除了3D目标检测算法外,自动驾驶还需要将获取到的图像数据或者处理后的特征进行通信和融合,这里介绍相关论文.
重要的几个仓库coperception/coperception: An SDK for multi-agent collaborative perception. (github.com),https://github.com/DerrickXuNu/OpenCOOD和[ucla-mobility/V2V4Real: CVPR2023 Highlight] The official codebase for paper “V2V4Real: A large-scale real-world dataset for Vehicle-to-Vehicle Cooperative Perception” (github.com)
OPV2V: An Open Benchmark Dataset and Fusion Pipeline for Perception with Vehicle-to-Vehicle Communication
abs
利用车对车通信提高自动驾驶技术的感知性能近年来引起了广泛关注;然而,由于缺乏合适的开放数据集来对算法进行基准测试,因此很难开发和评估协同感知技术。
融合方法介绍
论文中融合算法介绍了多种,这里按时间线写一下.
早期融合有最早的Cooper.
主要介绍中期融合
F-cooper
2019论文中提出了VFF和SFF.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class SpatialFusion(nn.Module):
def __init__(self):
super(SpatialFusion, self).__init__()
def regroup(self, x, record_len):
cum_sum_len = torch.cumsum(record_len, dim=0)
split_x = torch.tensor_split(x, cum_sum_len[:-1].cpu())
return split_x
def forward(self, x, record_len):
# x: B, C, H, W, split x:[(B1, C, W, H), (B2, C, W, H)]
split_x = self.regroup(x, record_len)
out = []
for xx in split_x:
xx = torch.max(xx, dim=0, keepdim=True)[0]
out.append(xx)
return torch.cat(out, dim=0)
最后利用融合后的特征传给cls_head和reg_head1
2
3
4psm = self.cls_head(fused_feature)
rm = self.reg_head(fused_feature)
output_dict = {'psm': psm,
'rm': rm}
V2VNet: Vehicle-to-Vehicle Communication for Joint Perception and Prediction 2020
Abs
探讨了使用车对车(V2V)通信来改善自动驾驶汽车的感知和运动预测性能。通过智能地聚合从附近多辆车接收到的信息,我们可以从不同的视角观察同一场景。这使我们能够穿透遮挡物并远距离检测参与者,其中观察结果非常稀疏或不存在。
SDV 需要对场景进行 3D 推理,识别其他智能体,并预测他们的未来可能如何发展。这些任务通常称为感知和运动预测。强大的感知和运动预测对于 SDV 规划和操纵交通以安全地从一个点到另一个点都至关重要.
尽管取得了这些进展,但挑战依然存在。例如,被严重遮挡或距离较远的物体会导致观测稀疏,并对现代计算机视觉系统构成挑战。
在本文中,考虑了车对车 (V2V) 通信设置,其中每辆车都可以向附近的车辆(半径 70m 以内)广播和接收信息。请注意,基于现有的通信协议,这个广播范围是现实的。为了在满足现有硬件传输带宽能力的同时,实现具有强大感知和运动预测性能的最佳折衷方案,我们应该发送P&P神经网络的压缩中间表示。因此,我们推导出了一种名为V2VNet的新颖的P&P模型,该模型利用空间感知图神经网络(GNN)来聚合从附近所有SDV接收到的信息,使我们能够智能地组合来自不同时间点和场景中视点的信息。
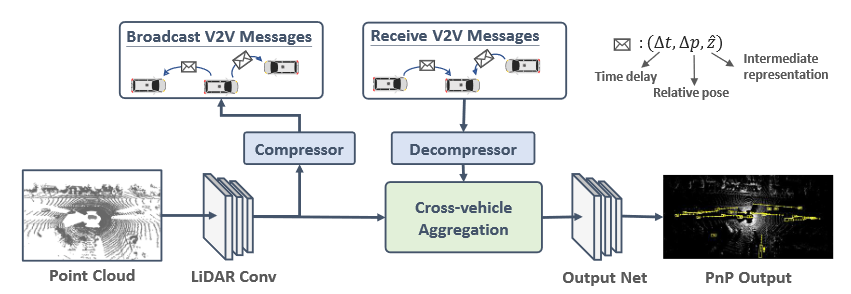
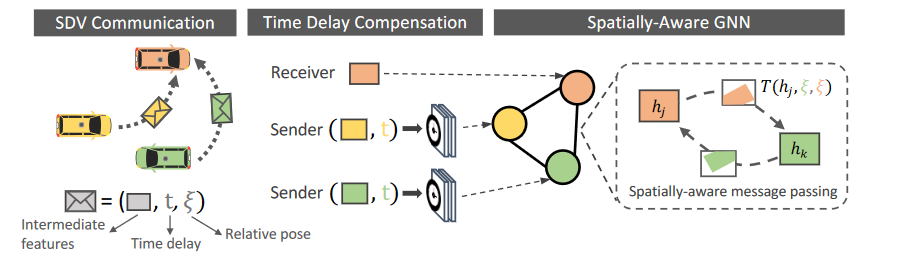
总结
较早的一篇使用全面神经网络探讨V2V协同的目标感知与检测,贡献了V2V-sim仿真数据集.
DiscoNet
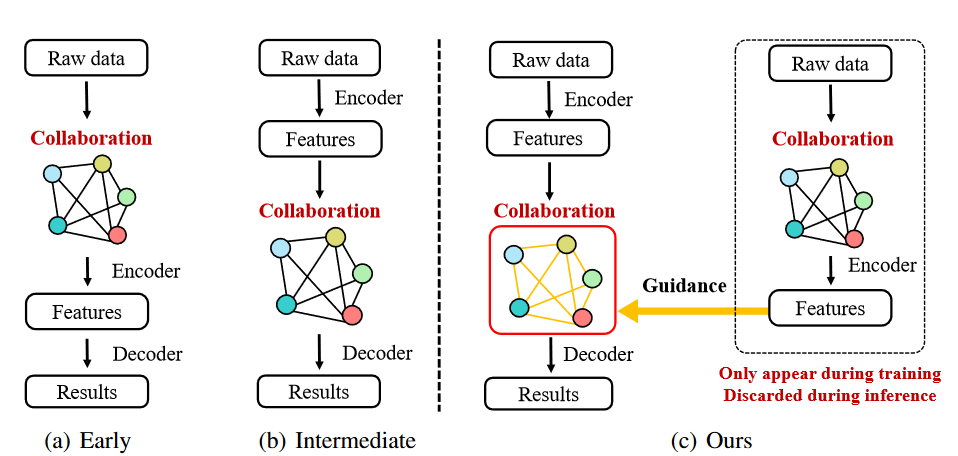
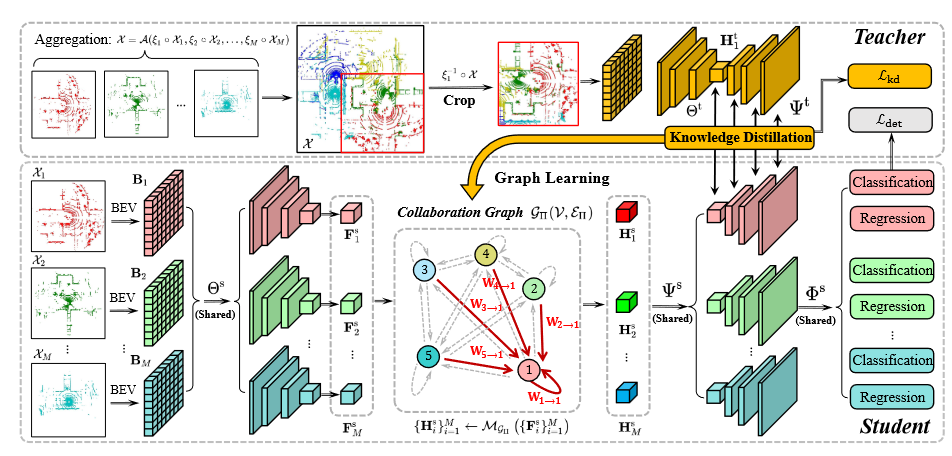
涉及到了图和蒸馏的方法,我了解不多.
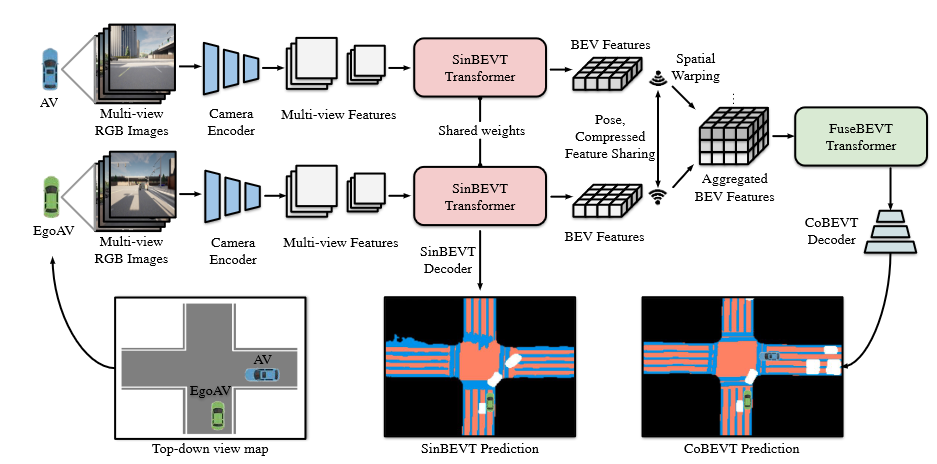
CoBEVT 2022
Abstract
在本文中,提出了CoBEVT,这是第一个可以协同生成BEV地图预测的通用多智能体多相机感知框架。
为了在底层 Transformer 架构中有效地融合来自多视图和多智能体数据的相机特征,我们设计了一个融合轴向注意力模块 (FAX),该模块可以捕获跨视图和智能体的稀疏局部和全局空间交互.
