中,找到第k大的数字。
快速选择一般用于求解k-th Element 问题,可以在平均On时间复杂度,O1空间复杂度完 成求解工作。快速选择的实现和快速排序相似,不过只需要找到第k大的枢即可,不需 要对其左右再进行排序。与快速排序一样,快速选择一般需要先打乱数组,否则最坏情况下时间 复杂度为On2。
桶排序
给定一个数组,求前k个最频繁的数字。
搜索
深度优先搜索和广度优先搜索是两种最常见的优先搜索方法,它们被广泛地运用在图和树等 结构中进行搜索。
深度优先搜索在搜索到一个新的节点时,立即对该新节点进行遍 历;因此遍历需要用先入后出的栈()来实现,也可以通过与栈等价的递归来实现。对于树 结构而言,由于总是对新节点调用遍历,因此看起来是向着“深”的方向前进。
深度优先搜索也可以用来检测环路:记录每个遍历过的节点的父节点,若一个节点被再次遍 历且父节点不同,则说明有环。我们也可以用之后会讲到的拓扑排序判断是否有环路,若最后存 在入度不为零的点,则说明有环。
最大岛屿面积
给定一个二维的矩阵,其中表示海洋,表示陆地。单独的或相邻的陆地可以形成岛 屿,每个格子只与其上下左右四个格子相邻。求最大的岛屿面积。
城市数量
给定一个二维的矩阵,如果第位置是,则表示第个城市和第个城市处于同一 城市圈。已知城市的相邻关系是可以传递的,即如果a和b相邻,b和c相邻,那么a和c也相 邻,换言之这三个城市处于同一个城市圈之内。求一共有多少个城市圈。
太平洋大西洋水流问题
给定一个二维的非负整数矩阵,每个位置的值表示海拔高度。假设左边和上边是太平洋,右 边和下边是大西洋,求从哪些位置向下流水,可以流到太平洋和大西洋。水只能从海拔高的位置 流到海拔低或相同的位置。
回溯法
回溯法是优先搜索的一种特殊情况,又称为试探法,常用于需要记录节点状 态的深度优先搜索。通常来说,排列、组合、选择类问题使用回溯法比较方便
。 顾名思义,回溯法的核心是回溯。在搜索到某一节点的时候,如果我们发现目前的节点(及 其子节点)并不是需求目标时,我们回退到原来的节点继续搜索,并且把在目前节点修改的状态 还原。这样的好处是我们可以始终只对图的总状态进行修改,而非每次遍历时新建一个图来储存 状态。
在具体的写法上,它与普通的深度优先搜索一样,都有修改当前节点状态递归子节 点的步骤,只是多了回溯的步骤,变成了修改[当前节点状态]->[递归子节点]->[回改当前节点状态]。
可以记住两个小诀窍,一是按引用传状态,二是所有的状态修 改在递归完成后回改。 回溯法修改一般有两种情况,一种是修改最后一位输出,比如排列组合;一种是修改访问标 记,比如矩阵里搜字符串。
全排列
给定一个无重复数字的整数数组,求其所有的排列方式。
组合
给定一个整数n和一个整数k,求在到n中选取k个数字的所有组合方法。
单词搜索
给定一个字母矩阵,所有的字母都与上下左右四个方向上的字母相连。给定一个字符串,求 字符串能不能在字母矩阵中寻找到。
K皇后
给定一个大小为n的正方形国际象棋棋盘,求有多少种方式可以放置n个皇后并使得她们互 不攻击,即每一行、列、左斜、右斜最多只有一个皇后。
广度优先搜索
广度优先搜索( 此需要用先入先出的队列 ,)不同与深度优先搜索,它是一层层进行遍历的,因 而非先入后出的栈 进行遍历。由于是按层次进行遍历, 广度优先搜索时按照“广”的方向进行遍历的,也常常用来处理最短路径等问题。
这里要注意,深度优先搜索和广度优先搜索都可以处理可达性问题,即从一个节点开始是否 能达到另一个节点。因为深度优先搜索可以利用递归快速实现,很多人会习惯使用深度优先搜索 刷此类题目。实际软件工程中,笔者很少见到递归的写法,因为一方面难以理解,另一方面可能 产生栈溢出的情况;而用栈实现的深度优先搜索和用队列实现的广度优先搜索在写法上并没有太 大差异,因此使用哪一种搜索方式需要根据实际的功能需求来判断。另外,如果需要自定义搜索 优先级,我们可以利用优先队列,这个我们会在数据结构的章节讲到。—leetcode101
动态规划
动态规划在查找有很多 重叠子问题的情况的最优解时有效。它将问题重新组合成子问题。为了避免多次解决这些子问 题,它们的结果都逐渐被计算并被保存,从简单的问题直到整个问题都被解决。因此,动态规划 保存递归时的结果,因而不会在解决同样的问题时花费时间 动态规划只能应用于有最优 子结构的问题。最优子结构的意思是局部最优解能决定全局最优解(对有些问题这个要求并不能 完全满足,故有时需要引入一定的近似)。简单地说,问题能够分解成子问题来解决
动态规划和其它遍历算法(如深广度优先搜索)都是将原问题拆成多个子问 题然后求解,他们之间最本质的区别是,动态规划保存子问题的解,避免重复计算。解决动态规 划问题的关键是找到状态转移方程,这样我们可以通过计算和储存子问题的解来求解最终问题。
同时,也可以对动态规划进行空间压缩,起到节省空间消耗的效果。
在一些情况下,动态规划可以看成是带有状态记录( )的优先搜索。状态记录的 意思为,如果一个子问题在优先搜索时已经计算过一次,我们可以把它的结果储存下来,之后遍 历到该子问题的时候可以直接返回储存的结果。
动态规划是自下而上的,即先解决子问题,再解 决父问题;而用带有状态记录的优先搜索是自上而下的,即从父问题搜索到子问题,若重复搜索 到同一个子问题则进行状态记录,防止重复计算。如果题目需求的是最终状态,那么使用动态搜 索比较方便;如果题目需要输出所有的路径,那么使用带有状态记录的优先搜索会比较方便
一维
给定n节台阶,每次可以走一步或走两步,求一共有多少种方式可以走完这些台阶。
假如你是一个劫匪,并且决定抢劫一条街上的房子,每个房子内的钱财数量各不相同。如果 你抢了两栋相邻的房子,则会触发警报机关。求在不触发机关的情况下最多可以抢劫多少钱。
给定一个数组,求这个数组中连续且等差的子数组一共有多少个
二维
给定一个m n大小的非负整数矩阵,求从左上角开始到右下角结束的、经过的数字的和最 小的路径。每次只能向右或者向下移动。
给定一个由和组成的二维矩阵,求每个位置到最近的的距离。
在一个由 '0' 和 '1' 组成的二维矩阵内,找到只包含 '1' 的最大正方形,并返回其面积
分割类型
给定一个正整数,求其最少可以由几个完全平方数相加构成
已知字母可以表示成数字。给定一个数字串,求有多少种不同的字符串等价于这个 数字串
给定一个字符串和一个字符串集合,求是否存在一种分割方式,使得原字符串分割后的子字 符串都可以在集合内找到。
给定一个数组,每个元素代表一本书的厚度和高度。问对于一个固定宽度的书架,如果按照 数组中书的顺序从左到右、从上到下摆放,最小总高度是多少。
给定一个不重复数字的数组和一个目标数,求加起来是目标数的所有排列的总数量
子序列问题
对于子序列问题,第一种动态规划方法是,定义一个数组,其中dp[i]表示以i结尾的子 序列的性质。在处理好每个位置后,统计一遍各个位置的结果即可得到题目要求的结果。
对于子序列问题,第二种动态规划方法是,定义一个数组,其中表示dp[i]到位置i为止的子序列的性质,并不必须以结尾。这样数组的最后一位结果即为题目所求,不需要再对每 个位置进行统计。
背包问题
背包问题是一种组合优化的完全问题:有n个物品和载重为w的背包和价值,求拿哪些物品可以使得背包所装下物品的总价值最大。如果限定每种物品只能选择0个或1个,则问题称为背包问题( 如果不限定每种物品的数量,则问题称为无界背包问题或完全背包问题)
给定一个正整数数组,求是否可以把这个数组分成和相等的两部分
给定一些硬币的面额,求最少可以用多少颗硬币组成给定的金额。
给定m个数字和n个数字,以及一些由构成的字符串,求利用这些数字最多可以构 成多少个给定的字符串,字符串只可以构成一次。
字符串编辑
给定两个字符串,已知你可以删除、替换和插入任意字符串的任意字符,求最少编辑几步可 以将两个字符串变成相同。
给定一个字母,已知你可以每次选择复制全部字符,或者粘贴之前复制的字符,求最少需 要几次操作可以把字符串延展到指定长度。
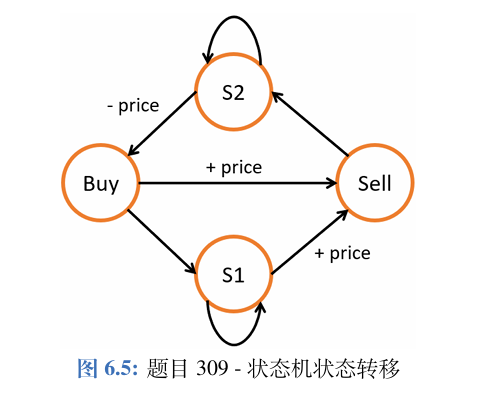
股票交易
股票交易类问题通常可以用动态规划来解决。对于稍微复杂一些的股票交易类问题,比如需要冷却时间或者交易费用,则可以用通过动态规划实现的状态机来解决。
给定一段时间内每天某只股票的固定价格,已知你只可以买卖各k次,且每次只能拥有一支 股票,求最大的收益。
给定一段时间内每天某只股票的固定价格,已知每次卖出之后必须冷却一天,且每次只能拥 有一支股票,求最大的收益。
分治法
顾名思义,分治问题由“分”()和“治”( 表达式问题 )两部分组成,通过把原问题分为子 问题,再将子问题进行处理合并,从而实现对原问题的求解。我们在排序章节展示的归并排序就 是典型的分治问题,其中“分”即为把大数组平均分成两个小数组,通过递归实现,最终我们会 得到多个长度为的子数组“治”即为把已经排好序的两个小数组合成为一个排好序的大数组, 从长度为的子数组开始,最终合成一个大数组
另外,自上而下的分治可以和memoization 结合,避免重复遍历相同的子问题。如果方便推 导,也可以换用自下而上的动态规划方法求解
树
作为(单)链表的升级版,我们通常接触的树都是二叉树, 两个子节点;且除非题目说明,默认树中不存在循环结构。
树的递归
在很多时候,树递归的写法与深度优先搜索的递归写法相同
层次遍历
我们可以使用广度优先搜索进行层次遍历。注意,不需要使用两个队列来分别存储当前层的 节点和下一层的节点,因为在开始遍历一层的节点时,当前队列中的节点数就是当前层的节点 数,只要控制遍历这么多节点数,就能保证这次遍历的都是当前层的节点。
广度优先搜索 BFS(队列) 层序遍历、最短路径
前中后序遍历
前序遍历、中序遍历和后序遍历是三种利用深度优先搜索遍历二叉树的方式。它们是在对节 点访问的顺序有一点不同,其它完全相同。
前序遍历先遍历父结点,再遍历左结点,最后遍历右节点
中序遍历先遍历左节点,再遍历父结点,最后遍历右节点
后序遍历先遍历左节点,再遍历右结点,最后遍历父节点
| 类别 | 技术名称 | 适用场景 |
|---|---|---|
| 递归遍历 | 前中后序、分治法 | 查找、修改、统计 |
