需要一些基本的cv知识
图像分辨率
图像分辨率可以定义为图像中存在的像素数。当像素数量增加时,图像的质量会增加。我们已经在前面看到了图像的形状,它给出了行和列的数量。这可以说是该图像的分辨率。几乎所有人都知道的一些标准分辨率是320 x 240像素(主要适用于小屏幕设备)、1024 x 768像素(适用于在标准计算机显示器上观看)、720 x 576像素(适合在宽高比为4:3的标准清晰度电视机上观看),1280 x 1024像素(适用于在宽高比为5:4的液晶显示器上全屏观看)、1920 x 1080像素(用于在高清电视上观看),现在我们甚至有4K、5K和8K分辨率,超高清显示器和电视分别支持3840 x 2160像素、5120 x 2880像素和7680 x 4320像素
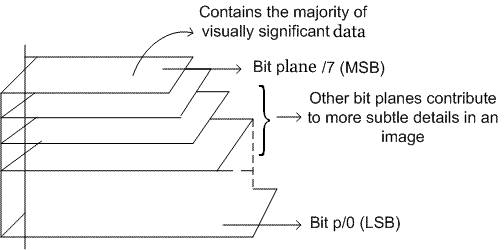
图像像素的高位包含的信息比低位更多,我们可以将图像划分为不同级别的位平面。例如,将图像划分为8位(0-7)平面,其中最后几个平面包含图像的大部分信息。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import cv2
import torch
from torch import nn
import matplotlib.pylab as plt
import numpy as np
img = cv2.imread("../imgs/00000.png",cv2.IMREAD_GRAYSCALE)
c1 = np.mod(img,2)
c2 = np.mod(np.floor(img/2),2)
c3 = np.mod(np.floor(img/4),2)
c4 = np.mod(np.floor(img/8),2)
c5 = np.mod(np.floor(img/16),2)
c6 = np.mod(np.floor(img/32),2)
c7 = np.mod(np.floor(img/64),2)
c8 = np.mod(np.floor(img/128),2)
cc = 2*(2*(2*c8+c7)+c6)
to_plot = [img,c1,c2,c3,c4,c5,c6,c7,c8,cc]
fig,axes = plt.subplots(2,5, subplot_kw={'xticks': [], 'yticks': []})
fig.subplots_adjust(hspace=0.05, wspace=0.05)
for ax,i in zip(axes.flat, to_plot):
ax.imshow(i, cmap='gray')
plt.tight_layout()
plt.show()
cv2.waitKey()
可以使用像素的高位重建图像
图像金字塔

图像金字塔是一组图像,所有图像都来自一张原始图像,这些图像被连续下采样,直到达到某个期望的停止点。
有两种常见的图像金字塔:
- 高斯金字塔:用于对图像进行下采样
- 拉普拉斯金字塔:用于从金字塔中较低的图像重建上采样图像(分辨率较低)
图像直方图
1 | def his(img_gray): |