将多摄像头视图投射到整体纯电动汽车空间中,在空间和时间上保持道路元素的位置和比例方面具有明显的优势,这对于各种自动驾驶任务(包括场景理解和规划)至关重要
地图视图(或 BEV)语义分割是一项基本任务,旨在根据单个或多个校准的摄像头输入预测路段。在基于摄像头的精确BEV语义分割方面已经做出了重大努力。最流行的技术之一是利用深度信息来推断相机视图和规范地图之间的对应关系。另一个系列使用基于注意力的模型直接学习摄像头到BEV的空间转换,无论是隐式还是显式
尽管取得了令人鼓舞的结果,但基于视觉的感知系统具有固有的局限性——众所周知,相机传感器对物体遮挡和景深有限很敏感,这可能导致在严重遮挡或远离相机镜头的区域性能较差
 `
`
Related Work
最近,V2VNet提出将从3D骨干中提取的中间特征(即中间融合)循环,然后利用空间感知图神经网络进行多智能体特征聚合。遵循类似的传输范式,OPV2V 采用简单的智能体单头注意力来融合所有特征。F-Cooper使用简单的 maxout 操作来融合特征。
DiscoNet通过约束中间特征图来匹配早期融合教师模型中的对应关系来探索知识蒸馏。
与之前的多智能体算法相比,我 CoBEVT 率先采用稀疏transformer来高效、详尽地探索车辆之间的相关性。
此外,以往的方法主要侧重于与激光雷达的协同感知,而我们的目标是提出一种低成本的基于摄像头的、没有激光雷达设备的协同感知解决方案。
Transformer 最初是为自然语言处理而提出的 。ViT 首次证明,一个纯粹的 Transformer 只是将图像块视为视觉词,通过大规模预训练就足以完成视觉任务。Swin Transformer通过限制局部(移位)窗口中的注意力场,进一步提高了纯 Transformer 的通用性和灵活性。对于高维数据,Video Swin Transformer 将 Swin 方法扩展到移动的 3D 时空窗口,从而实现高性能和低复杂性。
最近的工作主要集中在改进注意力模型的结构上,包括稀疏注意力,扩大的感受野,金字塔设计,有效的替代方案]等。
Fused Axial Attention
融合来自多个智能体的 BEV 特征需要跨所有智能体的空间位置进行局部和全局交互。一方面,相邻的自动驾驶汽车通常对同一物体具有不同的遮挡级别;因此,更关心细节的局部注意力可以帮助在该对象上构建像素到像素的对应关系。
ego应汇总附近自动驾驶汽车每个位置的所有BEV特征,以获得可靠的估计。另一方面,长期的全局情境感知也有助于理解道路拓扑语义或交通状态——车辆前方的道路拓扑和交通密度通常与后方的道路拓扑和交通密度高度相关。这种全局推理也有利于多相机视图的理解。
同一辆车被分成多个视图,global attention能够将它们连接起来以进行语义推理
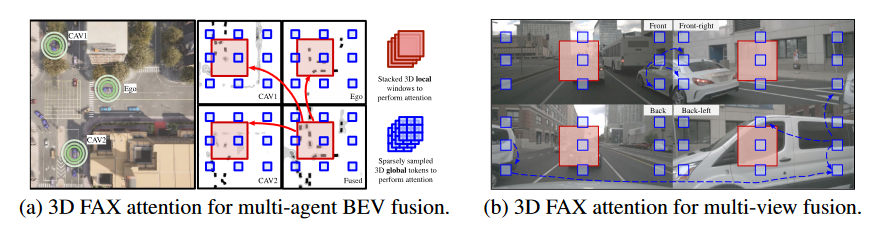
提出了一种称为融合轴向注意力的新颖 3D 注意力机制,作为 SinBEVT 和 FuseBEVT 的核心组件,可以有效地聚合本地和全局范围内跨代理或相机视图的特征。
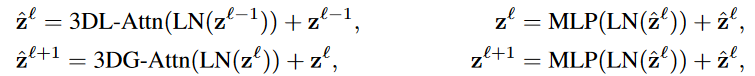
设 X∈ R^N×H×W×C^ 是来自 N 智能体的空间维度为 H × W 的堆叠 BEV 特征
在局部特征上,将特征图划分为 3D 非重叠窗口,每个窗口的大小为 N × P × P,然后将形状为(H/P× W/P,N × P^2^,C) 的分割张量 输入到自注意力模型中
在全局特征中,使用统一的 3D 网格 N ×G×G 将特征 X 划分为形状 (N × G^2^,H/G×W /G,C)
将注意力集中在该张量的第一个轴上,该张量表示关注稀疏采样的标记
将这种 3D 局部和全局注意力与 Transformer 的典型设计相结合 ,包括层归一化 (LN)、MLP 和跳跃连接,形成了提出的 FAX 注意力块
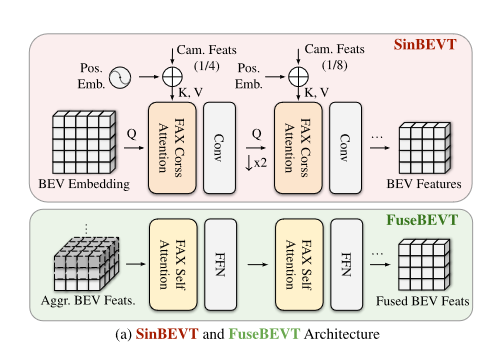
SinBEVT for Single-agent BEV Feature Computation
CVT 使用低分辨率的 BEV 查询,该查询完全交叉关注图像特征,这会导致小物体的性能下降,尽管效率很高。因此,CoBEVT 学习高分辨率的 BEV 嵌入,然后使用分层结构来优化分辨率降低的 BEV 特征。为了在高分辨率下有效地查询来自相机编码器的特征,FAX-SA模块进一步扩展为构建FAX交叉关注(FAX-CA)模块,其中查询向量使用BEV嵌入获得,而键/值向量由多视图相机特征投影。
FuseBEVT for Multi-agent BEV Feature Fusion
一旦接收到包含中间BEV表示的广播消息和发送者的姿态,自我车辆就会应用可微分的空间变换算子Γξ,将接收到的特征几何扭曲到ego的坐标系上:H~i~ = Γ~ξ~ (F~i~)∈ R^H×W×C^
3D FAX-SA 可以处理从多个代理抽取的同一估计区域(红框),以得出最终的聚合表示。此外,稀疏采样token(蓝框)可以全局交互,以获得对地图语义(如道路、交通等)的上下文理解。
总结
使用swim transfomer类似架构进行多层级的特征融合.设计了agent_size和window_size.
Robust Collaborative 3D Object Detection in Presence of Pose Errors (CoAlign) 2022
Abs
协作式 3D 目标检测利用多个智能体之间的信息交换,在存在传感器损伤(如遮挡)的情况下提高目标检测的准确性,然而,在实践中,由于定位不完善导致的姿态估计误差会导致空间信息错位,并显著降低协作性能。
为了减轻姿势错误的不利影响,我们提出了CoAlign,这是一种新颖的混合协作框架,对未知的姿势错误具有鲁棒性。所提出的解决方案依赖于一种新颖的智能体-对象姿态图建模来增强协作智能体之间的姿态一致性。此外,采用多尺度数据融合策略,在多个空间分辨率下聚合中间特征。
尽管大规模数据集和强大模型的发展速度很快,但单个智能体的 3D 对象检测仍存在固有的局限性,例如遮挡和远处的物体。通过利用智能体之间的通信,例如驾驶场景中的车联网(V2X),多个智能体可以相互共享互补的感知信息,从而促进更全面的接受领域。
为了实现这种协作式3D检测,最近的工作贡献了高质量的数据集和有效的协作方法。但在这个新兴领域仍然存在许多挑战,例如通信带宽限制、延迟和对抗性攻击。这项工作的重点是减轻姿势误差的负面影响。
由于我们的智能体-对象姿态图在优化过程中没有使用任何训练参数,因此该方法具有很强的泛化能力,可以适应任意级别的姿态误差。为了有效缓解姿态误差的影响,我们进一步考虑了一种多尺度中间融合策略,该策略在多个空间尺度上全面聚合协作信息。
我们在仿真和真实数据集上对基于LiDAR的3D目标检测任务进行了广泛的实验,包括OPV2V 、V2X-Sim 2.0和DAIR-V2X.所提出的CoAlign在存在姿态误差的协同3D目标检测任务中实现了至少12%的性能提升。
考虑场景中的 N 个代理。每个智能体都具有感知、沟通和检测的能力。目标是通过分布式协作来达到每个智能体更好的 3D 检测能力。
在以前的文献中,有三种类型的协作:早期协作,传输原始观测数据,中间协作,,传输中间特征,后期协作,传输检测输出。
设 O~i~ 和 B~i~ 分别是第 i 个智能体的感知观察和检测输出。对于第 i 个代理,基于中间协作的标准 3D 对象检测的工作原理如下
在实践中,定位模块估计的每个 6DoF 姿态 ξi 通常是有噪声的。然后,在步骤2中进行姿态变换后,每个消息Mj→i将具有不同的固有坐标系,导致步骤3中的融合错位和步骤4中的检测输出不好。
这项工作的目标是通过在步骤2之前引入额外的姿势校正来最大限度地减少姿势错误的影响
CoAlign结合了中间和后期协作策略。与中间融合相比,这种混合协作可以利用智能体检测到的边界框作为场景地标,并校正智能体之间的相对姿态。
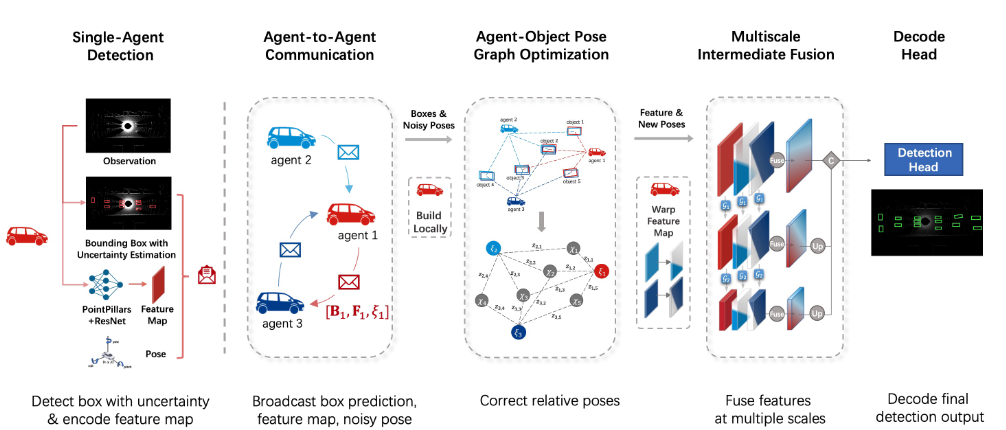
为了实现单智能体 3D 目标检测器 fdetection(·),可以利用现成的设计,例如 PointPillars ,为第 i 个智能体生成中间特征 F~i~ 和估计边界框 B~i~。请注意,对于每个边界框,我们还估计其不确定性。
由于我们后来依靠这些框来纠正姿势错误,因此混乱的检测可能会导致更糟糕的相对姿势。每个框的估计不确定度可以提供有益的置信度信息,以排除不需要的检测。
每个框的估计不确定度可以提供有益的置信度信息,以排除不需要的检测。
Agent-Object Pose Graph Optimization
单智能体检测后,第 i 个智能体共享三类消息,包括
i) 其姿态 ξ~i~ 由其自身定位模块估计;
ii) 第 i 个agent检测到的边界框;
iii) 其特征图 F~i~
为了可靠地融合来自其他智能体的特征图,每个智能体都需要校正相对姿态。
Multiscale Feature Fusion
空间对齐后,每个智能体聚合其他智能体的协作信息,并获得信息量更大的特征。但是,即使在相对姿态校正之后,特征图之间的错位可能仍然存在。更精细尺度的特征可以提供更详细的几何和语义信息,而粗尺度的特征对位姿误差的敏感度较低。多尺度结构可以同时发挥优势,并产生信息丰富和强大的功能。
总结
结合了单车的late和intermediate的输出,提出了agent-pose map用于修正pose.使用多尺度融合.CoAlign在融合层面主要使用self-attention和multi-scale(backbone使用了多尺度的ResNet).在代码中使用resnet并下采样得到多尺度的特征,将这些多尺度特征通过融合模块.融合模块种通过warp_affine将特征转换到(H,W)整个感知范围内,再进行self-attention.然后将融合后的多尺度特征通过多级decoder最后concat在一起.