| 迭代遍历 | 栈、队列模拟 | 非递归遍历、层序 |
| 深度优先搜索 | DFS(递归/栈) | 路径、计算、构造 |
| 广度优先搜索 | BFS(队列) | 层序遍历、最短路径 |
| 动态规划 | 树形DP(子问题依赖) | 子树结构最优解 |
| 二叉搜索树性质 | 有序性、剪枝 | 查找区间、最近公共祖先 |
| Morris 遍历 | O(1) 空间中序遍历 | 面试高频,省空间遍历 |
数学问题
公倍数与公因数
质数
数字处理
Base7
给定一个十进制整数,求它在七进制下的表示。
Factorial Trailing Zeroes
给定一个非负整数,判断它的阶乘结果的结尾有几个 0。1
2
3
4
5
6
7
8int trailingZeroes(int n) {
int count = 0;
while (n > 0) {
n /= 5;
count += n;
}
return count;
}
字符串相加
给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和并同样以字符串形式返回。
你不能使用任何內建的用于处理大整数的库(比如 BigInteger), 也不能直接将输入的字符串转换为整数形式。
随机取样
打乱数组
给定一个数组,要求实现两个指令函数。第一个函数“shuffle”可以随机打乱这个数组,第二个函数“reset”可以恢复原来的顺序。打乱后,数组的所有排列应该是 等可能 的。
主要是洗牌时存在正向洗牌和反向洗牌。
采用经典的
Fisher-Yates 洗牌算法,原理是通过随机交换位置来实现随机打乱,有正向和反向两种写法
正向洗牌就是对每个位置i,随机生成[0,n-i)的值pos,交换i与i+pos,使得所有交换都是随机的
反向洗牌是从后向前,对于每个位置i,生成从[0,i]的值pos,交换i与pos.
按权重随机选择
给你一个 下标从 0 开始 的正整数数组 w ,其中 w[i] 代表第 i 个下标的权重。
请你实现一个函数 pickIndex ,它可以 随机地 从范围 [0, w.length - 1] 内(含 0 和 w.length - 1)选出并返回一个下标。选取下标 i 的 概率 为 w[i] / sum(w)
先使用 partial_sum求前缀和(即到每个位置为止之前所有数字的和),这个结果对于正整数数组是单调递增的。每当需要采样时,我们可以先随机产生一个数字,然后使用二分法查找其在前缀和中的位置,以模拟加权采样的过程。这里的二分法可以用 lower_bound 实现。
链表随机节点
给你一个单链表,随机选择链表的一个节点,并返回相应的节点值。每个节点 被选中的概率一样 。
水库算法: 水库算法(Reservoir Sampling) 是一种经典的在线(在线流式)随机采样算法,用于从未知或过大长度的输入流中等概率地随机采样 k 个元素,而不需要事先知道数据总量,也无需将所有数据存入内存。
- 数据量太大,不能一次性全部加载到内存中(如海量日志、传感器数据、数据库行);
- 你想从中随机选出一个或多个元素(等概率);
- 数据是流式输入,你无法提前知道数据总量。
遍历一次链表,在遍历到第 m 个节点时,有$\frac{1}{m}$的概率选择这个节点覆盖掉之前的节点选择。
位运算
利用二进制的一些特性,我们可以把位运算使用到更多问题上。
例如,我们可以利用二进制和位运算输出一个数组的所有子集。假设我们有一个长度为 n的数组,我们可以生成长度为 n 的所有二进制,1 表示选取该数字,0 表示不选取。这样我们就获得了 2^n^个子集。
最大单词长度乘积
给你一个字符串数组 words ,找出并返回 length(words[i]) * length(words[j]) 的最大值,并且这两个单词不含有公共字母。如果不存在这样的两个单词,返回 0
比特位计数
给定一个非负整数 n,求从 0 到 n 的所有数字的二进制表达中,分别有多少个 1。
本题可以利用动态规划和位运算进行快速的求解。定义一个数组 dp,其中 dp[i] 表示数字 i 的二进制含有 1 的个数。对于第 i 个数字,如果它二进制的最后一位为 1,那么它含有 1 的个数则为 dp[i-1] + 1;如果它二进制的最后一位为 0,那么它含有 1 的个数和其算术右移结果相同,即 dp[i>>1]。
数据结构
在刷题时,我们几乎一定会用到各种数据结构来辅助我们解决问题,因此我们必须熟悉各种数据结构的特点。C++ STL 提供的数据结构包括(实际底层细节可能因编译器而异):
- Sequence Containers:维持顺序的容器。
- vector:
动态数组,是我们最常使用的数据结构之一,用于 O(1) 的随机读取。因为大部分算法的时间复杂度都会大于O(n),因此我们经常新建 vector 来存储各种数据或中间变量。因为在尾部增删的复杂度是 O(1),我们也可以把它当作 stack 来用。 - list:
双向链表,也可以当作 stack 和 queue 来使用。由于 LeetCode 的题目多用 Node 来表示链表,且链表不支持快速随机读取,因此我们很少用到这个数据结构。一个例外是经典的 LRU 问题,我们需要利用链表的特性来解决,我们在后文会遇到这个问题。 - deque:双端队列,这是一个非常强大的数据结构,既支持 O(1) 随机读取,又支持 O(1) 时间的头部增删和尾部增删(因此可以当作 stack 和 queue 来使用),不过有一定的额外开销。也可以用来近似一个双向链表来使用。
- array:固定大小的数组,一般在刷题时我们不使用。
- forward_list:单向链表,一般在刷题时我们不使用。
- vector:
- Container Adaptors:基于其它容器实现的容器。
- stack:
后入先出(LIFO)的数据结构,默认基于 deque 实现。stack 常用于深度优先搜索、一些字符串匹配问题以及单调栈问题。 - queue:
先入先出(FIFO)的数据结构,默认基于 deque 实现。queue 常用于广度优先搜索。 - priority_queue:
优先队列(最大值先出的数据结构),默认基于 vector 实现堆结构。它可以在 O(nlogn)O(nlogn) 的时间排序数组,O(logn) 的时间插入任意值,O(1)的时间获得最大值,O(logn)O(logn) 的时间删除最大值。priority_queue 常用于维护数据结构并快速获取最大值,并且可以自定义比较函数;比如通过存储负值或者更改比小函数为比大函数,即可实现最小值先出。
- stack:
- Ordered Associative Containers:有序关联容器。
- set:有序集合,元素不可重复,底层实现默认为红黑树,即一种特殊的二叉查找树(BST)。它可以在 O(nlogn)O(nlogn) 的时间排序数组,O(logn)O(logn) 的时间插入、删除、查找任意值,O(logn)O(logn) 的时间获得最小或最大值。这里注意,set 和 priority_queue 都可以用于维护数据结构并快速获取最大最小值,但是它们的时间复杂度和功能略有区别,如 priority_queue 默认不支持删除任意值,而 set 获得最大或最小值的时间复杂度略高,具体使用哪个根据需求而定。
- multiset:支持重复元素的 set。
- map:
有序映射或有序表,在 set 的基础上加上映射关系,可以对每个元素 key 存一个值 value。 - multimap:支持重复元素的 map。
- Unordered Associative Containers:无序关联容器。
- unordered_set:
哈希集合,可以在O(1) 的时间快速插入、查找、删除元素,常用于快速的查询一个元素是否在这个容器内。 - unordered_multiset:支持重复元素的 unordered_set。
- unordered_map:
哈希映射或哈希表,在 unordered_set 的基础上加上映射关系,可以对每一个元素 key 存一个值 value。在某些情况下,如果 key 的范围已知且较小,我们也可以用 vector 代替 unordered_map,用位置表示 key,用每个位置的值表示 value。 - unordered_multimap:支持重复元素的 unordered_map
- unordered_set:
数组
找到所有数组中消失的数字
给你一个含 n 个整数的数组 nums ,其中 nums[i] 在区间 [1, n] 内。请你找出所有在 [1, n] 范围内但没有出现在 nums 中的数字,并以数组的形式返回结果。
利用数组这种数据结构建立 n 个桶,把所有重复出现的位置进行标记,然后再遍历一遍数组,即可找到没有出现过的数字。进一步地,我们可以直接对原数组进行标记:把重复出现的数字-1在原数组的位置设为负数(这里-1 的目的是把 1 到 n 的数字映射到 0 到 n-1 的位置),最后仍然为正数的位置 +1 即为没有出现过的数。
旋转图像
给定一个 n × n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。
可以先对角线旋转再水平翻转.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
void rotate(std::vector<std::vector<int>>& matrix) {
int n = matrix.size();
// 1. 转置:对角线翻转
for (int i = 0; i < n; ++i) {
for (int j = i + 1; j < n; ++j) {
std::swap(matrix[i][j], matrix[j][i]);
}
}
// 2. 每行翻转(水平翻转)
for (int i = 0; i < n; ++i) {
std::reverse(matrix[i].begin(), matrix[i].end());