图像深度
数字化图像的每个像素是用一组二进制数进行描述,像素的色彩由RGB通道决定,其中包含表示图像颜色的位数称为图像深度。如灰度图像,每个像素颜色占用1个字节8位,则称图像深度为8位,而RGB的彩色图像占用3字节,图像深度为24位。
图像深度又称为色深(Color Depth),它确定了一幅图像中最多能使用的颜色数,即彩色图像的每个像素最大的颜色数,或者确定灰度图像的每个像素最大的灰度级数。
使用opencv的imread读取模式有
IMREAD_UNCHANGED = -1, //返回原始图像。alpha通道不会被忽略,如果有的话。加载给定格式的图像,包括alpha通道。Alpha通道存储透明度信息——Alpha通道的值越高,像素就越不透明
IMREAD_GRAYSCALE = 0, //返回灰度图像
IMREAD_COLOR = 1, //返回通道顺序为BGR的彩色图像
IMREAD_ANYDEPTH = 2, //当输入具有相应的深度时返回16位/ 32位图像,否则将其转换为8位。.
IMREAD_ANYCOLOR = 4, //则以任何可能的颜色格式读取图像。
颜色空间
颜色空间是一种协议(protocol),用于以易于再现的方式表示颜色。我们知道,灰度图像具有单个像素值,彩色图像每个像素包含3个值——红色、绿色和蓝色通道的强度。
大多数计算机视觉用例处理RGB格式的图像。然而,视频压缩和设备独立存储等应用程序在很大程度上依赖于其他颜色空间,如色相(Hue即色相,就是我们平时所说的红、绿,如果你分的更细的话可能还会有洋红、草绿等等)、饱和度(色彩的深浅度(0-100%,对于一种颜色比如红色,我们可以用浅红——大红——深红——红得发紫等等语言来描述它)、色调(纯度,色彩的亮度(0-100%) ,这个在调整屏幕亮度的时候比较常见)即HSV颜色空间。
RGB图像由不同颜色通道的颜色强度组成,即强度和颜色信息在RGB颜色空间中混合,但在HSV颜色空间中,颜色和强度信息彼此分离。这将使HSV颜色空间对光源更改更加稳健。

图像resize
机器学习模型使用固定大小的输入。同样的想法也适用于计算机视觉模型。我们用于训练模型的图像必须具有相同的大小。现在,如果我们通过从各种来源抓取图像来创建自己的数据集,这可能会成为问题。这就是调整图像大小的功能凸显出来的地方。

INTER_NEAREST:最近邻插值
INTER_LINEAR:双线性插值
INTER_AREA:使用像素面积关系重新采样
INTER_CUBIC:4×4像素邻域上的双三次插值
INTER_LANCZOS4:8邻域上的Lanczos插值
1 | import cv2 |
图像旋转以及平移
可以用作图像增强的技术1
2
3
4
5
6
7
8import cv2
import numpy as np
img = cv2.imread("../imgs/00000.png")
rows,cols = img.shape[:2]
M = cv2.getRotationMatrix2D((cols/2,rows/2),45,1)
dst = cv2.warpAffine(img,M,(cols,rows))
cv2.imshow("dst",dst)
cv2.waitKey()
会使用到cv2.getRotationMatrix2D与cv2.warpAffine.
cv2.getRotationMatrix2D参数分别是中心,旋转角度以及缩放系数.
cv2.warpAffine是做仿射变换,

图像平移可以用于为模型添加平移不变性,因为通过平移,我们可以改变对象在图像中的位置,为模型提供更多的多样性,从而获得更好的可推广性,这在困难的条件下有效,即当对象没有完全对准图像中心时。这种增强技术还可以帮助模型正确地对具有部分可见对象的图像进行分类。以下图为例。即使图像中没有完整的鞋子,模型也应该能够将其分类为鞋子1
2
3
4
5M = np.float32([[1,0,-100],[0,1,-100]])
dst = cv2.warpAffine(img,M,(cols,rows))
plt.imshow(dst)
cv2.imshow("dst",dst)