其中affine操作利用车之间转换矩阵以及affine_grid和affine_sample得到,也就是将特征仿射变换到lidar range.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20def normalize_pairwise_tfm(pairwise_t_matrix, H, W, discrete_ratio, downsample_rate=1):
pairwise_t_matrix = pairwise_t_matrix[:,:,:,[0, 1],:][:,:,:,:,[0, 1, 3]] # [B, L, L, 2, 3]
pairwise_t_matrix[...,0,1] = pairwise_t_matrix[...,0,1] * H / W
pairwise_t_matrix[...,1,0] = pairwise_t_matrix[...,1,0] * W / H
pairwise_t_matrix[...,0,2] = pairwise_t_matrix[...,0,2] / (downsample_rate * discrete_ratio * W) * 2
pairwise_t_matrix[...,1,2] = pairwise_t_matrix[...,1,2] / (downsample_rate * discrete_ratio * H) * 2
normalized_affine_matrix = pairwise_t_matrix
return normalized_affine_matrix
def warp_affine_simple(
src, M, dsize,
mode='bilinear',
padding_mode='zeros',
align_corners=False):
B, C, H, W = src.size()
grid = F.affine_grid(M, [B, C, dsize[0], dsize[1]],
align_corners=align_corners).to(src)
return F.grid_sample(src, grid, align_corners=align_corners)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36class Att_w_Warp(nn.Module):
def __init__(self, feature_dims):
super(Att_w_Warp, self).__init__()
self.att = ScaledDotProductAttention(feature_dims)
def forward(self, xx, record_len, normalized_affine_matrix):
_, C, H, W = xx.shape
B, L = normalized_affine_matrix.shape[:2]
split_x = regroup(xx, record_len)
batch_node_features = split_x
out = []
# iterate each batch
for b in range(B):
N = record_len[b]
t_matrix = normalized_affine_matrix[b][:N, :N, :, :]
# update each node i
i = 0 # ego
x = warp_affine_simple(batch_node_features[b], t_matrix[i, :, :, :], (H, W))
cav_num = x.shape[0]
x = x.view(cav_num, C, -1).permute(2, 0, 1) # (H*W, cav_num, C), perform self attention on each pixel.
h = self.att(x, x, x)
h = h.permute(1, 2, 0).view(cav_num, C, H, W)[0, ...] # C, W, H before
out.append(h)
out = torch.stack(out)
return out
class ScaledDotProductAttention(nn.Module):
def __init__(self, dim):
super(ScaledDotProductAttention, self).__init__()
self.sqrt_dim = np.sqrt(dim)
def forward(self, query, key, value):
score = torch.bmm(query, key.transpose(1, 2)) / self.sqrt_dim
attn = F.softmax(score, -1)
context = torch.bmm(attn, value)
return context
Learning for Vehicle-to-Vehicle Cooperative Perception under Lossy Communication (V2VAM) 2023
Abs
深度学习已广泛应用于智能车辆驾驶感知系统,如3D目标检测。一种很有前途的技术是协同感知,它利用车对车(V2V)通信在车辆之间共享基于深度学习的特征。然而,大多数协作感知算法都假设了理想的通信,而没有考虑现实世界中非常常见的有损通信(LC)对特征共享的影响。
在本文中探讨了LC对合作感知的影响,并提出了一种新的方法来减轻这些影响。我们的方法包括LC感知维修网络(LCRN)和V2V注意力模块(V2VAM),具有车内注意力和不确定性感知车辆间注意力。
V2V通信中的信息共享有三种方式:(1)将原始传感器数据共享为早期融合,(2)将基于深度学习的检测网络的中间特征共享为中间融合,(3)将检测结果共享为后期融合。
最近的研究]表明,中间融合是检测精度和带宽要求之间的最佳权衡。
最近提出了许多用于V2V协同感知的中间融合方法;但是,它们都假定了理想的通信。唯一一项考虑非理想通信的V2V协同感知研究仅关注通信延迟。迄今为止,尚无研究探讨有损通信(LC)对复杂真实驾驶环境中V2V协同感知的影响
在城市交通场景中,V2V通信容易受到一系列可能导致有损通信的因素的影响,例如来自障碍物(例如建筑物和车辆)的多径效应(电磁波经不同路径传播后,各分量场到达接收端时间不同,按各自相位相互叠加而造成干扰,使得原来的信号失真,或者产生错误)、快速移动的车辆引入的多普勒频移、其他通信网络产生的干扰.
该文首先研究了有损通信在V2V协同感知中的负面影响,然后提出了一种新的中间LC感知特征融合方法。具体而言,所提方法包括LC感知修复网络(LCRN)和专门设计的V2V注意力模块(V2VAM),以增强自我车辆与其他车辆之间的交互.
V2VAM包括ego车辆的车内注意力和不确定性感知的车辆间注意力。在真实驾驶中收集具有有损通信的真实CAV感知数据具有挑战性.
基于LiDAR的检测方法,这些方法通常将LiDAR点转换为体素或柱子,在基于体素的、或基于Pillar的目标检测方法中占主导地位。PointRCNN提出了一种基于原始点云的两阶段策略,即先学习粗略估计,然后用语义属性对其进行细化。一些方法[]建议将空间分割成体素,并为每个体素生成特征。但是,3D 体素的处理成本通常很高。为了解决这个问题,PointPillars建议将沿z轴的所有体素压缩为一个柱子,然后在鸟瞰空间中预测3D框。此外,最近的一些方法结合了基于体素和基于点的方法,以联合检测3D物体。
3D 感知方法的性能很大程度上取决于 3D 点云的精度。然而,LiDAR 摄像头存在折射、遮挡和远距离等问题,因此单车系统在一些具有挑战性的情况下可能会变得不可靠 。近年来,车对车(V2V)/车对基础设施(V2X)协同系统被提出,以克服单车系统使用多辆车的弊端。不同车辆之间的协作使3D感知网络能够融合来自不同来源的信息。
为了在数据负载和准确性之间找到平衡,最近的方法侧重于通过共享中间表示来进行中间融合。F-cooper应用体素特征融合和空间特征融合来自两辆车。V2VNet 采用图神经网络来聚合 LiDAR 从每辆车中提取的特征。V2X-ViT 提出了一种视觉 Transformer 架构,用于融合车辆和基础设施的功能。Cui等提出了一种基于点的Transformer进行点云处理,该Transformer可以将协同感知与控制决策相结合
Tu等提出了一种基于中间表示的多智能体深度学习系统中高效实用的在线攻击网络。Luo等利用注意力模块融合中间特征,增强特征互补性。Lei等提出了一种延迟补偿模块,以实现中间特征级同步。胡(where2comm)等提出了一种空间置信度感知沟通策略,通过关注感知关键领域来使用较少的communication来提高绩效.