}
}
769最多能完成排序的块
给定一个长度为 n 的整数数组 arr ,它表示在 [0, n - 1] 范围内的整数的排列。
我们将 arr 分割成若干 块 (即分区),并对每个块单独排序。将它们连接起来后,使得连接的结果和按升序排序后的原数组相同。
返回数组能分成的最多块数量。
栈与队列
232 使用栈实现队列
可以用两个栈来实现一个队列:因为我们需要得到先入先出的结果,所以必定要通过一个额外栈翻转一次数组。这个翻转过程既可以在插入时完成,也可以在取值时完成。我们这里展示在取值时完成的写法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34class MyQueue {
public:
MyQueue() {}
void push(int x) { s_in_.push(x); }
int pop() {
in2out();
int x = s_out_.top();
s_out_.pop();
return x;
}
int peek() {
in2out();
return s_out_.top();
}
bool empty() { return s_in_.empty() && s_out_.empty(); }
private:
void in2out() {
if (!s_out_.empty()) {
return;
}
while (!s_in_.empty()) {
int x = s_in_.top();
s_in_.pop();
s_out_.push(x);
}
}
stack<int> s_in_, s_out_;
};
155 最小栈
设计一个最小栈,除了需要支持常规栈的操作外,还需要支持在 O(1) 时间内查询栈内最小值的功能。
可以额外建立一个新栈,栈顶表示原栈里所有值的最小值。每当在原栈里插入一个数字时,若该数字小于等于新栈栈顶,则表示这个数字在原栈里是最小值,我们将其同时插入新栈内。每当从原栈里取出一个数字时,若该数字等于新栈栈顶,则表示这个数是原栈里的最小值之一,我们同时取出新栈栈顶的值。
一个写起来更简单但是时间复杂度略高的方法是,我们每次插入原栈时,都向新栈插入一次原栈里所有值的最小值(新栈栈顶和待插入值中小的那一个);每次从原栈里取出数字时,同样取出新栈的栈顶。这样可以避免判断,但是每次都要插入和取出。我们这里只展示第一种写法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49/*
* @lc app=leetcode.cn id=155 lang=cpp
*
* [155] 最小栈
*/
using namespace std;
// @lc code=start
class MinStack {
private:
stack<int> _nums;
stack<int> _minNums;
public:
MinStack() {}
void push(int val) {
_nums.push(val);
if (_minNums.empty() || val <= _minNums.top()) {
_minNums.push(val);
}
}
void pop() {
auto n = _nums.top();
_nums.pop();
if (!_minNums.empty() && _minNums.top() == n) {
_minNums.pop();
}
}
int top() { return _nums.top(); }
int getMin() { return _minNums.top(); }
};
/**
* Your MinStack object will be instantiated and called as such:
* MinStack* obj = new MinStack();
* obj->push(val);
* obj->pop();
* int param_3 = obj->top();
* int param_4 = obj->getMin();
*/
// @lc code=end
20 有效的括号
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 每个右括号都有一个对应的相同类型的左括号。
739 每日温度
单调栈通过维持栈内值的单调递增(递减)性,在整体 O(n) 的时间内处理需要大小比较的问题。
给定每天的温度,求对于每一天需要等几天才可以等到更暖和的一天。如果该天之后不存在更暖和的天气,则记为 0。
输入是一个一维整数数组,输出是同样长度的整数数组,表示对于每天需要等待多少天。
可以维持一个单调递减的栈,表示每天的温度;为了方便计算天数差,我们这里存放位置(即日期)而非温度本身。我们从左向右遍历温度数组,对于每个日期 p,如果 p 的温度比栈顶存储位置 q 的温度高,则我们取出 q,并记录 q 需要等待的天数为 p − q;我们重复这一过程,直到 p 的温度小于等于栈顶存储位置的温度(或空栈)时,我们将 p 插入栈顶,然后考虑下一天。在这个过程中,栈内数组永远保持单调递减,避免了使用排序进行比较。最后若栈内剩余一些日期,则说明它们之后都没有出现更暖和的日期。
优先队列
优先队列(priority queue)可以在 O(1)O(1) 时间内获得最大值,并且可以在 O(log n) 时间内取出最大值或插入任意值。
优先队列常常用堆(heap)来实现。堆是一个完全二叉树,其每个节点的值总是大于等于子节点的值。实际实现堆时,我们通常用一个数组而不是用指针建立一个树。这是因为堆是完全二叉树,所以用数组表示时,位置 i 的节点的父节点位置一定为 (i-1)/2,而它的两个子节点的位置又一定分别为 2i+1 和 2i+2。
满二叉树 (Full Binary Tree): 所有叶子节点都在同一层,并且每个非叶子节点都有两个子节点。满二叉树一定是完全二叉树。
完全二叉树是在满足以下两个条件的情况下,对满二叉树概念的一种放宽:
- 除最后一层外,所有层都是完全充满的。
- 最后一层的节点都集中在最左边。
这意味着:
- 如果一棵完全二叉树的深度为
d,那么在d-1层之前的每层(从第 1 层到第d-1层)都必须达到最大节点数(即 2^(层数−1) 个节点)。 - 在最后一层(第
d层),节点可以不完全充满。但是,所有存在的节点都必须尽可能地靠左排列,不能出现中间有空缺的情况。换句话说,如果从左往右给最后一层的节点编号,那么所有编号小于等于实际节点总数的节点都必须存在,且不能有编号大于实际节点总数的节点。
实现最大堆,核心是实现上浮和下沉操作1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45class Heap {
public:
Heap() {}
// 上浮。
void swim(int pos) {
int next_pos = (pos - 1) / 2;
while (pos > 0 && heap_[next_pos] < heap_[pos]) {
swap(heap_[next_pos], heap_[pos]);
pos = next_pos;
next_pos = (pos - 1) / 2;
}
}
// 下沉。
void sink(int pos) {
int n = heap_.size();
int next_pos = 2 * pos + 1;
while (next_pos < n) {
if (next_pos < n - 1 && heap_[next_pos] < heap_[next_pos + 1]) {
++next_pos;
}
if (heap_[pos] >= heap_[next_pos]) {
break;
}
swap(heap_[next_pos], heap_[pos]);
pos = next_pos;
next_pos = 2 * pos + 1;
}
}
// 插入任意值:把新的数字放在最后一位,然后上浮。
void push(int k) {
heap_.push_back(k);
swim(heap_.size() - 1);
}
// 删除最大值:把最后一个数字挪到开头,然后下沉。
void pop() {
heap_[0] = heap_.back();
heap_.pop_back();
sink(0);
}
// 获得最大值。
int top() { return heap_[0]; }
private:
vector<int> heap_;
};
23 merge k sorted lists
给定 k 个增序的链表,试将它们合并成一条增序链表。
输入是一个一维数组,每个位置存储链表的头节点;输出是一条链表。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19ListNode* mergeKLists(vector<ListNode*>& lists) {
auto comp = [](ListNode* l1, ListNode* l2) { return l1->val > l2->val; };
priority_queue<ListNode*, vector<ListNode*>, decltype(comp)> pq;
for (ListNode* l : lists) {
if (l) {
pq.push(l);
}
}
ListNode *dummy = new ListNode(0), *cur = dummy;
while (!pq.empty()) {
cur->next = pq.top();
pq.pop();
cur = cur->next;
if (cur->next) {
pq.push(cur->next);
}
}
return dummy->next;
}
双端队列
滑动窗口最大值