图像阈值
阈值分割是一种图像分割方法。它将像素值与阈值进行比较,并相应地进行更新。图像阈值的一个简单应用可以将图像划分为前景和背景,阈值只能应用于灰度图像。

上面是简单阈值,此外还有自适应阈值
简单阈值是全局的,对于在不同区域具有不同照明条件的图像可能不太适用,此时可以使用自适应阈值处理。算法计算图像的局部阈值,在同一图像的不同区域获得不同的阈值,并为具有不同照明的图像提供了更好的结果。在自适应阈值的情况下,对图像的不同部分使用不同的阈值。该函数可为具有不同照明条件的图像提供更好的结果,因此被称为“自适应”。Otsu的二值化方法为整个图像找到一个最佳阈值。它适用于双峰图像(直方图中有2个峰值的图像)。
cv2.ADAPTIVE_THRESH_MEAN_C:阈值是邻域的平均值。cv2.ADAPTIVE_THRESH_GAUSSIAN_C:阈值是邻域值的加权和,其中权重是高斯窗口。Block Size 决定邻域的大小。C 从计算的平均值或加权平均值中减去常数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#import the libraries
import numpy as np
import matplotlib.pyplot as plt
import cv2
%matplotlib inline
#ADAPTIVE THRESHOLDING
gray_image = cv2.imread('index.png',0)
ret,thresh_global = cv2.threshold(gray_image,127,255,cv2.THRESH_BINARY)
#here 11 is the pixel neighbourhood that is used to calculate the threshold value
thresh_mean = cv2.adaptiveThreshold(gray_image,255,cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY,11,2)
thresh_gaussian = cv2.adaptiveThreshold(gray_image,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,11,2)
names = ['Original Image','Global Thresholding','Adaptive Mean Threshold','Adaptive Gaussian Thresholding']
images = [gray_image,thresh_global,thresh_mean,thresh_gaussian]
for i in range(4):
plt.subplot(2,2,i+1),plt.imshow(images[i],'gray')
plt.title(names[i])
plt.xticks([]),plt.yticks([])
plt.show()

图像分割
图像分割是将图像中的每个像素分类到某个类别的任务。例如,将每个像素分类为前景或背景。图像分割对于从图像中提取相关部分是重要的。
分水岭算法是一种经典的图像分割算法。它将图像中的像素值视为地形。为了找到对象边界,它将初始标记作为输入。然后,该算法开始从标记淹没盆地(flooding the basin from the markers),直到标记在对象边界相遇。

位操作
按位运算包括AND、OR、NOT和XOR。在计算机视觉中,当我们有一个遮罩图像并想将该遮罩应用于另一个图像以提取感兴趣的区域时,这些操作非常有用。


边缘检测
边缘是图像中图像亮度急剧变化或具有不连续性的点。这种不连续性通常对应于:
- 深度不连续
- 表面方向的不连续性
- 材料特性的变化
- 场景照明的变化
边缘是图像的非常有用的特征,可以用于不同的应用,如图像中对象的分类和定位。甚至深度学习模型也会计算边缘特征,以提取图像中存在的对象的信息。

1
2
3
4
5
6
7
8
9import cv2
import numpy as np
img = cv2.imread("../imgs/00000.png")
edges = cv2.Canny(img, 100, 200)
cv2.imshow("edges", edges)
cv2.waitKey()
图像滤波
在图像滤波中,使用像素值的相邻值来更新像素值。但是,这些值最初是如何更新的呢?,有多种更新像素值的方法,例如从邻居中选择最大值,使用邻居的平均值等。每种方法都有自己的用途。例如,对邻域中的像素值取平均值用于图像模糊。
高斯滤波也用于图像模糊,其根据相邻像素与所考虑像素的距离为相邻像素赋予不同的权重。对于图像过滤,我们使用内核。核是不同形状的数字矩阵,如3 x 3、5 x 5等。核用于计算图像一部分的点积。当计算像素的新值时,内核中心与像素重叠。相邻像素值与内核中的相应值相乘。计算出的值被分配给与内核中心重合的像素。


1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import numpy as np
import cv2
image = cv2.imread('../imgs/test.png')
kernel = np.ones((5,5),np.float32)/25
#using the averaging kernel for image smoothening
averaging_kernel = np.ones((3,3),np.float32)/9
filtered_image = cv2.filter2D(image,-1,kernel)
cv2.imshow("avg_filtered_image",filtered_image)
#get a one dimensional Gaussian Kernel
gaussian_kernel_x = cv2.getGaussianKernel(5,1)
gaussian_kernel_y = cv2.getGaussianKernel(5,1)
#converting to two dimensional kernel using matrix multiplication
gaussian_kernel = gaussian_kernel_x * gaussian_kernel_y.T
#you can also use cv2.GaussianBLurring(image,(shape of kernel),standard deviation) instead of cv2.filter2D
filtered_image = cv2.filter2D(image,-1,gaussian_kernel)
cv2.imshow("filtered_image",filtered_image)
cv2.waitKey()