OPV2V利用自注意力模块来融合接收到的中间特征。CoBEVT 提出了局部全局稀疏注意力,可以捕获视图和智能体之间的复杂空间交互,以提高协作感知的性能
然而,这些融合方法都是以理想通信为前提的,在现实世界中,有损通信会使性能急剧下降。为了解决这个问题,我们设计了一种特殊的V2V注意力模块(V2VAM),包括ego车辆的车内注意力和不确定性感知的车辆间注意力,以增强V2V交互。
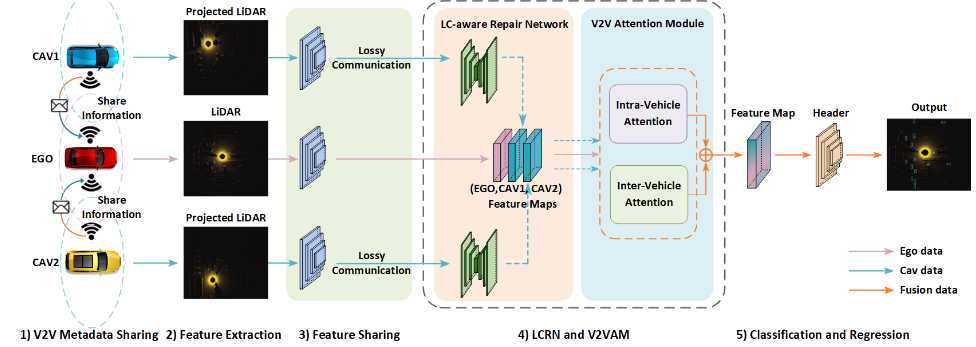
本文主要关注数据传输过程中的有损通信挑战 所以假设V2V系统中不存在通信延迟或定位错误。共享数据也可能在到达目的地之前受到其他信号的干扰或被攻击者修改,从而导致有损数据。在这项工作中,旨在通过提出LC感知修复网络和提高V2V感知网络的鲁棒性来消除有损通信。
该文提出了一种新的中间LCaware特征融合框架。包括五个组件:1)V2V元数据共享,2)激光雷达特征提取,3)特征共享,4)LC感知修复网络和V2V注意力模块,5)分类和回归头。
LC感知修复网络和V2V注意力模块.从周围其他CAV聚合的中间特征被输入到我们框架的主要组件中,即LC-Aware修复网络,用于使用张量滤波在有损通信中恢复中间特征图,以及V2V注意力模块,用于利用注意力机制进行迭代的车辆间和车辆内特征融合.
LC-aware Repair Network
LC感知修复网络的框架如图3所示,该网络是一种具有跳跃连接的编码器-解码器架构。该网络生成一个特定的每个张量过滤器内核,以共同对齐和恢复输入损坏的特征,以生成输出特征的恢复版本。LC感知修复网络的输入特征为S ∈ R^c×h×w^,然后生成一个张量核K并应用于S,以产生恢复的输出特征ˆ S ∈ R^c×h×w^。
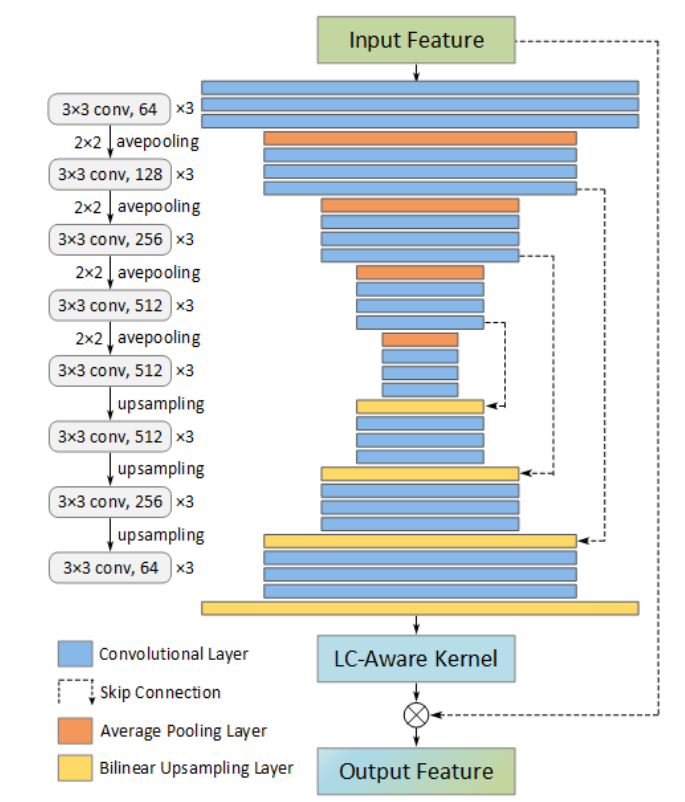
LC感知修复网络的输入特征为S ∈ R^c×h×w^,然后生成一个张量核K并应用于S,以产生恢复的输出特征ˆ S ∈ R^c×h×w^。
LC 感知修复损失函数 L~LC~( ˆ S, ˆ S^g^) 是遭受有损通信之前的真值原始特征 ˆ S^g^ 与修复特征 ˆ S 之间的张量 L1 距离。
V2V Attention Module
自注意力的关键思想是将某个位置的响应计算为所有位置的特征的加权总和,特征之间的相互作用由特征本身决定,而不是像卷积那样由它们的相对位置决定。
通过考虑有损通信情况,设计了一种定制化的车内和车间注意力融合方法,以增强自我CAV与其他CAV之间的交互.此外,我们在提出的V2V注意力方法中采用了纵横交错的注意力模块,可以利用该模块更有效地从全功能依赖关系中捕获上下文信息。
仅对于ego车辆,车内注意力模块可以使任何位置的特征进行全局感知,从而享受全图像上下文信息,以更好地捕捉代表性特征。从形式上讲,让 H^e^ ∈ R^C×H×W^ 成为自我车辆的输入特征图,它是自我车辆生成的完美数据,不会遭受任何有损通信。
在车内注意力模块中,特征图H^e^将由三个1×1卷积层计算,分别产生三个特征向量Qe、Ke和Ve,其中所有特征向量都具有相同的大小,{Q^e^,K^e^,V^e^}∈R^C×H×W^。按照中的缩放点积注意力,我们计算了Q^e^和K^e^的点积,然后使用比例因子(即特征向量的维度)将它们除以,并应用softmax函数来获得V^e^上的权重。
在V2V协同感知中,从其他CAV聚合而来的中间特征图H^s^∈R^C×H×W^被共享给ego车辆。具有有损通信的共享特征图Hs将被LC感知修复网络恢复,但它们在一定程度上仍然有噪声,而ego特征图H^s^是完美的.
针对这一问题,该文考虑恢复特征图的不确定性,提出一种不确定性感知的车间注意力融合方法。
在该模块中,共享特征图将由两个 1 × 1 卷积层计算,分别产生两个特征向量 K^s^ 和 V^s^,其中它们都具有相同的大小,{Ks, Vs} ∈ R^C×H×W^,另一个特征向量 Q^e^ 直接从自我车辆而不是其他车辆获得.
Efficient Implementation
采用两个连续的纵横交错(CC)注意力模块来实现点云数据中的V2V注意力,而不是缩放的点积注意力,减小计算量.
在获得车内注意力和车间注意力后,将它们分别输入到最大池化层和平均池化层,以获得丰富的空间信息,然后将它们串联为具有ReLU激活函数的二维卷积层的输入。
总结
感觉融合了cobev和coalign两篇文章.在代码上主要使用了ego的q和其他车的k,v计算注意力,而且计算注意力使用Criss-Cross Attention,然后使用max和mean再通过一个卷积.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107class V2V_AttFusion(nn.Module):
def __init__(self, feature_dim):
super(V2V_AttFusion, self).__init__()
self.cov_att = nn.Sequential(
nn.Conv2d(in_channels=feature_dim, out_channels=feature_dim, kernel_size=3, padding=1),
nn.BatchNorm2d(feature_dim,eps=1e-5, momentum=0.01, affine=True),
nn.ReLU()
)
self.CCNet = CrissCrossAttention(feature_dim)
def forward(self, x, record_len):
split_x = self.regroup(x, record_len) #x =[5, 64, 100, 352], record_len=[3,2]
out = []
att = []
for xx in split_x:#split_x[0] [num_car, C, W, H]
''' CCNet: Criss-Cross Attention Module: attention for ego vehicle feature + cav feature '''
ego_q, ego_k, ego_v = xx[0:1], xx[0:1], xx[0:1]
for i in range(len(xx[:,0,0,0])):
att_vehicle = self.CCNet(ego_q, xx[i:i+1], xx[i:i+1])
att.append(att_vehicle)
pooling_max = torch.max(torch.cat(att, dim=0), dim=0, keepdim=True)[0]
pooling_ave = torch.mean(torch.cat(att, dim=0), dim=0, keepdim=True)[0]
fuse_fea = pooling_max + pooling_ave
fuse_att = fuse_fea
fuse_att = self.cov_att(fuse_att)
out.append(fuse_att) #[[1, 64, 100, 352], [1, 64, 100, 352]]
# torch.cuda.empty_cache()
return torch.cat(out, dim=0) #[2, 64, 100, 352]
def regroup(self, x, record_len):
cum_sum_len = torch.cumsum(record_len, dim=0)
split_x = torch.tensor_split(x, cum_sum_len[:-1].cpu())
return split_x
class CrissCrossAttention(nn.Module):
""" Criss-Cross Attention Module
reference: https://github.com/speedinghzl/CCNet
"""
def __init__(self, in_dim):
super(CrissCrossAttention,self).__init__()
self.query_conv = nn.Sequential(
nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1),
nn.BatchNorm2d(in_dim,eps=1e-5, momentum=0.01, affine=True),
nn.ReLU()
)
self.key_conv = nn.Sequential(
nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1),
nn.BatchNorm2d(in_dim,eps=1e-5, momentum=0.01, affine=True),
nn.ReLU()
)
self.value_conv = nn.Sequential(
nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1),
nn.BatchNorm2d(in_dim,eps=1e-5, momentum=0.01, affine=True),
nn.ReLU()
)
self.softmax = Softmax(dim=3)
self.INF = INF
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, query, key, value):
m_batchsize, _, height, width = query.size()
proj_query = self.query_conv(query)
proj_query_H = proj_query.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height).permute(0, 2, 1)
proj_query_W = proj_query.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width).permute(0, 2, 1)
proj_key = self.key_conv(key)
proj_key_H = proj_key.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_key_W = proj_key.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width)
proj_value = self.value_conv(value)
proj_value_H = proj_value.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_value_W = proj_value.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width)
energy_H = (torch.bmm(proj_query_H, proj_key_H)+self.INF(m_batchsize, height, width)).view(m_batchsize,width,height,height).permute(0,2,1,3)
energy_W = torch.bmm(proj_query_W, proj_key_W).view(m_batchsize,height,width,width)
concate = self.softmax(torch.cat([energy_H, energy_W], 3))
att_H = concate[:,:,:,0:height].permute(0,2,1,3).contiguous().view(m_batchsize*width,height,height)
att_W = concate[:,:,:,height:height+width].contiguous().view(m_batchsize*height,width,width)
out_H = torch.bmm(proj_value_H, att_H.permute(0, 2, 1)).view(m_batchsize,width,-1,height).permute(0,2,3,1)
out_W = torch.bmm(proj_value_W, att_W.permute(0, 2, 1)).view(m_batchsize,height,-1,width).permute(0,2,1,3)
return self.gamma*(out_H + out_W) + value
Adaptive Feature Fusion for Cooperative Perception using LiDAR Point Clouds 2023
Abs
提出了具有可训练特征选择模块的自适应特征融合模型。我们提出的一个模型空间自适应特征融合(S-AdaFusion)在OPV2V数据集的两个子集上优于所有其他最先进的(SOTA):用于车辆检测的默认CARLA Towns和用于域适应的Culver City.
