最近在看微软的AI for Beginners,质量比较高,这里相当于将其中的一篇文章写过来加点自己的理解.
模型的训练的一个主要问题是梯度爆炸或者梯度消失,前者会导致训练不稳定,表现出来就是损失值不稳定,一直都处在较高值降不下去,后者就是更新缓慢.下面介绍一些技巧
将值保持在合理的范围
为了让数值运算更稳定,我们希望确保神经网络中的所有值都在合理的范围内,通常为[-1,1]或[0,1]. 浮点计算的本质是,不同大小的值不能精确地一起操作.这样做是为了避免原本非常大或非常小的值进行传播时使得梯度爆炸或者消失,当保持在[-1,1]后数值比较稳定.
例如,如果我们将10^-10^和10^10^相加,我们很可能得到10^10^,因为较小的值将被“转换”为与较大的值相同的order(这涉及到计算机的浮点数运算),因此尾数将丢失。
此外,大多数激活函数在[-1,1]附近具有非线性,因此将所有输入数据缩放到[-1,1]或[0,1]间隔是有意义的。
所以在预处理数据时通常会Normalize.
权重初始化
理想情况下,我们希望这些值在通过网络层后处于相同的范围内。因此,初始化权重以保持输入值前后的分布方式是很重要的。
我的理解就是weight不能太大或太小或者其他情况,这影响到输出的分布.
正态分布N(0,1)不是一个好主意,因为如果我们有n个输入,输出的标准差将是n,并且值可能跳出[0,1]区间。也就是说如果输入是(B,C)的数据,B表示一个batch,C是特征数,进行正态分布权重初始化,假设w矩阵shape是(C,2)服从标准正态分布,得到值标准差为n(因为有n个特征,每个特征乘以一个正态分布,然后将每个特征相加)
所以不能使用标准正态分布初始化权重,通常使用以下初始化:
- 均匀分布—uniform,也就是在一个范围内值相同.
- N(0,1/N) 正态分布,使得输出尽量符合N(0,1)
- N(0,1/√N_in)保证对于N(0,1)的输入,将保持相同的平均值和标准差.
- N(0,√2/(N_in+N_out))——所谓的Xavier初始化(glorot),它有助于在前向和后向传播过程中保持信号在一定范围内
在pytorch中默认是N(0,1/√N_in)初始化,当然这可以自己设置.
批量规范化
即使进行了适当的权重初始化,在训练过程中权重也可能变得任意大或小,并且它们会使信号超出适当的范围。
我们可以通过使用一种归一化技术来恢复信号。虽然有几种(权重规格化、层规格化),但最常用的是批量规格化。批量归一化的思想是考虑整个小批量的所有值,并根据这些值执行归一化(即减去平均值并除以标准差)。它被实现为网络层,在应用权重之后但在激活函数之前进行这种归一化。因此,我们可能会看到更高的最终准确性和更快的训练。
除了batchnormal之外还有layernormal和instancenormal等等,这些不同的方式应用在不同的任务上.
Dropout
Dropout是一种有趣的技术,可以在训练过程中去除一定比例的随机神经元。它也被实现为一个具有一个参数(要去除的神经元的百分比,通常为10%-50%)的层,在训练过程中,它将输入向量的随机元素归零,然后将其传递到下一层。
这种影响可以用几种方式来解释:
- 它可以被认为是模型的一个随机冲击因素,它使优化超出了局部最小值
- 它可以被认为是隐式模型平均(implicit model averaging),因为我们可以说,在dropout时,我们训练的模型略有不同
在Pytorch实现中,在训练过程会去除一定比例神经元然后将剩余的神经元权重乘以去除比例的倒数,测试时正常传播.