上图的两个卷积核分别是
图像轮廓(contours)
轮廓是表示图像中对象边界的点或线段的闭合曲线。轮廓本质上是图像中对象的形状。与边缘不同,轮廓不是图像的一部分。相反,它们是与图像中对象的形状相对应的点和线段的抽象集合。我们可以使用轮廓来计算图像中对象的数量,根据对象的形状对其进行分类,或者从图像中选择特定形状的对象。1
2
3
4
5
6
7
8
9
10
11
12import numpy as np
import cv2
import matplotlib.pyplot as plt
image = cv2.imread('../imgs/test.png')
#converting RGB image to Binary
gray_image = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
ret,thresh = cv2.threshold(gray_image,127,255,0)
#calculate the contours from binary image
contours,hierarchy = cv2.findContours(thresh,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
with_contours = cv2.drawContours(image,contours,-1,(0,255,0),3)
plt.imshow(with_contours[...,::-1])
plt.show()

特征匹配
使用SIFT或SURF从不同图像中提取的特征可以进行匹配,以找到存在于不同图像中的相似对象/模式。OpenCV库支持多种特征匹配算法,如brute force 匹配、knn特征匹配等。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import numpy as np
import cv2
import matplotlib.pyplot as plt
#reading images in grayscale format
image1 = cv2.imread('../imgs/00000.png',0)
image2 = cv2.warpAffine(image1, np.float32([[1, 0, 100], [0, 1, -100]]), (image1.shape[1], image1.shape[0]))
sift = cv2.xfeatures2d.SIFT_create()
#finding out the keypoints and their descriptors
keypoints1,descriptors1 = sift.detectAndCompute(image1,None)
keypoints2,descriptors2 = sift.detectAndCompute(image2,None)
#matching the descriptors from both the images
bf = cv2.BFMatcher()
matches = bf.knnMatch(descriptors1,descriptors2,k = 2)
#selecting only the good features
good_matches = []
for m,n in matches:
if m.distance < 0.75*n.distance:
good_matches.append([m])
image3 = cv2.drawMatchesKnn(image1,keypoints1,image2,keypoints2,good_matches,None,flags=2)
cv2.imshow("image3",image3)
cv2.waitKey()


在上面的图像中,我们可以看到从原始图像(左侧)中提取的关键点与其旋转版本的关键点相匹配。这是因为特征是使用SIFT提取的,SIFT对这种变换是不变的。
人脸检测
OpenCV支持基于haar级联的对象检测。Haar级联是基于机器学习的分类器,用于计算图像中的不同特征,如边缘、线条等。然后,这些分类器使用多个正样本和负样本进行训练。OpenCV Github仓库中提供了针对人脸、眼睛等不同对象的经过训练的分类器,也可以针对任何对象训练自己的haar级联。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25#import required libraries
import numpy as np
import cv2
import matplotlib.pyplot as plt
#load the classifiers downloaded
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier('haarcascade_eye.xml')
#read the image and convert to grayscale format
img = cv2.imread('rotated_face.jpg')
gray = cv2.cvtColor(img, cv.COLOR_BGR2GRAY)
#calculate coordinates
faces = face_cascade.detectMultiScale(gray, 1.1, 4)
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
#draw bounding boxes around detected features
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
#plot the image
plt.imshow(img)
#write image
cv2.imwrite('face_detection.jpg',img)
很多级联器的xml文件都是直接拿别人的,网上也有训练的教程.
图像梯度向量
image gradient vector
图像梯度矢量被定义为每个单独像素的度量,包含x轴和y轴上的像素颜色变化。该定义与连续多变量函数的梯度一致,该函数是所有变量的偏导数的向量。
边缘检测算子

prewitt
Prewitt算子不是只依赖于四个直接相邻的邻居,而是利用八个周围的像素来获得更平滑的结果。
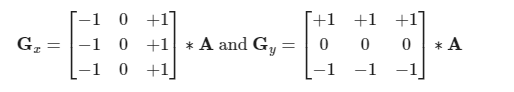
sobel
为了更加强调直接相邻像素的影响,它们被分配了更高的权重。