给定一个整数数组和一个滑动窗口大小,求在这个窗口的滑动过程中,每个时刻其包含的最大值。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37/*
* @lc app=leetcode.cn id=239 lang=cpp
*
* [239] 滑动窗口最大值
*/
// @lc code=start
#include <algorithm>
#include <list>
#include <vector>
using namespace std;
class Solution {
public:
vector<int> maxSlidingWindow(vector<int> &nums, int k) {
list<int> r;
vector<int> result;
for (int i = 0; i < nums.size() ; ++i) {
// 如果被排除的索引等于双端队列最左端值
if (!r.empty() && i - k == r.front()) {
r.pop_front();
}
// 如果元素大于双端队列最右端对应索引的值
while (!r.empty() && nums.at(i) > nums.at(r.back())) {
r.pop_back();
}
r.push_back(i);
if (i >= k - 1) {
result.push_back(nums.at(r.front()));
}
}
return result;
}
};
// @lc code=end
哈希表
149 最长连续序列
给定一个整数数组,求这个数组中的数字可以组成的最长连续序列有多长。
输入一个整数数组,输出一个整数,表示连续序列的长度。1
2Input: [100, 4, 200, 1, 3, 2]
Output: 4
在这个样例中,最长连续序列是 [1,2,3,4]。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17int longestConsecutive(vector<int>& nums) {
unordered_set<int> cache(nums.begin(), nums.end());
int max_len = 0;
while (!cache.empty()) {
int cur = *(cache.begin());
cache.erase(cur);
int l = cur - 1, r = cur + 1;
while (cache.contains(l)) {
cache.erase(l--);
}
while (cache.contains(r)) {
cache.erase(r++);
}
max_len = max(max_len, r - l - 1);
}
return max_len;
}
线上最多有多少点
给定一些二维坐标中的点,求同一条线上最多有多少点。
对于每个点,我们对其它点建立哈希表,统计同一斜率的点一共有多少个。这里利用的原理是,一条线可以由一个点和斜率而唯一确定。另外也要考虑斜率不存在和重复坐标的情况。
本题也利用了一个小技巧:在遍历每个点时,对于数组中位置 i 的点,我们只需要考虑 i 之后的点即可,因为 i 之前的点已经考虑过 i 了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24int maxPoints(vector<vector<int>>& points) {
int max_count = 0, n = points.size();
for (int i = 0; i < n; ++i) {
unordered_map<double, int> cache; // <斜率, 点个数>
int same_xy = 1, same_y = 1;
for (int j = i + 1; j < n; ++j) {
if (points[i][1] == points[j][1]) {
++same_y;
if (points[i][0] == points[j][0]) {
++same_xy;
}
} else {
double dx = points[i][0] - points[j][0],
dy = points[i][1] - points[j][1];
++cache[dx / dy];
}
}
max_count = max(max_count, same_y);
for (auto item : cache) {
max_count = max(max_count, same_xy + item.second);
}
}
return max_count;
}
多重映射
给你一份航线列表 tickets ,其中 tickets[i] = [fromi, toi] 表示飞机出发和降落的机场地点。请你对该行程进行重新规划排序。
所有这些机票都属于一个从 JFK(肯尼迪国际机场)出发的先生,所以该行程必须从 JFK 开始。如果存在多种有效的行程,请你按字典排序返回最小的行程组合。
- 例如,行程
["JFK", "LGA"]与["JFK", "LGB"]相比就更小,排序更靠前。
假定所有机票至少存在一种合理的行程。且所有的机票 必须都用一次 且 只能用一次。
本题可以先用哈希表记录起止机场,其中键是起始机场,值是一个多重(有序)集合,表示对应的终止机场。因为一个人可能坐过重复的线路,所以我们需要使用多重集合储存重复值。储存完成之后,我们可以利用栈/DFS 来恢复从终点到起点飞行的顺序,再将结果逆序得到从起点到终点的顺序。
因为 Python 没有默认的多重(有序)集合实现,我们可以直接存储一个数组,然后进行排序。也可以使用 Counter 结构,每次查找下一个机场时,返回 key 值最小的那个。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45/*
* @lc app=leetcode.cn id=332 lang=cpp
*
* [332] 重新安排行程
*/
// @lc code=start
using namespace std;
class Solution {
public:
vector<string> findItinerary(vector<vector<string>> &tickets) {
unordered_map<string, multiset<string>> m_tickets;
// 建立多重映射
for (auto &tick : tickets) {
m_tickets[tick[0]].insert(tick[1]);
}
stack<string> s;
s.push("JFK");
vector<string> result;
while (!s.empty()) {
auto t = s.top();
if (m_tickets[t].empty()) {
// 到达最后一个点
result.push_back(t);
s.pop();
} else {
// 继续向下一个点
auto r = *m_tickets[t].begin();
s.push(r);
m_tickets[t].erase(m_tickets[t].begin());
}
}
reverse(result.begin(), result.end());
return result;
}
};
// @lc code=end
前缀二分和 二分图
304 2D范围和查询
设计一个数据结构,使得其能够快速查询给定矩阵中,任意两个位置包围的长方形中所有数字的和。
和为k的子数组
给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。
子数组是数组中元素的连续非空序列。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class Solution {
public:
int subarraySum(vector<int> &nums, int k) {
// 前缀和
unordered_map<int, int> prefixSum; // 前缀和与对应出现次数
int cursum = 0;
int count{};
prefixSum[0] = 1;
for(auto n:nums) {
cursum+=n;
count += prefixSum[cursum-k];
++prefixSum[cursum];
}
return count;
}
};
字符串
std::string 的常见操作
1. 创建和初始化
默认初始化: 创建一个空字符串。
1
std::string s1; // s1 是一个空字符串 ""
字面量初始化: 使用字符串字面量初始化。
1
2std::string s2 = "Hello";
std::string s3("World");拷贝初始化: 从另一个
std::string对象或 C 风格字符串拷贝。1
2
3std::string s4 = s2; // s4 是 "Hello"
std::string s5(s3); // s5 是 "World"
std::string s6("C-style string"); // 从 const char* 初始化重复字符初始化: 创建包含指定数量相同字符的字符串。
1
std::string s7(5, 'A'); // s7 是 "AAAAA"
子串初始化: 从另一个字符串的子串初始化。
1
2std::string s8 = "programming";
std::string s9(s8, 3, 4); // 从索引 3 开始,取 4 个字符,s9 是 "gram"
2. 访问字符
std::string 的字符可以通过多种方式访问,它们都提供了边界检查或者迭代器访问。
[]运算符: 像访问数组一样访问字符。不进行边界检查,越界访问会导致未定义行为。1
2
3