此外,以前的研究只测试了车辆检测的协同感知。然而,行人在交通事故中受重伤的可能性要大得多。
我们使用 CODD 数据集评估了车辆和行人检测的协同感知性能。我们的架构在 CODD 数据集上实现了比其他现有模型更高的车辆和行人检测平均精度 (AP)。实验表明,与传统的单车感知过程相比,协同感知也提高了行人检测的准确率。
LiDAR 可以生成包含准确深度信息的点云数据,并且受外部照明条件的影响较小。然而,远离LiDAR的点云非常稀疏,这使得探测其他物体变得更加困难。
感知到的信息可以包括 GPS 和各种传感器数据,包括雷达、摄像头和激光雷达数据。协同感知有助于弥补当前视觉感知技术的局限性,例如分辨率有限、天气效应和盲点。
首先,4个CAV处理其LiDAR点云,并在其本地系统中并行提取中间特征图。接下来,其他三个CAV将其提取的特征图连同LiDAR姿态信息一起广播到CAV1。然后,CAV1 将三个特征图投影到自己的坐标系,并将信息与自己的感知信息聚合在一起,用于 3D 目标检测。
根据CAV之间共享的数据类型,现有文献中发现了三种数据融合方法:1)早期融合聚合了来自其他CAV的原始输入传感器数据;
2)中间融合聚合了来自其他CAV的处理后的特征图;
3)后期融合聚合了来自其他CAV的目标检测的预测输出。
在最近的研究中,与早期和晚期融合方法相比,中间特征融合已被证明是最有效的融合方法。我们假设通过实现有效的特征选择和融合模块,降低计算成本,可以进一步改进中间融合方法,以实现实时感知和更高的准确性.
我们提出了几种具有可训练神经网络的特征融合模型,这些模型可以从多个CAV中自适应地选择特征
这项工作的贡献如下:1)我们创建了一个具有中间融合的轻量级协作感知架构;2)利用3D CNN和自适应特征融合进行协同感知,提出3种可训练的特征融合模型进行协同感知;3)我们使用两个公共合作感知基准数据集(OPV2V数据集[27]和CODD数据集[2])验证了所提出的模型,用于多个任务,包括a)车辆检测,b)行人检测和c)领域适应;4)我们尝试了不同数量的CAVs,以观察其对合作感知的影响
从形式上讲,合作感知的问题可以描述如下。我们将来自一组周围 CAV 的原始输入数据(相机数据和 LiDAR 数据)表示为 I = {I1, I2, . . . , In},表示为 V = {v1, v2, . . . , vn}。输入数据的相应提取中间特征集表示为 F = {F1, F2, . . . , Fn},其中目标检测器预测的输出集表示为 O = {O1, O2, . . . , On}。在传统的视觉感知过程中,AV vi 接收来自摄像头和激光雷达等传感器的原始数据 Ii。然后对这些数据进行处理以提取特征图 Fi,以用于计算模型中用于预测对象作为输出 Oi。在协同感知中,应用额外的数据融合步骤来聚合来自其他车辆的数据,以改善感知。
中间融合是利用已处理的中间特征表示 F 的折衷方案。因此,准确和优化地集成和处理从不同位置获得的信息对于有效的特征融合以实现准确的目标检测至关重要。
Marvasti等将3D LiDAR点云扭曲为鸟瞰图(BEV),并应用2D CNN提取每个连接的AV中的中间特征。来自 CAV 的特征图被投影到自我车辆的坐标系上。然后将这些与自我车辆的特征图聚合在一起。在中,只使用了两个CAV,求和使重叠具有更大的权重,而在现实生活中,CAV的数量各不相同。我们计算重叠处的平均值。
Chen等提出了特征级融合方案,选择重叠处的最大值来表示中间特征。
上面提到的模型使用简单的约简算子,例如求和、最大池化或平均池化。这些算子能够处理重叠处的信息,并以可以忽略不计的计算成本融合特征图。然而,由于缺乏信息选择和数据相关性的识别,所选择的特征不一定是最好的。
在V2VNe中,应用图神经网络(GNN)基于地质坐标表示CAV地图,以促进数据融合。GNN 将从多辆车接收到的信息与车辆的内部状态(根据其自己的传感器数据计算)聚合在一起,以计算更新的中间表示。
Xu等提出了AttFuse,并利用自注意力模型融合了中间特征图。V2X-Vit 和 CoBEVT 中使用了 Transformer,用于与中间特征融合的协同感知。
我们探索了特征融合模型,这些模型可以有效和高效地利用CAV的多个特征图。
Feature Learning and Feature Fusion
注意力机制在解决计算机视觉任务中已经证明了它的实用性。通过在神经网络中加入一个小模块,该模型可以利用通道和/或空间信息,并增强提取的表示。
在协同感知中,通过特征通道连接中间特征图会随着CAV数量的增加而大大增加计算成本。因此,与其连接特征图并创建超大型特征提取网络,不如将特征图与几何和地理信息聚合起来更有效。
Overview of the Proposed Framework
整个网络以点云为输入,分5个步骤对数据进行处理:
1)特征编码利用支柱特征网络(PFN)将点云转换为伪图像;
2)中间特征提取利用二维金字塔网络从伪图像中提取多尺度特征;
3)特征投影将CAV的中间特征图投射到与LiDAR姿态信息协调的ego车辆上;
4)中间特征融合生成具有特征融合网络的组合特征图;
5)3D目标检测使用单次检测器(SSD)对边界框进行回归,并预测检测到的对象的类别。
Feature Encoding
维度为(n×4)的输入点云由n个点组成,每个点具有属性(x、y、z)坐标和强度。
点云被编码为柱子,其高度等于z轴上的点云高度。每个柱子中的点都增加了 5 个额外的属性,包括柱子中所有点的算术平均值的偏移量和柱子中心的偏移量。将点云数据转换为P柱,每个柱子具有N个点和D个特征然后将 PointNet 应用于柱子上以提取特征并生成大小的张量 (C~in~ × P )。具有 C~in~ 特征的柱子被投射回原始位置,以生成大小的伪像 (C~in~ × 2H × 2W)。我们在这里使用 2H 和 2W,因为我们在下一个特征提取步骤中将特征图下采样为 (C × H × W )。
Feature Extraction
FPN 包含三个用于多分辨率特征提取的下采样模块。每个模块包含一个 2D 卷积层、一个批量归一化层和一个 ReLU 激活函数。
然后,对从三个下采样模块获得的三个特征图进行上采样和连接。由CNN对得到的多尺度特征图进行细化,以生成大小为F ′ ∈ RC×H×W的特征图。
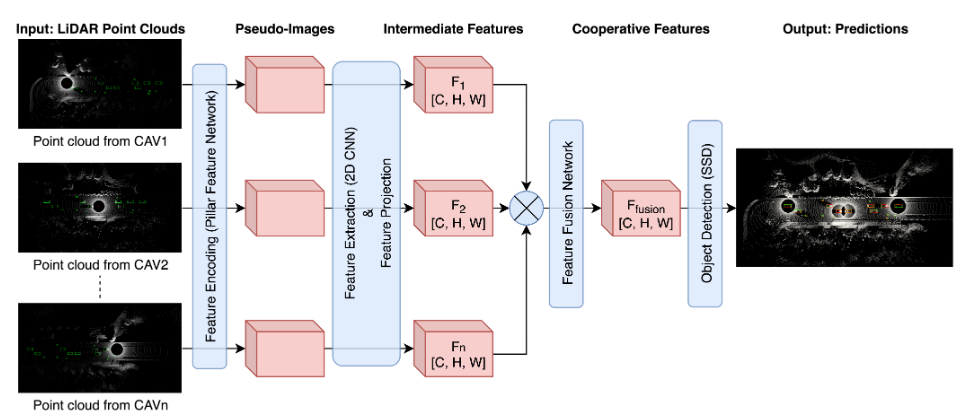
Feature Projection
从不同CAV中提取的特征图具有不同的地质位置和方向。因此,需要将它们转换为接收机的坐标系,以进行特征融合和目标检测。CAV 传播特征图及其 LiDAR 姿态信息,其中包含(X、Y、Z、滚动、偏航、俯仰)。一旦自我车辆从相邻的CAV接收到数据,它就会被投射到自我车辆的坐标系和时间戳中。
Feature Fusion
来自不同 CAV 的投影中间特征图被扩展为 4D 张量并连接起来进行进一步处理。在特征通道上连接特征图会生成具有 nC 通道的 3D 张量,这将增加计算复杂性和特征融合和细化的成本。因此,我们将特征图聚合为一个 4D 张量 F ∈ R^n×C×H×W^,其中 n 是 CAV 的最大数量。为了融合地质坐标系中的重叠特征图,我们提出了空间和通道特征融合模型
我们提出的特征融合模型分为空间特征融合和通道特征融合。
Spatial-wise Feature Fusion。为了融合特征图,将直接的约简算子(如Max或Mean)应用于重叠的特征,如图3a所示。本文将这两种融合方法称为MaxFusion和AvgFusion,它们分别在通道轴上计算最大池化和平均池化,得到融合特征图Ffusion ∈ R^1×C×H×W^
受信道注意力模块SENet的启发,提出了一种信道自适应特征融合(C-AdaFusion)模块,该模块可以利用信道信息选择和融合中间特征图。

首先,通过计算沿第一通道轴的最大池化和平均池化,将输入特征图F ∈ R^n×C×H×W^分解为Smax ∈ R^1×C×H×W^和Savg ∈ R^1×C×H×W^。
将两个特征图连接在一起,得到一个四维张量F~spatial~ ∈ R^2×C×H×W^,其中包含来自原始级联中间特征图的两种空间信息。然后,利用具有ReLU激活函数的三维卷积进行进一步的特征选择和降维,输入通道数和输出通道数分别等于2和1.