角点检测
角点检测(Corner Detection)是计算机视觉系统中用来获得图像特征的一种方法,广泛应用于运动检测、图像匹配、视频跟踪、三维建模和目标识别等领域中。也称为特征点检测。 角点通常被定义为两条边的交点,更严格的说,角点的局部邻域应该具有两个不同区域的不同方向的边界。而实际应用中,大多数所谓的角点检测方法检测的是拥有特定特征的图像点,而不仅仅是“角点”。这些特征点在图像中有具体的坐标,并具有某些数学特征,如局部最大或最小灰度、某些梯度特征等
Harris
- 计算窗口中各像素点在x和y方向的梯度;
- 计算两个方向梯度的乘积,即Ix ^ 2 , Iy ^ 2 , IxIy(可以用一些一阶梯度算子求得图像梯度)
- 使用滤波核对窗口中的每一像素进行加权,生成矩阵M和元素A,B,C
- 计算每个像素的Harris响应值R,并对小于某阈值T的R置0;
- 由于角点所在区域的一定邻域内都有可能被检测为角点,所以为了防止角点聚集,最后在3×3或5×5的邻域内进行非极大值抑制,局部最大值点即为图像中的角点。
常用特征
SIFT
关键点是处理图像时应该注意的一个概念。这些基本上是图像中的兴趣点。关键点类似于给定图像的特征。它们是定义图像中有趣内容的位置。关键点很重要,因为无论图像如何修改(旋转、收缩、扩展、失真),我们都会为图像找到相同的关键点。
尺度不变特征变换(SIFT)是一种非常流行的关键点检测算法。它包括以下步骤:
- Scale-space extrema detection
- Keypoint localization
- Orientation assignment
- Keypoint descriptor
- Keypoint matching
从SIFT提取的特征可用于图像拼接、对象检测等应用。下面的代码和输出显示了使用SIFT计算的关键点及其方向。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18#import required libraries
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
#show OpenCV version
print(cv2.__version__)
#read the iamge and convert to grayscale
image = cv2.imread('index.png')
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
#create sift object
sift = cv2.xfeatures2d.SIFT_create()
#calculate keypoints and their orientation
keypoints,descriptors = sift.detectAndCompute(gray,None)
#plot keypoints on the image
with_keypoints = cv2.drawKeypoints(gray,keypoints)
#plot the image
plt.imshow(with_keypoints)
SIFT算法有助于定位图像中的局部特征,通常称为图像的“关键点”。这些关键点是尺度和旋转不变量,可用于各种计算机视觉应用,如图像匹配、对象检测、场景检测等。我们还可以在模型训练期间使用使用SIFT生成的关键点作为图像的特征。SIFT特征、边缘特征或弓形特征的主要优点是它们不受图像的大小或方向的影响。
整个过程可以分为4个部分:
Constructing a Scale Space:确保要素与scale无关
Keypoint Localisation:识别合适的特征或关键点
Orientation Assignment:确保关键点旋转不变
Keypoint Descriptor::为每个关键点分配一个唯一的id
Constructing the Scale Space
我们需要识别给定输入图像中最明显的特征,同时忽略任何噪声。此外,我们需要确保这些功能不依赖于scale。
对于图像中的每个像素,高斯模糊会基于其具有特定σ值的相邻像素来计算一个值。
纹理和次要细节将从图像中删除,只保留相关信息,如形状和边缘
比例空间是从单个图像生成的具有不同比例的图像的集合。
因此,这些模糊图像是为多个比例创建的。为了创建一组不同比例的新图像,将拍摄原始图像并将比例缩小一半。对于每个新图像,我们将创建模糊版本。
理想的缩放次数是四次,对于每次缩放,模糊图像的数量应该是五个。