4std::string str = "example";
char c = str[0]; // c 是 'e'
str[1] = 'X'; // str 变为 "eXample"
// char invalid_c = str[100]; // 危险!越界访问at()方法: 通过索引访问字符,并提供边界检查。如果索引越界,会抛出std::out_of_range异常。1
2
3
4
5
6
7std::string str = "example";
char c = str.at(0); // c 是 'e'
try {
char invalid_c = str.at(100); // 抛出 std::out_of_range 异常
} catch (const std::out_of_range& e) {
std::cerr << "Error: " << e.what() << std::endl;
}front()/back()方法: 访问第一个和最后一个字符。1
2
3std::string str = "abc";
char first = str.front(); // 'a'
char last = str.back(); // 'c'迭代器: 使用迭代器遍历字符串。
1
2
3
4std::string str = "hello";
for (char ch : str) { // C++11 范围 for 循环
std::cout << ch << " ";
} // Output: h e l l o
3. 容量和大小
length()/size(): 返回字符串中字符的数量(不包括空终止符)。两者功能相同。1
2
3std::string s = "test";
size_t len = s.length(); // len 是 4
size_t sz = s.size(); // sz 也是 4empty(): 检查字符串是否为空。1
2
3
4std::string s1 = "";
std::string s2 = "abc";
bool b1 = s1.empty(); // true
bool b2 = s2.empty(); // falsecapacity(): 返回当前字符串能够存储的字符数量(不重新分配内存)。capacity()可能大于size()。reserve(n): 请求字符串预分配至少能容纳n个字符的内存空间。可以提高性能,避免频繁的重新分配。shrink_to_fit()(C++11): 请求减少字符串的容量以适应其当前大小。
4. 字符串修改
+=运算符 /append(): 在字符串末尾追加内容。1
2
3std::string s = "Hello";
s += " World!"; // s 是 "Hello World!"
s.append(" C++"); // s 是 "Hello World! C++"push_back()/pop_back()(C++11): 在末尾添加或移除单个字符。1
2
3std::string s = "abc";
s.push_back('d'); // s 是 "abcd"
s.pop_back(); // s 是 "abc"insert(): 在指定位置插入内容。1
2std::string s = "World";
s.insert(0, "Hello "); // s 是 "Hello World"erase(): 移除指定位置或范围的字符。1
2std::string s = "Hello World";
s.erase(5, 6); // 从索引 5 开始删除 6 个字符,s 变为 "Hello"replace(): 替换指定范围的字符。1
2std::string s = "Hello World";
s.replace(6, 5, "C++"); // 从索引 6 开始替换 5 个字符为 "C++",s 变为 "Hello C++"clear(): 清空字符串内容。1
2std::string s = "test";
s.clear(); // s 变为空字符串 ""
5. 查找和比较
find(): 查找子串或字符第一次出现的位置。返回std::string::npos表示未找到。1
2
3
4std::string s = "apple banana apple";
size_t pos1 = s.find("apple"); // pos1 是 0
size_t pos2 = s.find("orange"); // pos2 是 std::string::npos
size_t pos3 = s.find("apple", 1); // 从索引 1 开始查找,pos3 是 13rfind(): 查找子串或字符最后一次出现的位置。1
2std::string s = "apple banana apple";
size_t pos = s.rfind("apple"); // pos 是 13compare(): 比较两个字符串或子串。- 返回 0 表示相等。
- 返回负数表示当前字符串小于参数字符串。
- 返回正数表示当前字符串大于参数字符串。
1
2
3std::string s1 = "abc";
std::string s2 = "abd";
int result = s1.compare(s2); // result < 0==,!=,<,<=,>,>=运算符: 进行字典序比较。1
2
3std::string s1 = "apple";
std::string s2 = "banana";
bool b = (s1 < s2); // true
6. 转换为 C 风格字符串
c_str(): 返回指向字符串内部 C 风格空终止字符数组的指针。不要修改返回的指针指向的内容,也不要存储它,因为std::string对象内部数据可能重新分配。C++
1
2
3std::string s = "Hello C++";
const char* c_str = s.c_str(); // 可以用于需要 const char* 的 C 函数
std::cout << c_str << std::endl;data()(C++11): 返回指向字符串内部字符数组的指针。对于 C++11 之前的版本,data()不保证空终止,但 C++11 及更高版本保证。同样,不应修改其内容。
7. 子串提取
substr(): 提取字符串的子串。1
2
3std::string s = "Hello World";
std::string sub = s.substr(6, 5); // 从索引 6 开始,提取 5 个字符,sub 是 "World"
std::string rest = s.substr(6); // 从索引 6 到字符串末尾,rest 是 "World"
字符串比较
1249 移除无效括号
给定一个包括字母和左右括号的字符串,求最少要移除多少个括号才能使其合法。
输入是一个字符串,输出是合法且长度最长的移除结果。
因为只有一种括号,所以我们并不一定利用栈来统计,可以直接用一个临时变量统计在当前位置时,左括号比右括号多出现多少次。如果在遍历过程中出现负数,则需要移除多余的右括号。如果遍历结束时临时变量为正数,则需要从右到左移除多余的左括号。这里我们使用了一个小技巧,先标记待删除位置,最后一起移除。
字符串理解
227 基本计算器II
给定一个包含加减乘除整数运算的字符串,求其运算的整数值结果。如果除不尽则向 0 取整。
输入是一个合法的运算字符串,输出是一个整数,表示其运算结果。
如果我们在字符串左边加上一个加号,可以证明其并不改变运算结果,且字符串可以分割成多个 < 一个运算符,一个数字 > 对子的形式;这样一来我们就可以从左往右处理了。由于乘除的优先级高于加减,因此我们需要使用一个中间变量来存储高优先度的运算结果。
例如 1+23/4-3,变为+1+2\3/4-3 <+,1>,<+,2>,<*,3>…
此类型题也考察很多细节处理,如无运算符的情况,和多个空格的情况等等
链表
(单向)链表是由节点和指针构成的数据结构,每个节点存有一个值,和一个指向下一个节点的指针,因此很多链表问题可以用递归来处理。不同于数组,链表并不能直接获取任意节点的值,必须要通过指针找到该节点后才能获取其值。同理,在未遍历到链表结尾时,我们也无法知道链表的长度,除非依赖其他数据结构储存长度。LeetCode 默认的链表表示方法如下。
- C++
- Python
1 | struct ListNode { |
由于在进行链表操作时,尤其是删除节点时,经常会因为对当前节点进行操作而导致内存或指针出现问题。有两个小技巧可以解决这个问题:一是尽量处理当前节点的下一个节点而非当前节点本身,二是建立一个虚拟节点 (dummy node),使其指向当前链表的头节点,这样即使原链表所有节点全被删除,也会有一个 dummy 存在,返回 dummy->next 即可。
206 翻转链表
输入一个链表,输出该链表翻转后的结果。1
2Input: 1->2->3->4->5->nullptr
Output: 5->4->3->2->1->nullptr
链表翻转是非常基础也一定要掌握的技能。有两种写法——递归和非递归。建议同时掌握这两种写法。1
2
3
4
5
6
7
8
9
10
11
12
13
14class Solution {
public:
ListNode* reverseList(ListNode* head,ListNode* head_prev=nullptr) {
//递归写法
if(head == nullptr) {
return head_prev;
}
// 拿到下一个节点
ListNode* next = head->next;
// 节点指向上一个节点
head->next = head_prev;
return reverseList(next,head);
}
};1
2
3
4
5
6
7
8
9
10
11
12ListNode* reverseList(ListNode* head) {