Channel-wise Feature FusionCNN 在从表示中提取特征并减小其维度方面表现非常出色。对于输入的 4D 张量 F ∈ R^n×C×H×W^,可以使用 3D CNN 提取通道特征并减少输入特征通道的数量。3D CNN 的输入通道数将等于单个输出通道表示组合特征集的最大 CAV 数。
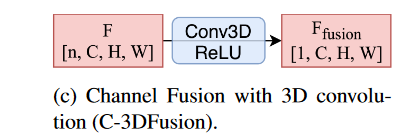
根据这两种不同的attention提出了c-AdaFusion.利用 3D 自适应最大池化和平均池化来提取两个通道描述符 C~max~ ∈ R^n×1×1×1^ 和 C~avg~ ∈ R^n×1×1×1^。然后,将两个向量连接起来,分别通过两个具有ReLU和Sigmoid激活函数的线性层。输入特征图F ∈ R^n×C×H×W^ 通道相乘学习的通道权重 F ′ 通道∈ R^n×1×1×1^,以生成新的特征表示 F ′ ∈ R^n×C×H×W^。融合特征图F~fusion~ ∈ R^1×C×H×W^是利用通道缩减3D CNN得到的。

总结
主要是利用了通道以及空间的fusion.我是打算再结合transformer做的.
where2comm 2022
abs
多智能体协同感知可以使智能体通过通信相互共享互补信息,从而显著提升感知性能。
这不可避免地导致感知性能和通信带宽之间的基本权衡。为了解决这一瓶颈问题,我们提出了一种空间置信度图,该图反映了感知信息的空间异质性。它使智能体能够只共享空间稀疏但感知上至关重要的信息,从而有助于沟通的位置。
基于这种新颖的空间置信度图,我们提出了一种通信效率高的协作感知框架Where2comm。有两个明显的优势:
i)它考虑了语用压缩,并通过专注于感知关键区域来使用更少的通信来实现更高的感知性能;
ii)通过动态调整通信所涉及的空间区域,可以处理不同的通信带宽。为了评估 Where2comm,我们考虑了在真实世界和模拟场景中的 3D 目标检测,在四个数据集上使用两种模态(摄像头/激光雷达)和两种代理类型(汽车/无人机):OPV2V、V2X-Sim、DAIR-V2X 和我们原始的 CoPerception-UAV。
intro
协作感知使多个智能体能够相互共享互补的感知信息,从而促进更全面的感知。它提供了一个新的方向,从根本上克服了单智能体感知的一些不可避免的局限性,如遮挡和远距离问题。在广泛的实际应用中迫切需要相关的方法和系统,例如车联网通信辅助自动驾驶、多机器人仓库自动化系统和用于搜救的多无人机。为了实现协作感知,最近的工作贡献了高质量的数据集和有效的协同方法。
在这个新兴领域,目前最大的挑战是如何优化感知性能和通信带宽之间的权衡。现实世界中的通信系统总是受到限制,以至于它们几乎无法承受巨大的实时通信消耗,例如通过完整的原始观测或大量特征。
以前的工作都做出了一个合理的假设:一旦两个智能体合作,他们就有义务平等地共享所有空间区域的感知信息。这种不必要的假设会极大地浪费带宽,因为很大一部分空间区域可能包含与感知任务无关的信息。为了填补这一空白,我们考虑了一种新颖的空间置信度感知沟通策略。其核心思想是为每个智能体启用空间置信度图,其中每个元素都反映了相应空间区域的感知临界水平。根据此地图,智能体决定要通信的空间区域(位置)。
Where2comm 包括三个关键模块:
i) 空间置信度生成器,它生成空间置信度图以指示感知关键区域;
ii)空间置信度感知通信模块,利用空间置信度图通过新型消息打包决定在何处进行通信,以及通过新型通信图构建来向谁进行通信;
iii)空间置信感知消息融合模块,该模块使用新颖的置信感知多头注意力来融合从其他智能体接收到的所有消息,从而升级每个智能体的特征图。
Where2comm有两个明显的优势。首先在特征层面促进了语用压缩,并通过专注于感知关键区域,使用更少的通信来实现更高的感知性能。其次,它适应各种通信带宽和通信轮数,而以前的型号只能处理一个预定义的通信带宽和固定数量的通信轮数。
问题定义
考虑场景中的 N 个代理。让 X~i~ 和 Y~i~ 分别是第 i 个智能体的观察和感知监督。协作感知的目标是实现所有智能体的感知性能最大化,作为总通信点 B 和通信轮 K 的函数
在这项工作中,我们考虑了3D目标检测的感知任务,并提出了三个贡献:
i)我们通过设计紧凑的消息和稀疏的通信图使通信更加高效;
ii)我们通过实施更全面的信息融合来提高感知性能;
iii) 我们通过动态调整沟通地点和人员,使整个系统能够适应不同的沟通条件。
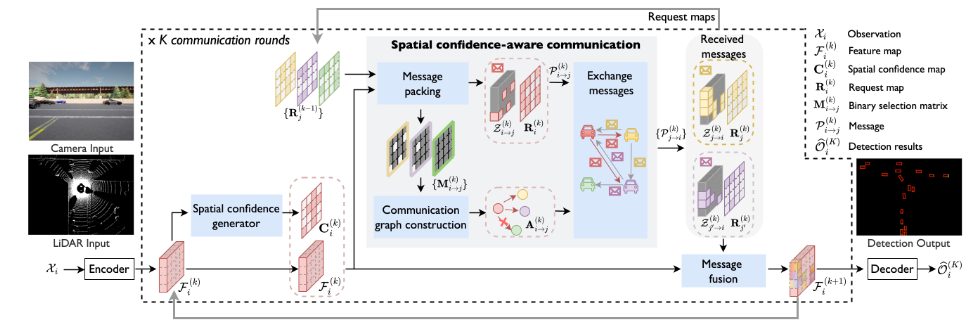
observation encoder从传感器数据中提取特征图。Where2comm 接受单模态/多模态输入,例如 RGB 图像和 3D 点云。这项工作采用鸟瞰图(BEV)中的特征表示,其中所有智能体将其个人感知信息投射到同一个全局坐标系,避免了复杂的坐标变换,并支持更好的共享跨智能体协作。
Spatial confidence generator空间置信度图反映了各个空间区域的感知临界水平。直观地说,对于物体检测任务,包含物体的区域比背景区域更关键。在协作过程中,由于视野有限,有对象的区域可以帮助恢复误检对象;可以省略背景区域以节省宝贵的带宽。因此,我们用检测置信度图表示空间置信度图,其中感知临界水平高的区域是包含置信度得分高的对象的区域。
传感器位置编码表示每个智能体的传感器与其观察点之间的物理距离。它采用以感应距离和特征尺寸为条件的标准位置编码功能。在输入到transformer之前,将这些特征与每个位置的位置编码相加。
与现有不使用注意力机制或仅使用智能体级注意力的融合模块相比,所提出的融合所采用的每位置注意力机制强调位置特异性特征交互。它使特征融合更具针对性。与同样使用基于每个位置注意力的融合模块的方法相比,所提出的融合模块利用了具有两个额外先验的多头注意力,包括空间置信度图和感知距离。两者都有助于注意力学习,以偏爱高质量和关键功能
空间置信度感知消息融合的目标是通过聚合从其他代理接收到的消息来增强每个代理的功能。为了实现这一点,我们采用了 transformer 架构,该架构利用多头注意力来融合来自每个单独空间位置的多个智能体的相应特征
Spatial confidence-aware message fusion
总结很好的一篇论文,利用了其他车的输出作为confidence map再结合多头注意力进行协同感知.
V2X-ViT: Vehicle-to-Everything Cooperative Perception with Vision Transformer 2022
这篇文章主要强调车与异构设备之间进行协同感知,提出新的改进的注意力机制,所以这里就不着重讲了.
- 我们提出了第一个用于V2X感知的统一Transformer架构(V2X-ViT),该架构可以捕获V2X系统的异构性,对各种噪声具有很强的鲁棒性。
- 此外,所提模型在具有挑战性的协同检测任务中取得了最先进的性能。– 我们提出了一种新型的异构多智能体注意力模块(HMSA),用于异构智能体之间的自适应信息融合。
- 我们提出了一种新的多尺度窗口注意力模块 (MSwin),该模块可同时并行捕获局部和全局空间特征交互。– 我们构建了 V2XSet,这是一个用于 V2X 感知的新的大规模开放仿真数据集,它明确地解释了不完美的现实世界条件。
OPV2V本文提出了Attentive Fusion
由于来自不同联网车辆的传感器观测结果可能带有不同的噪声水平(例如,由于车辆之间的距离),因此,一种既能关注重要观测值又能忽略中断观测值的方法对于稳健的检测至关重要。因此,我们提出了一个中间融合管道来捕捉相邻连接车辆特征之间的相互作用,帮助网络关注关键观测。
首先广播每个CAV的相对姿态和外在性,以构建一个空间图,其中每个节点都是通信范围内的一个CAV,每个边代表一对节点之间的通信通道。
构建图形后,将在组中选择一辆 ego 车辆. 所有相邻的 CAV 将自己的点云投射到自我车辆的 LiDAR 框架上,并根据投影的点云提取特征。这里的特征提取器可以是现有 3D 对象检测器的backbone.