高斯差分是一种特征增强算法,它涉及将原始图像的一个模糊版本与另一个模糊程度较低的原始图像版本相减。
DoG为每个octave创建另一组图像,方法是从相同比例的前一个图像中减去每个图像。
到目前为止,我们已经创建了多个尺度的图像(通常用σ表示),并对每个尺度使用高斯模糊来减少图像中的噪声。接下来将尝试使用一种名为高斯差分(DoG)的技术来增强这些特征。

如下图,在左边,我们有5个图像,都来自第一个octave(我的理解就是不同scale的图像)。通过在前一图像上应用高斯模糊来创建每个后续图像。在右边,我们有四个通过减去连续的高斯而生成的图像。

我们为这些图像中的每一个都增强了功能。现在我们有了一组新的图像,我们将使用它来找到重要的关键点
Keypoint Localization
一旦创建了图像,下一步就是从图像中找到可用于特征匹配的重要关键点。其思想是找到图像的局部最大值和最小值。
本部分分为两个步骤:1)求局部最大值和最小值 2)删除低对比度关键点(关键点选择)
为了定位局部最大值和最小值,我们遍历图像中的每个像素,并将其与相邻像素进行比较。
当说“相邻”时,这不仅包括该图像的周围像素(像素所在),还包括octave中上一个和下一个图像的九个像素。

这意味着将每个像素值与其他26个像素值进行比较,以确定它是否是称为极值的局部最大值/最小值。例如,有三个来自第一个octave的图像。标记为x的像素与相邻像素(绿色)进行比较,如果它是相邻像素中最高或最低的,则选择它作为关键点或兴趣点
Keypoint Selection
已经成功地生成了尺度不变的关键点。但是这些关键点中的一些可能对噪声不具有鲁棒性。我们需要进行最终检查,以确保我们有最准确的关键点来表示图像特征
因此,我们将消除对比度低或非常靠近边缘的关键点。为了处理低对比度关键点,为每个关键点计算二阶泰勒展开。如果结果值小于0.03(以大小计),我们将拒绝关键点。
Keypoint Descriptor
到目前为止已经有了尺度不变和旋转不变的稳定关键点。
最后将使用相邻的像素、它们的方向和大小来为这个关键点生成一个独特的特征,称为“描述符”。
首先在关键点周围取一个16×16的邻域。这个16×16的块被进一步划分为4×4个子块,对于这些子块中的每一个子块,我们使用幅度和方向来生成直方图。

在这个阶段,bin的尺寸增加了,我们只取了8个bins。这些箭头中的每一个表示8bins,箭头的长度定义了大小。因此,我们将为每个关键点总共有128个bin值。
Feature Matching
现在将使用SIFT特征进行特征匹配。为1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36import cv2
import matplotlib.pyplot as plt
# read images
img1 = cv2.imread('eiffel_2.jpeg')
img2 = cv2.imread('eiffel_1.jpg')
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
#sift
sift = cv2.xfeatures2d.SIFT_create()
keypoints_1, descriptors_1 = sift.detectAndCompute(img1,None)
keypoints_2, descriptors_2 = sift.detectAndCompute(img2,None)
# read images
img1 = cv2.imread('eiffel_2.jpeg')
img2 = cv2.imread('eiffel_1.jpg')
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
#sift
sift = cv2.xfeatures2d.SIFT_create()
keypoints_1, descriptors_1 = sift.detectAndCompute(img1,None)
keypoints_2, descriptors_2 = sift.detectAndCompute(img2,None)
#feature matching
bf = cv2.BFMatcher(cv2.NORM_L1, crossCheck=True)
matches = bf.match(descriptors_1,descriptors_2)
matches = sorted(matches, key = lambda x:x.distance)
img3 = cv2.drawMatches(img1, keypoints_1, img2, keypoints_2, matches[:50], img2, flags=2)
plt.imshow(img3),plt.show()