//非递归写法
ListNode* prev = nullptr;
while(head) {
ListNode* next = head->next;
head->next = prev;
prev = head;
head = next;
}
return prev;
}
21 合并有序链表
给定两个增序的链表,试将其合并成一个增序的链表。
输入两个链表,输出一个链表,表示两个链表合并的结果。1
2Input: 1->2->4, 1->3->4
Output: 1->1->2->3->4->4
递归和非递归,共两种写法。递归的写法为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37/*
* @lc app=leetcode.cn id=21 lang=cpp
*
* [21] 合并两个有序链表
*/
// @lc code=start
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
// 递归写法
if(list1 == nullptr) {
return list2;
}
if(list2 == nullptr) {
return list1;
}
if(list1->val<list2->val) {
list1->next = mergeTwoLists(list1->next, list2);
return list1;
}
list2->next = mergeTwoLists(list1, list2->next);
return list2;
}
};
// @lc code=end1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23ListNode *mergeTwoLists(ListNode *list1, ListNode *list2) {
// 非递归写法
if (list1 == nullptr) {
return list2;
}
if (list2 == nullptr) {
return list1;
}
ListNode *root = new ListNode(0);
ListNode *cur = root;
while (list1 && list2) {
if (list1->val < list2->val) {
cur->next = list1;
list1 = list1->next;
} else {
cur->next = list2;
list2 = list2->next;
}
cur = cur->next;
}
cur->next = list1 ? list1 : list2;
return root->next;
}
24 两两交换链表中的节点
给定一个矩阵,交换每个相邻的一对节点。
输入一个链表,输出该链表交换后的结果。1
2Input: 1->2->3->4
Output: 2->1->4->3
利用指针进行交换操作,没有太大难度,但一定要细心。
160 相交链表
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
假设链表 A 的头节点到相交点的距离是 a,链表 B 的头节点到相交点的距离是 b,相交点到链表终点的距离为 c。我们使用两个指针,分别指向两个链表的头节点,并以相同的速度前进,若到达链表结尾,则移动到另一条链表的头节点继续前进。按照这种前进方法,两个指针会在 a + b + c 次前进后同时到达相交节点
234 回文链表
给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
先使用快慢指针找到链表中点,再把链表切成两半;然后把后半段翻转;最后比较两半是否相等。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56/*
* @lc app=leetcode.cn id=234 lang=cpp
*
* [234] 回文链表
*/
// @lc code=start
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode *reverse(ListNode *list) {
if (list == nullptr) {
return nullptr;
}
ListNode *head_prev = nullptr;
while (list) {
ListNode *head_next = list->next;
list->next = head_prev;
head_prev = list;
list = head_next;
}
return head_prev;
}
bool isPalindrome(ListNode *head) {
// 快慢指针找中点
if (head == nullptr || head->next == nullptr) {
return true;
}
ListNode* slowptr = head,*fastptr = head;
while(fastptr->next!=nullptr && fastptr->next->next!=nullptr) {
fastptr = fastptr->next->next;
slowptr = slowptr->next;
}
// 找到中点slowptr
slowptr->next = reverse(slowptr->next);
slowptr = slowptr->next;
while(slowptr) {
if(head->val!=slowptr->val) {
return false;
}
head = head->next;
slowptr = slowptr->next;
}
return true;
}
};
// @lc code=end
二叉树
二叉树最大深度
递归,dfs,bfs
利用递归,我们可以很方便地求得最大深度。1
2
3
4
5
6int maxDepth(TreeNode* root) {
if (root == nullptr) {
return 0;
}
return max(maxDepth(root->left), maxDepth(root->right)) + 1;
}
二叉平衡树
判断一个二叉树是否平衡。树平衡的定义是,对于树上的任意节点,其两侧节点的最大深度的差值不得大于 1。
解法类似于求树的最大深度,但有两个不同的地方:一是我们需要先处理子树的深度再进行比较,二是如果我们在处理子树时发现其已经不平衡了,则可以返回一个-1,使得所有其长辈节点可以避免多余的判断(本题的判断比较简单,做差后取绝对值即可;但如果此处是一个开销较大的比较过程,则避免重复判断可以节省大量的计算时间)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class Solution {
public:
int MaxDepth(TreeNode *node) {
if (node == nullptr) {
return 0;
}
int l = MaxDepth(node->left);
int r = MaxDepth(node->right);
if (abs(r - l) > 1 || r == -1 || l == -1) {
return -1;
}
return max(l, r) + 1;
}
bool isBalanced(TreeNode *root) { return MaxDepth(root) != -1; }
};
二叉树最长直径
求一个二叉树的最长直径。直径的定义是二叉树上任意两节点之间的无向距离。
可以利用递归来处理树。解题时要注意,在我们处理某个子树时,我们更新的最长直径值和递归返回的值是不同的。这是因为待更新的最长直径值是经过该子树根节点的最长直径(即两侧长度);而函数返回值是以该子树根节点为端点的最长直径值(即一侧长度),使用这样的返回值才可以通过递归更新父节点的最长直径值)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Solution {
public:
int MaxDepth(TreeNode *node, int &maxCount) {
if (node == nullptr) {
return 0;
}
int l = MaxDepth(node->left,maxCount);
int r = MaxDepth(node->right,maxCount);
// 更新最长直径,递归,从叶子节点到根节点,由下到上.
maxCount = max(l + r, maxCount);
return max(l, r) + 1;
}
int diameterOfBinaryTree(TreeNode *root) {
int maxDiameter{};
MaxDepth(root, maxDiameter);
return maxDiameter;
}
};
路径和
给定一个整数二叉树,求有多少条路径节点值的和等于给定值。
递归每个节点时,需要分情况考虑:(1)如果选取该节点加入路径,则之后必须继续加入连续节点,或停止加入节点(2)如果不选取该节点加入路径,则对其左右节点进行重新进行考虑。因此一个方便的方法是我们创建一个辅函数,专门用来计算连续加入节点的路径。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Solution {
public:
int pathStartWithNode(TreeNode *node, int targetSum) {
// 从node开始的和为targetSum的路径数目
if (node == nullptr) {
return 0;
}
// 选择该节点 如果等于targetSum,则路径数+1.