采用自注意力模型来融合这些解压缩特征。同一特征图中的每个特征向量(对应于原始点云中的某些空间区域。因此,简单地展平特征图并计算特征的加权总和将破坏空间相关性。取而代之的是,我们为特征图中的每个特征向量构建一个局部图,其中边是为来自不同连接车辆的相同空间位置的特征向量构建的。
Cooper: Cooperative Perception for Connected Autonomous Vehicles based on 3D Point Clouds
Abs
自动驾驶汽车可能会因为检测和识别不准确而做出错误的决定。因此,智能车辆可以将自身数据与其他车辆的数据相结合,增强感知能力,从而提高探测精度和驾驶安全性。然而,多车协同感知需要整合真实世界的场景,而原始传感器数据交换的流量远远超过了现有车辆网络的带宽。据我们所知,我们是第一个对原始数据层面的合作感知进行研究,以提高自动驾驶系统的检测能力。
在这项工作中,我们以激光雷达三维点云为依托,融合从联网车辆的不同位置和角度收集的传感器数据。我们提出了一种基于点云的三维物体检测方法,可用于多种对齐点。
然而,到目前为止,人类驾驶的汽车与自动驾驶汽车之间的大多数比较都是不平衡的,包含各种不公平的因素。自动驾驶汽车不会感到疲劳、情绪衰弱,如愤怒或沮丧。但是,它们无法像细心和经验丰富的人类驾驶员那样,在不确定和模糊的情况下做出熟练的反应或预测
Proposed Solution
为了解决这个问题,我们研究了其中一个基础类别,即原始数据的低级融合。原始传感数据是自动驾驶汽车上所有传感器的组成部分,因此非常适合在不同制造商的不同汽车之间传输。因此,不同数据处理算法的异质性不会影响车辆之间共享数据的准确性。由于自动驾驶本身就是一项至关重要的任务,与车辆的集成度如此之高,即使是一个小小的检测错误也可能导致灾难性的事故。因此,我们需要自动驾驶汽车尽可能清晰地感知环境。为了实现这一最终目标,它们需要一个强大而可靠的感知系统。
在此过程中,我们要解决以下两个主要问题:(1) 我们需要在车辆之间共享的数据类型,以及 (2) 需要传输的数据量与接收车辆实际需要的数据量。
第一个问题是汽车数据集中的可共享数据。第二个问题是每辆车产生的数据量巨大。由于每辆自动驾驶汽车每天都会收集超过 1000GB 的数据,因此只收集区域数据变得更加困难。同样,重建附近感知系统从不同位置和角度收集的共享数据也是另一大挑战。
在不同类型的原始数据中,我们建议使用激光雷达(LiDAR)点云作为解决方案,原因如下:
- 与二维图像和视频相比,激光雷达点云具有空间维度的优势。
- 在保留感知对象的准确模型的同时,对实体或私人数据(如人脸和车牌号码)进行本机混淆。
- 由于数据是由点而不是像素组成的,因此在图像和视频融合过程中具有多功能性。对于图像或视频融合来说,要求有一个清晰的重叠区,而点云数据则不需要重叠区,这使得点云数据成为一种更稳健的选择,尤其是在考虑到汽车的不同视角时。
贡献
不准确的物体检测和识别是实现强大而有效的感知系统的主要障碍。自动驾驶汽车最终会屈服于这种能力,无法实现预期结果,这对自动驾驶是不安全的。为了解决这些问题,我们提出了一种解决方案,即自动驾驶车辆将自身的感知数据与其他联网车辆的感知数据相结合,以帮助增强感知能力。我们还认为,如前所述,数据冗余是解决这一问题的方法,我们可以通过自动驾驶车辆之间的数据共享和组合来实现。我们提出的 Cooper 系统可以提高探测性能和驾驶体验,从而提供保护和安全。具体来说,我们的贡献如下:
- 我们提出了稀疏点云物体检测(SPOD)方法,用于检测低密度点云数据中的物体。虽然 SPOD 是针对低密度点云设计的,但它也适用于高密度激光雷达数据。
- 我们展示了所提出的 Cooper 系统如何通过扩大感知区域和提高检测精度来超越单个感知。
- 我们证明,可以利用现有的车载网络技术来促进车辆之间兴趣区域 (ROI) 激光雷达数据的传输,从而实现合作感知。
鉴于当前自动驾驶汽车数据融合领域的前景和工作,我们需要更进一步,定义我们眼中的合作传感。我们认为,自动驾驶汽车的合作传感将带来一系列挑战和益处,这将是发展过程中不可避免的一部分。
F-Cooper: Feature based Cooperative Perception for Autonomous Vehicle Edge Computing System Using 3D Point Clouds
Abs
自动驾驶汽车在很大程度上依赖于传感器来完善对周围环境的感知,然而,就目前的技术水平而言,汽车所使用的数据仅限于来自自身传感器的数据.车辆和/或边缘服务器之间的数据共享受到可用网络带宽和自动驾驶应用严格的实时性限制。
为了解决这些问题,我们为联网自动驾驶汽车提出了基于点云特征的合作感知框架(F-Cooper),以实现更高的目标检测精度。
基于特征的数据不仅足以满足训练过程的需要,我们还利用特征的固有小尺寸来实现实时边缘计算,而不会面临网络拥塞的风险。
我们的实验结果表明,通过融合特征,我们能够获得更好的物体检测结果,20 米内的检测结果提高了约 10%,更远距离的检测结果提高了 30%,同时还能以较低的通信延迟实现更快的边缘计算,在某些特征选择中只需 71 毫秒。
Intro
互联自动驾驶汽车(CAV)为改善道路安全提供了一个前景广阔的解决方案。这有赖于车辆能够实时感知路况并精确探测物体。
然而,准确和实时的感知在现场具有挑战性。它需要处理来自各种传感器的大量连续数据流,并有严格的时间要求。此外,车辆的感知精度往往会受到传感器有限视角和范围的影响。
Proposed Solution
我们提出的方法可以提高自动驾驶车辆的检测精度,同时不会带来太多的计算开销。一个有益的启示是,现代自动驾驶车辆的物体检测技术,无论是基于图像的还是基于三维激光雷达数据的,通常都采用卷积神经网络(CNN)来处理原始数据,并利用区域建议网络(RPN)来检测物体。我们认为,特征图的能力尚未得到充分挖掘,特别是对于自动驾驶车辆上生成的 3D LiDAR 数据,因为特征图仅用于单个车辆的物体检测。
为此,我们引入了基于特征的协同感知(FCooper)框架,利用特征级融合实现端到端的三维物体检测,从而提高检测精度。我们的 F-Cooper 框架支持两种不同的融合方案:体素特征融合和空间特征融合。
与原始数据级融合解决方案[3]相比,前者实现了几乎相同的检测精度提升,而后者则提供了动态调整待传输特征图大小的能力。F-Cooper 的独特之处在于它可以在车载和路边边缘系统上部署和执行。
除了能够提高检测精度外,特征融合所需的数据大小仅为原始数据的百分之一。对于一个典型的激光雷达传感器来说,每个激光雷达帧包含约 100,000 个点,约为 4 MB。对于任何现有的无线网络基础设施来说,如此庞大的数据量都将成为沉重的负担。
要确认特征对融合的有用性,我们必须回答以下三个基本问题。
1) 特征是否具备融合的必要手段?
2) 我们能否通过特征在自动驾驶车辆之间有效地交流数据?
3) 如果特征满足前面两个要求,那么我们从自动驾驶车辆中获取特征图的难度有多大?
Fusion Characteristics
受致力于融合不同层生成的特征图的研究成果(如特征金字塔网络(FPN) 和级联 R-CNN [2])的启发,我们发现在不同的特征图中检测物体是可能的。例如,FPN 采用自上而下的金字塔结构特征图进行检测。这些网络非常善于复合特征融合的效率。
从这些著作中汲取灵感,我们假设兼容融合的汽车将使用相同的检测模型。这一点非常重要,因为我们看到只有最可靠的检测模型才会被用于自动驾驶。有了这个假设,我们现在来看看融合的特点
Compression and Transmission
与原始数据相比,特征地图的另一个优势在于车辆之间的传输过程。原始数据可能有多种不同的格式,但它们都能达到一个目的,那就是保留所捕获数据的原始状态。例如,从驾驶过程中获取的激光雷达数据将存储驾驶过程中沿途的所有点云。不过,这种存储格式会将不必要的数据与基本数据一起记录下来;而特征地图则避免了这一问题.