- SIFT(Scale Invariant Feature Transform,尺度不变特征变换)是一种强大的图像匹配技术,它可以识别和匹配图像中对缩放、旋转和仿射失真不变的特征。
- 它被广泛应用于计算机视觉应用,包括图像匹配、物体识别和三维重建。SIFT技术包括生成具有不同尺度的图像的尺度空间,然后使用高斯差分(DoG)方法来识别图像中的关键点。
- 它还涉及为每个关键点计算描述符,这些描述符可用于特征匹配和对象识别。
- 它可以使用Python和OpenCV库来实现,OpenCV库提供了一组用于检测关键点、计算描述符和匹配特征的函数。
SURF
Speeded Up Robust Features(SURF)是SIFT的增强版。它的工作速度要快得多,并且对图像转换更健壮。
在SIFT中,使用高斯拉普拉斯算子来近似尺度空间。拉普拉斯算子是用于计算图像边缘的核。拉普拉斯核通过近似图像的二阶导数来工作。因此,它对噪声非常敏感。我们通常将高斯核应用于拉普拉斯核之前的图像,因此将其命名为高斯拉普拉斯。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17#import required libraries
import cv2
import numpy as np
import matplotlib.pyplot as plt
#show OpenCV version
print(cv2.__version__)
#read image and convert to grayscale
image = cv2.imread('index.png')
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
#instantiate surf object
surf = cv2.xfeatures2d.SURF_create(400)
#calculate keypoints and their orientation
keypoints,descriptors = surf.detectAndCompute(gray,None)
with_keypoints = cv2.drawKeypoints(gray,keypoints)
plt.imshow(with_keypoints)
HOG
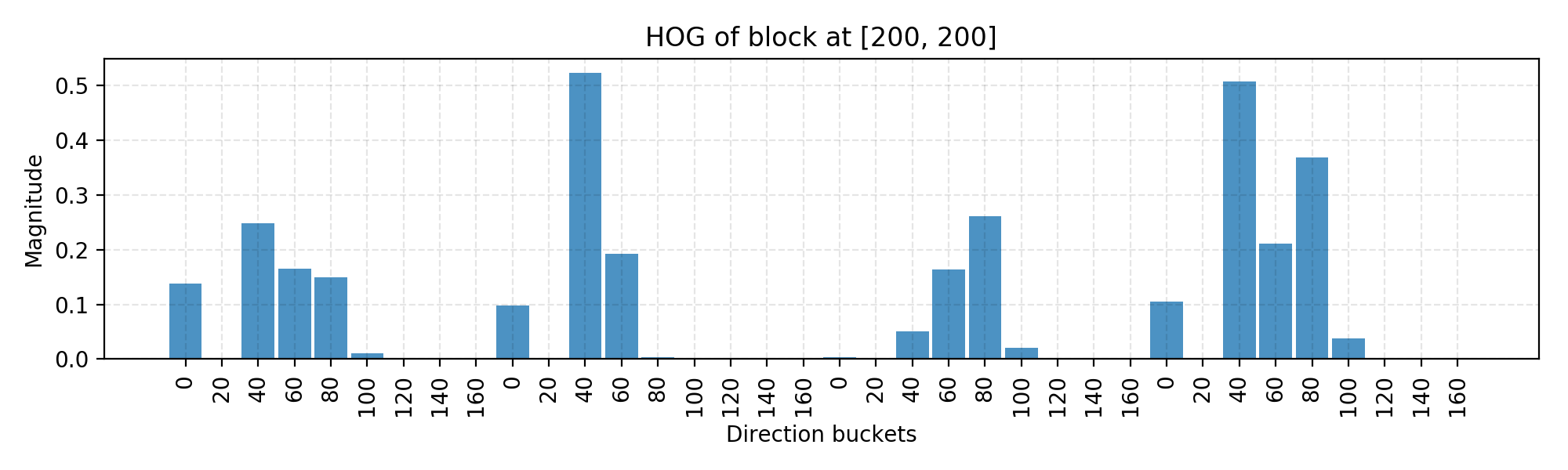
面向梯度直方图(HOG)是一种从像素颜色中提取特征的有效方法,用于构建对象识别分类器。
- 预处理图像,包括调整大小和颜色标准化。
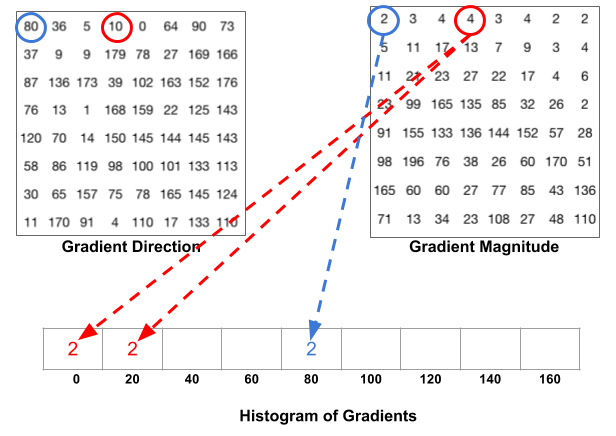
- 计算每个像素的梯度矢量,以及其大小和方向。
![]()