return node->val ==
targetSum + pathStartWithNode(node->left, targetSum - node->val) +
pathStartWithNode(node->right, targetSum - node->val);
}
int pathSum(TreeNode *root, int targetSum) {
if (root == nullptr) {
return 0;
}
// 从根节点开始,如果不选择根节点,则从左右节点开始
return pathStartWithNode(root, targetSum) + pathSum(root->left, targetSum) +
pathSum(root->right, targetSum);
}
};
判断一个二叉树是否对称
输入一个二叉树,输出一个布尔值,表示该树是否对称。
判断一个树是否对称等价于判断左右子树是否对称。一般习惯将判断两个子树是否相等或对称类型的题的解法叫做“四步法”:(1)如果两个子树都为空指针,则它们相等或对称(2)如果两个子树只有一个为空指针,则它们不相等或不对称(3)如果两个子树根节点的值不相等,则它们不相等或不对称(4)根据相等或对称要求,进行递归处理。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// 辅函数。
bool isLeftRightSymmetric(TreeNode* left, TreeNode* right) {
if (left == nullptr && right == nullptr) {
return true;
}
if (left == nullptr or right == nullptr) {
return false;
}
if (left->val != right->val) {
return false;
}
return isLeftRightSymmetric(left->left, right->right) &&
isLeftRightSymmetric(left->right, right->left);
}
// 主函数。
bool isSymmetric(TreeNode* root) {
if (root == nullptr) {
return true;
}
return isLeftRightSymmetric(root->left, root->right);
}
删点成林
给定一个整数二叉树和一些整数,求删掉这些整数对应的节点后,剩余的子树。
这道题最主要需要注意的细节是如果通过递归处理原树,以及需要在什么时候断开指针。同时,为了便于寻找待删除节点,可以建立一个哈希表方便查找。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29// 辅函数。
TreeNode* moveNodesToForest(TreeNode* root, unordered_set<int>& undeleted,
vector<TreeNode*>& forest) {
if (root == nullptr) {
return nullptr;
}
root->left = moveNodesToForest(root->left, undeleted, forest);
root->right = moveNodesToForest(root->right, undeleted, forest);
if (undeleted.contains(root->val)) {
if (root->left != nullptr) {
forest.push_back(root->left);
}
if (root->right != nullptr) {
forest.push_back(root->right);
}
root = nullptr;
}
return root;
}
// 主函数。
vector<TreeNode*> delNodes(TreeNode* root, vector<int>& to_delete) {
vector<TreeNode*> forest;
unordered_set<int> undeleted(to_delete.begin(), to_delete.end());
root = moveNodesToForest(root, undeleted, forest);
if (root != nullptr) {
forest.push_back(root);
}
return forest;
}
层次遍历
可以使用广度优先搜索进行层次遍历。注意,不需要使用两个队列来分别存储当前层的节点和下一层的节点,因为在开始遍历一层的节点时,当前队列中的节点数就是当前层的节点数,只要控制遍历这么多节点数,就能保证这次遍历的都是当前层的节点。
二叉树每层平均值
给定一个二叉树,求每一层的节点值的平均数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26vector<double> averageOfLevels(TreeNode* root) {
vector<double> level_avg;
if (root == nullptr) {
return level_avg;
}
queue<TreeNode*> q;
q.push(root);
int count = q.size();
while (count > 0) {
double level_sum = 0;
for (int i = 0; i < count; ++i) {
TreeNode* node = q.front();
q.pop();
level_sum += node->val;
if (node->left != nullptr) {
q.push(node->left);
}
if (node->right != nullptr) {
q.push(node->right);
}
}
level_avg.push_back(level_sum / count);
count = q.size();
}
return level_avg;
}
二叉树的前中后序遍历
前序遍历、中序遍历和后序遍历是三种利用深度优先搜索遍历二叉树的方式。它们是在对节点访问的顺序有一点不同,其它完全相同。
前序遍历先遍历父结点,再遍历左结点,最后遍历右节点
中序遍历先遍历左节点,再遍历父结点,最后遍历右节点
后序遍历先遍历左节点,再遍历右结点,最后遍历父节点
从先序和中序构建二叉树
给定一个二叉树的前序遍历和中序遍历结果,尝试复原这个树。已知树里不存在重复值的节点。
通过本题的样例讲解一下本题的思路。前序遍历的第一个节点是 4,意味着 4 是根节点。我们在中序遍历结果里找到 4 这个节点,根据中序遍历的性质可以得出,4 在中序遍历数组位置的左子数组为左子树,节点数为 1,对应的是前序排列数组里 4 之后的 1 个数字(9);4 在中序遍历数组位置的右子数组为右子树,节点数为 3,对应的是前序排列数组里最后的 3 个数字。有了这些信息,我们就可以对左子树和右子树进行递归复原了。为了方便查找数字的位置,我们可以用哈希表预处理中序遍历的结果。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24// 辅函数。
TreeNode* reconstruct(unordered_map<int, int>& io_map, vector<int>& po, int l,
int r, int mid_po) {
if (l > r) {
return nullptr;
}
int mid_val = po[mid_po];
int mid_io = io_map[mid_val];
int left_len = mid_io - l + 1;
TreeNode* node = new TreeNode(mid_val);
// 左子树的根节点如果存在,一定在当前节点在preorder的下一个位置
node->left = reconstruct(io_map, po, l, mid_io - 1, mid_po + 1);
// 通过left_len找到右子树节点开始的索引
node->right = reconstruct(io_map, po, mid_io + 1, r, mid_po + left_len);
return node;
}
// 主函数。
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
unordered_map<int, int> io_map;
for (int i = 0; i < inorder.size(); ++i) {
io_map[inorder[i]] = i;
}
return reconstruct(io_map, preorder, 0, preorder.size() - 1, 0);
}
先序遍历
不使用递归,实现二叉树的前序遍历
因为递归的本质是栈调用,因此我们可以通过栈来实现前序遍历。注意入栈的顺序。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28class Solution {
private:
public:
vector<int> preorderTraversal(TreeNode *root) {
// 先序遍历
// 先求根节点 再找左子树 再找右子树
// 也可以使用栈模拟递归
std::stack<TreeNode *> s;
if (root == nullptr) {
return {};
}
vector<int> r;
s.push(root);
while (!s.empty()) {
auto t = s.top();
s.pop();
r.push_back(t->val);
if (t->right) {
s.push(t->right);
}
if (t->left) {
s.push(t->left);
}
}
return r;
}
};
二叉查找树
二叉查找树(Binary Search Tree, BST)是一种特殊的二叉树:对于每个父节点,其左子树中所有节点的值小于等于父结点的值,其右子树中所有节点的值大于等于父结点的值。因此对于一个二叉查找树,我们可以在 O(log n) 的时间内查找一个值是否存在:从根节点开始,若当前节点的值大于查找值则向左下走,若当前节点的值小于查找值则向右下走。同时因为二叉查找树是有序的,对其中序遍历的结果即为排好序的数组。
恢复二叉搜索树
给你二叉搜索树的根节点 root ,该树中的 恰好 两个节点的值被错误地交换。请在不改变其结构的情况下,恢复这棵树 。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31class Solution {
public:
void midTraverse(TreeNode *node, TreeNode *&prev, TreeNode *&firstNode,
TreeNode *&secondNode) {
if (node == nullptr) {
return;
}
midTraverse(node->left, prev, firstNode, secondNode);
if (prev != nullptr) {
auto val = node->val;
if (val < prev->val) {
if (firstNode == nullptr) {
firstNode = prev;
}
secondNode = node;
}
}
prev = node;
midTraverse(node->right, prev, firstNode, secondNode);
}
void recoverTree(TreeNode *root) {
// 中序遍历 先找到第一个出问题的值的节点 也就是值比上一个值小
// 然后找到最后一个出问题的节点 也就是值比上一个值大时,找到第二个错误节点
TreeNode *prev = nullptr, *firstNode = nullptr, *secondNode = nullptr;
midTraverse(root, prev, firstNode, secondNode);
swap(firstNode->val, secondNode->val);
}
};
可以使用中序遍历这个二叉查找树,同时设置一个 prev 指针,记录当前节点中序遍历时的前节点。如果当前节点大于 prev 节点的值,说明需要调整次序。有一个技巧是如果遍历整个序列过程中只出现了一次次序错误,说明就是这两个相邻节点需要被交换;如果出现了两次次序错误,那就需要交换这两个节点。
修建二叉搜索树
给定一个二叉查找树和两个整数 L 和 R,且 L < R,试修剪此二叉查找树,使得修剪后所有节点的值都在 [L, R] 的范围内。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28class Solution {
public:
TreeNode *trimNode(TreeNode *node, int low, int high) {
if (node == nullptr) {
return nullptr;
}
node->left = trimNode(node->left, low, high);
node->right = trimNode(node->right, low, high);
auto val = node->val;
if (val < low) {
node = trimNode(node->right, low, high);
return node;
}
if (val > high) {
// 节点的值若大于high,则其以及右子树 的值大于val
// 都要剔除
node = trimNode(node->left, low, high);
return node;
}
return node;
}
TreeNode *trimBST(TreeNode *root, int low, int high) {
root = trimNode(root, low, high);
return root;
}
};
字典树
判断字符串是否存在或者具有某种字符串前缀.