下图横线不同的值表示dropout的比例
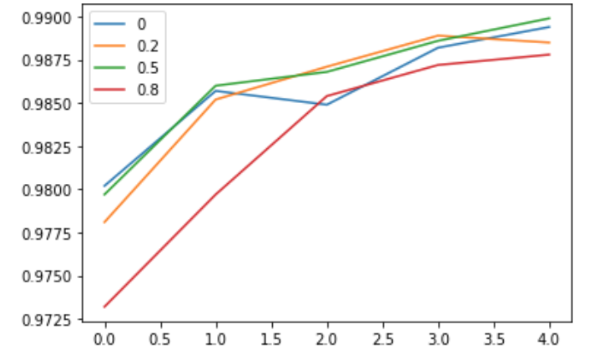
这东西没有好的数学支撑,但是效果不错.我没记错的话就是hinton提出的,这人有认知心理学领域的知识,所以会提出这些东西.
防止过拟合
深度学习的一个非常重要的方面就是能够防止过度拟合。虽然使用非常强大的神经网络模型可能很诱人,但我们应该始终平衡模型参数的数量与训练样本的数量。
有几种方法可以防止过度拟合:
早期停止(early stopping)——持续监控验证集上的错误,并在验证错误开始增加时停止训练。
显式权重衰减/正则化(explicit weight decay/regularization)-为权重的高绝对值的损失函数添加额外的惩罚,这可以防止模型获得非常不稳定的结果.
权重衰减/正则化指的是损失函数加上weight的正则化系数,以希望权重减小.
在WGAN中其实还有gradient penalty,将梯度的Norm加到损失函数中
模型平均(model averaging)——训练几个模型,然后对结果进行平均。这有助于最小化差异。
Dropout(隐式模型平均值)
优化器
训练的另一个重要方面是选择好的训练算法。虽然经典的梯度下降(每次选取一个样本)是一个合理的选择,但它有时可能太慢,或导致其他问题.
在深度学习中,我们使用随机梯度下降(SGD),这是一种应用于从训练集中随机选择的小批量的梯度下降。使用以下公式调整权重:
引入动量
在动量SGD中,我们保持了之前步骤的一部分梯度。这类似于当我们带着惯性在某个地方移动时,我们受到了不同方向的冲击,我们的轨迹不会立即改变,而是保持了原始运动的一部分。在这里,我们引入另一个向量v来表示速度:
这里,参数γ表示我们考虑惯性的程度:γ=0对应于经典SGD;γ=1是一个纯运动方程
Adam,Adagrad
由于在每一层中,我们将信号乘以某个矩阵W~i~,这取决于||Wi||,因此梯度可以减小并接近0,也可以无限上升。它是梯度消失/爆炸问题的本质。
一种解决方法就是计算梯度时,只使用损失梯度的方向,忽略绝对值.
还是要学好数学基础,这里梯度矩阵求一个L-2 Norm,计算类似归一化值(像单位向量一样).这样保持了梯度的分布,同时减小了梯度的值避免了梯度爆炸.
这个算法被称为Adagrad。另一个使用相同思想的算法:RMSProp,Adam.
其实优化器的选择还是要看具体任务.
梯度裁剪
梯度剪裁是上述思想的扩展。当ℒ|| ≤ θ、 我们在权重优化中考虑原始梯度,当ℒ|| > θ-我们将梯度除以它的范数。这里θ是一个参数,在大多数情况下,我们可以取θ=1或θ=10。
学习率递减
训练的成功往往取决于学习率参数η。合理的假设是,η的值越大,训练越快,这是我们在训练开始时通常想要的,然后η的值就越小,我们就可以微调网络。因此,在大多数情况下,我们希望在训练过程中降低η。这可以通过在每个训练时期后将η乘以某个数字(例如0.98)来实现,或者通过使用更复杂的学习率scheduler来实现。
所以学习率一开始可以设置大一点,后面进行减小.
Pytorch中有learning rate scheduler用于调度学习率.
使用不同的网络架构
A Brief History Of Neural Network Architectures (topbots.com)
网络架构需要跟具体任务相关,通常,我们会采用一种已被证明适用于我们特定任务(或类似任务)的架构

另一个好方法是使用能够自动调整到所需复杂性的体系结构。在某种程度上,ResNet架构和Inception是自我调整的.
本人能力有限,如果上面写的有误,还请评论指出,敬请赐教.