- 将图像划分为许多8x8像素的单元格。在每个单元中,这64个单元的幅度值被装箱,并累积添加到9个无符号方向的bucket中(没有符号,因此0-180度而不是0-360度;这是基于经验实验的实际选择)。
4.然后,我们在图像上滑动一个2x2个单元格(因此是16x16像素)的块。在每个块区域中,4个单元的4个直方图被连接成36个值的一维向量,然后被归一化为具有单位权重。最终的HOG特征向量是所有块向量的级联。
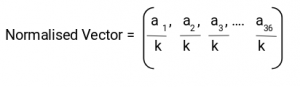
它可以被输入到像SVM这样的分类器中,用于学习对象识别任务。
Camera Calibration
相机是一种将3D世界转换为2D图像的设备。相机在捕捉三维图像并将其存储在二维图像中起着非常重要的作用。
相机校准是图像处理或计算机视觉领域中常用的词。相机校准方法旨在识别图像创建过程的几何特征。这是在许多计算机视觉应用中执行的重要步骤,尤其是当需要场景上的度量信息时。在这些应用中,相机通常根据一组固有参数进行分类,如轴的偏斜、焦距和主点,其方向由旋转和平移等外部参数表示。线性或非线性算法用于实时利用已知点及其在图像平面中的投影来估计内在和外在参数。

1.内在或内部参数它允许在图像帧中的像素坐标和相机坐标之间进行映射。例如,透镜的光学中心、焦距和径向失真系数。
2.外部或外部参数它描述了相机的方向和位置。这是指相机相对于某个世界坐标系的旋转和平移。
参考资料
综述
- Object Detection in 2023: The Definitive Guide - viso.ai
- [1905.05055] Object Detection in 20 Years: A Survey (arxiv.org)
- [2104.11892] A Survey of Modern Deep Learning based Object Detection Models (arxiv.org)
- A comprehensive review of object detection with deep learning - ScienceDirect
博客
- Object Detection for Dummies Part 1: Gradient Vector, HOG, and SS | Lil’Log (lilianweng.github.io)
- A Beginner’s Guide to Image Processing With OpenCV and Python (analyticsvidhya.com)
- 也许还不错的学习网站PyImageSearch - You can master Computer Vision, Deep Learning, and OpenCV.
- 维基百科 卷积核Kernel (image processing) - Wikipedia)