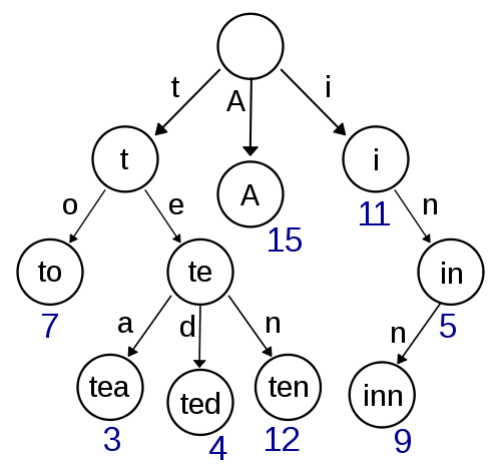
假如我们有一个储存了近万个单词的字典,即使我们使用哈希,在其中搜索一个单词的实际开销也是非常大的,且无法轻易支持搜索单词前缀。然而由于一个英文单词的长度 n 通常在 10 以内,如果我们使用字典树,则可以在O(n)——近似 O(1)O*(1) 的时间内完成搜索,且额外开销非常小。
图
作为指针三剑客之三,图是树的升级版。图通常分为有向(directed)或无向(undirected),有循环(cyclic)或无循环(acyclic),所有节点相连(connected)或不相连(disconnected)。树即是一个相连的无向无环图,而另一种很常见的图是有向无环图(Directed Acyclic Graph,DAG)。
图通常有两种表示方法。假设图中一共有 n 个节点、m 条边。第一种表示方法是邻接矩阵(adjacency matrix):我们可以建立一个 n × n 的矩阵 G,如果第 i 个节点连向第 j 个节点,则 G[i][j] = 1,反之为 0;如果图是无向的,则这个矩阵一定是对称矩阵,即 G[i][j] = G[j][i]。第二种表示方法是邻接链表(adjacency list):我们可以建立一个大小为 n 的数组,每个位置 i 储存一个数组或者链表,表示第 i 个节点连向的其它节点。邻接矩阵空间开销比邻接链表大,但是邻接链表不支持快速查找 i 和 j 是否相连,因此两种表示方法可以根据题目需要适当选择。除此之外,我们也可以直接用一个 m × 2 的矩阵储存所有的边。
二分图
二分图 定义:如果能将一个图的节点集合分割成两个独立的子集 A 和 B ,并使图中的每一条边的两个节点一个来自 A 集合,一个来自 B 集合,就将这个图称为 二分图 。
二分图算法也称为染色法,是一种广度优先搜索。如果可以用两种颜色对图中的节点进行着色,并且保证相邻的节点颜色不同,那么图为二分。
给定一个图,判断其是否可以二分。
拓扑排序
拓扑排序(topological sort)是一种常见的,对有向无环图排序的算法。给定有向无环图中的 N个节点,我们把它们排序成一个线性序列;若原图中节点 i 指向节点 j,则排序结果中 i 一定在 j 之前。拓扑排序的结果不是唯一的,只要满足以上条件即可。
可以先建立一个邻接矩阵表示图,方便进行直接查找。这里注意我们将所有的边反向,使得如果课程 i 指向课程 j,那么课程 i 需要在课程 j 前面先修完。这样更符合我们的直观理解。
拓扑排序也可以被看成是广度优先搜索的一种情况:我们先遍历一遍所有节点,把入度为 0 的节点(即没有前置课程要求)放在队列中。在每次从队列中获得节点时,我们将该节点放在目前排序的末尾,并且把它指向的课程的入度各减 1;如果在这个过程中有课程的所有前置必修课都已修完(即入度为 0),我们把这个节点加入队列中。当队列的节点都被处理完时,说明所有的节点都已排好序,或因图中存在循环而无法上完所有课程。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39class Solution {
public:
vector<int> findOrder(int numCourses, vector<vector<int>> &prerequisites) {
vector<vector<int>> course(numCourses);
vector<int> pres(numCourses, 0);
vector<int> result;
queue<int> q;
for (auto p : prerequisites) {
course[p[1]].push_back(p[0]);
pres[p[0]]++;
}
for (int i = 0; i < numCourses; ++i) {
// 遍历所有课程 找到入度为0的课程
if (pres[i] == 0) {
q.push(i);
}
}
while (!q.empty()) {
auto r = q.front();
q.pop();
result.push_back(r);
// 获得指向的课程
for (auto c : course[r]) {
// 更新入度
// 其指向的课程 入度-1
pres[c]--;
if (pres[c] == 0) {
q.push(c);
}
}
}
for (int i = 0; i < numCourses; ++i) {
if (pres[i] != 0) {
return {};
}
}
return result;
}
};
并查集
并查集(union-find, disjoint set)可以动态地连通两个点,并且可以非常快速地判断两个点是否连通。假设存在 n 个节点,我们先将所有节点的父节点标为自己;每次要连接节点 i 和 j 时,我们可以将秩较小一方的父节点标为另一方(按秩合并);每次要查询两个节点是否相连时,我们可以查找 i 和 j 的祖先是否最终为同一个人,并减少祖先层级(路径压缩)。
LRUCache
采用一个链表来储存信息的 key 和 value,链表的链接顺序即为最近使用的新旧顺序,最新的信息在链表头节点。同时我们需要一个哈希表进行查找,键是信息的 key,值是其在链表中的对应指针/迭代器。每次查找成功(cache hit)时,需要把指针/迭代器对应的节点移动到链表的头节点。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53class LRUCache {
private:
int counter_{};
std::list<pair<int, int>> caches_;
std::unordered_map<int, list<pair<int, int>>::iterator> key_to_cache_it_;
int capacity_;
public:
LRUCache(int capacity) : capacity_(capacity) {}
int get(int key) {
if (key_to_cache_it_.count(key)) {
// 更新访问时间
auto it = key_to_cache_it_.at(key);
auto value = it->second;
caches_.erase(it);
key_to_cache_it_.erase(key);
caches_.push_front({key, value});
key_to_cache_it_[key] = caches_.begin();
return value;
} else {
return -1;
}
}
void put(int key, int value) {
if (key_to_cache_it_.count(key)) {
// 如果存在,更新值与最近访问顺序
auto it = key_to_cache_it_[key];
caches_.erase(it);
caches_.push_front({key, value});
key_to_cache_it_[key] = caches_.begin();
} else {
// 如果不存在,看是否超出容量
if (key_to_cache_it_.size() + 1 > capacity_) {
// 如果超出容量
// 弹出最后一个值
auto [poppedKey, _] = caches_.back();
key_to_cache_it_.erase(poppedKey);
caches_.pop_back();
caches_.push_front({key, value});
key_to_cache_it_[key] = caches_.begin();
} else {
// 未超出容量,直接插入
caches_.push_front({key, value});
key_to_cache_it_[key] = caches_.begin();
}
}
}
};
双指针
滑动窗口
前缀和
动态规划 贪心 dfs bfs 回溯
使用数据结构 stack queue map set
有用的资料
LeetCode 101: 力扣刷题指南 (第二版) | LeetCode 101 - A Grinding Guide
leetcode_101/LeetCode 101 - A Grinding Guide.pdf at master · changgyhub/leetcode_101
-
代码随想录 codetop hot100 labuladong leetcode101