在 CNN 网络处理原始数据的过程中,所有无关数据都会被网络过滤掉,只留下可能被网络用于物体检测的信息。这些特征图存储在稀疏矩阵中,只存储被认为有用的数据,任何被过滤掉的数据在矩阵中都存储为 0。
通过无损压缩(如 gzip 压缩方法),数据大小的优势会进一步扩大,如文献[14]所示。再加上稀疏矩阵的特性,我们就能将二者结合起来,实现压缩后的特征数据不超过 1 MB,使特征数据成为部署 On-Edge 融合的最佳选择。
Generic and Inherent Properties
所有自动驾驶车辆都必须根据传感器生成的数据做出决策。原始数据由车辆上的物理传感器生成,然后传送到车载计算设备。在那里,原始数据通过基于 CNN 的深度学习网络进行处理,最终做出驾驶决策。在此过程中,我们可以提取提取的特征进行共享。这样,我们就能有效地获得原始数据的特征图,而无需额外的计算时间或车载计算设备的功率。迄今为止,几乎所有已知的自动驾驶车辆都使用了基于 CNN 的网络,因此特征提取是通用的,在融合之前无需进一步处理。
得益于自动驾驶车辆处理数据的方式,我们能够直接从原始激光雷达点云数据中提取处理后的特征图进行融合,因为这本身就提供了位置数据。只要激光雷达传感器已经按照自动驾驶所需的标准进行了校准,那么我们就能获得能够保留所有物体与车辆相对位置的特征地图。
为了融合两辆汽车的三维特征,设计了两种融合范式:体素特征融合和空间特征融合。在范式 I 中,首先融合两组体素特征,然后生成空间特征图。
Voxel Features Fusion
与位图中的像素一样,体素代表三维空间中规则立方体上的一个数值。在一个体素内,可能有零个或多个由激光雷达传感器生成的点云。对于至少包含一个点的任何体素,VoxelNet 的 VFE 层可以生成一个体素特征
假设原始激光雷达检测区域被划分为一个体素网格。
在这些体素中,我们将获得绝大多数空体素,而剩余的体素则包含关键信息。所有非空的体素都会通过一系列全连接层进行转换,并转化为长度为 128 的固定大小的矢量。固定大小的向量通常被称为特征图。
为了提高内存/计算效率,我们将非空体素的特征保存到哈希表中,并将体素坐标作为哈希键。由于我们的重点主要是自动驾驶,因此我们只将非空体素存储到哈希表中。
在 VFF 中,我们明确地将来自两个输入的所有体素的特征结合起来。具体来说,来自汽车 1 的体素 3 和来自汽车 2 的体素 5 共享相同的校准位置。
虽然两辆车的物理位置不同,但它们共享同一个配准的三维空间,不同的偏移量表示每辆车在所述三维标定空间中的相对物理位置。为此,我们采用了element-wise maxout来融合体素 3 和体素 5。
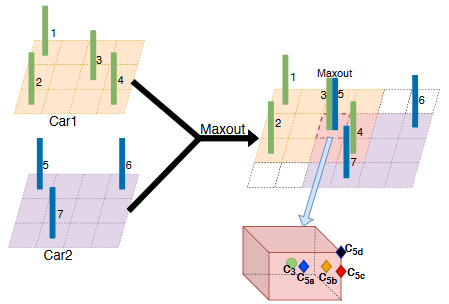
受卷积神经网络的启发,使用 maxout 进行潜在规模选择,提取明显的特征,同时抑制对三维空间检测无益的特征,从而实现更小的数据量。在我们的实验中,我们使用 maxout 来决定在比较车辆间的数据时哪个特征最突出。
Spatial Feature Fusion
VFF 需要考虑两辆车所有体素的特征,这涉及车辆之间的大量数据交换。为了进一步减少网络流量,同时保持基于特征融合的优势,我们设计了一种空间特征融合(SFF)方案。与 VFF 相比,SFF 融合的是空间特征图,与体素特征图相比,空间特征图更为稀疏,因此更容易压缩以进行通信。
与 VFF 不同,我们对每辆车上的体素特征进行预处理,以获得空间特征。接下来,将两个源空间特征融合在一起,并将融合后的空间特征转发给 RPN,以进行区域建议和目标检测。
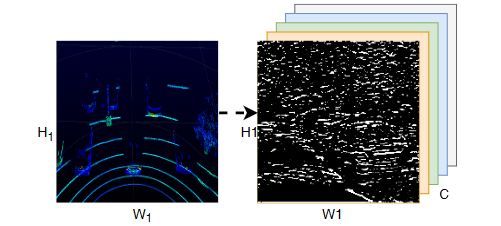
特征学习网络的输出是一个稀疏张量,其形状为 128 × 10 × 400 × 352。为了整合所有体素特征,我们采用了三个三维卷积层,依次获得语义信息更多的较小特征图,大小为 64 × 2 × 400 × 352。然而,生成的特征无法满足传统区域建议网络的形状要求。为此,必须将输出重新塑造为 128 × 400 × 352 大小的三维特征图,然后才能将其转发给 RPN。
对于 SFF,我们生成一个更大的检测范围,大小为 W × H,其中 W > W1,H > H1。接下来,对重叠区域进行融合,同时保留非重叠区域的原始特征。假设 GPS 将汽车 1 的实际位置记录为 (x1,y1),汽车 2 的实际位置记录为 (x2,y2),如果 x2 + H1, y2 - W1 2 属于 2 号车的特征图,而左上角代表 1 号车的特征图,那么我们就可以得到左上角的位置。那么我们就很容易确定重叠区域。与 VFF 采用 maxout 策略类似,我们在 SFF 中也采用了 maxout 来融合重叠的空间特征。
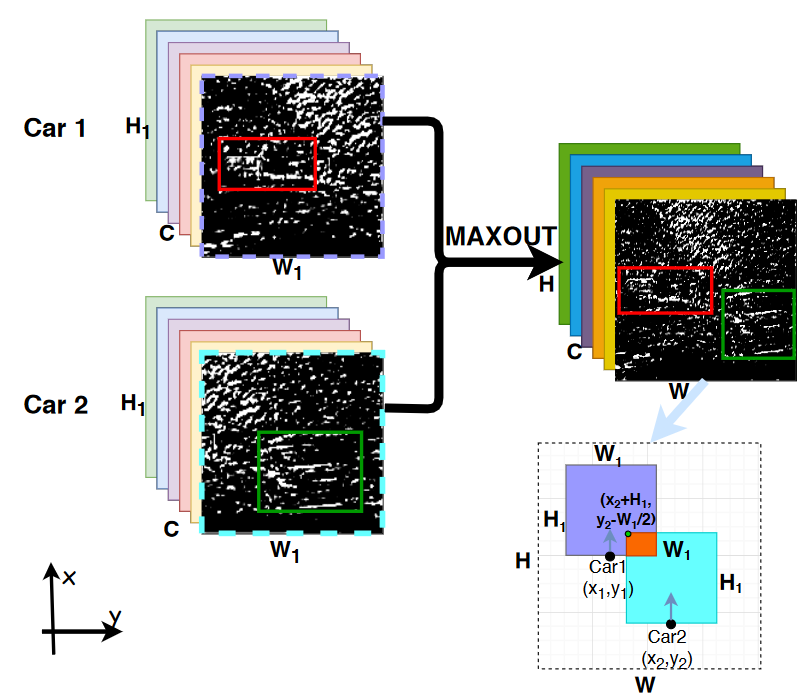
最后,我们采用区域建议网络在融合特征图上提出潜在区域。
SENet 等最新研究表明,不同的通道具有不同的权重。也就是说,特征图中的某些通道对分类/检测的贡献更大,而其他通道则是多余或不需要的。
选择从全部 128 个通道中选择部分通道进行传输。我们假定自动驾驶汽车装配了与实际应用中相同的训练有素的检测模型。
使用融合特征进行目标检测
为了检测车辆,我们将合成特征图输入区域建议网络(RPN)进行对象建议。然后应用损失函数进行网络训练。
区域建议网络
RPN:区域建议网络。不管是采用体素融合范式还是空间融合范式,当我们得到空间特征图后,都会将其送入区域提议网络(RPN)。通过 RPN 网络后,我们将得到两个损失函数的输出结果:
(1) 提议感兴趣区域的概率分数 p∈ [0, 1];
(2) 提议区域的位置 P = (Px , Pw , Pz , Pl , Pw , Ph, Pθ ) ,其中 Px , Py , Pz 表示提议区域的中心,(Pl , Pw , Ph, Pθ ) 分别表示长度、宽度、高度和旋转角度。
损失函数
损失函数由两部分组成:分类损失 Lcls 和回归损失 Lreg。

ground-truth bounding box,即gt-box表示为G = Gx , Gy, Gz, Gl , Gw , Gh, Gθ 其中,Gx , Gy , Gz 表示方框的中心点,(Gl , Gw , Gh, Gθ )分别表示长度、宽度、高度和偏航旋转角
输出的值包括
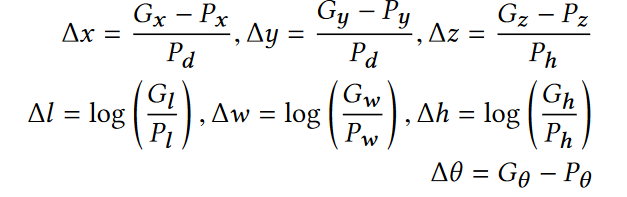
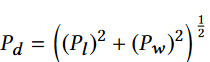
损失可以表示为
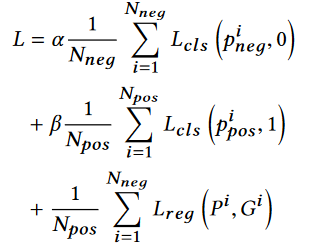
数据集
KITTI
由于我们的重点是三维物体检测,因此我们使用了 KITTI 数据集提供的三维 Velodyne 点云数据。
云点数据每帧提供 100K 个点,并存储在二进制浮点矩阵中。数据包括每个点的三维位置和相关的反射率信息。但是,由于 KITTI 数据是由单个车辆记录的,我们必须利用同一记录中的不同时间段来模拟由两辆车生成的数据。因此,KITTI 数据只适用于某些测试场景。
为了解决这个问题,我们在两辆名为汤姆和杰瑞(T&J)的车辆上安装了必要的传感器,如激光雷达(Velodyne VLP-16)、摄像头(Allied Vision Mako G-319C)、雷达(Delphi ESR 2.5)、IMU&GPS(Xsens MTi-G-710 套件)和边缘计算设备(Nvidia Drive PX2),以便在我们学校的校园内收集所需的数据。我们的车辆配有 16 波束 Velodyn 激光雷达传感器,以二进制原始以太网数据包的形式存储数据。由于我们的车辆可以相互独立移动,因此我们能够用两辆车在真实环境中测试各种场景。
训练细节
在停车场环境中,我们将距离车辆 20 米以内的物体视为高优先级物体,20 米以外的物体视为低优先级物体。
由于我们的激光雷达传感器只有 16 个光束,因此与更高端的激光雷达传感器相比,得到的点云数据相对稀疏。为了减轻稀疏数据带来的负面影响,我们将探测范围限制在沿 X、Y 和 Z 轴[0,70.4]X[-40,40] X [-3,1] 。我们不使用超出探测范围的数据。除了车辆的检测范围外,我们还将体素大小设置为 vD = 0.4 米、vH = 0.2 米、vW = 0.2 米,因此 D1 = 10、H1 = 400、W1 = 352。在我们的实验中,F-Cooper 框架在配备 GeForce GTX 1080 Ti GPU 的计算机上运行。
为了评估 F-Cooper,我们在实验中收集并测试了 200 多组数据。根据处理激光雷达数据的方法,我们将测试分为四类,方法(1)到(3)均来自相同的检测模型:(1)作为基线的非融合,(2)带有 VFF 的 F-Cooper,(3)带有 SFF 的 F-Cooper,以及(4)原始点云融合方法 - Cooper。特征融合在上述四种情况中随机进行,重点放在繁忙的校园停车场,因为由于遮挡物较多,这是最困难的情况。
后面结合OpenCood这个项目代码学习学习 ICRA 2022] An opensource framework for cooperative detection. Official implementation for OPV2V. (github.com)
Learning Distilled Collaboration Graph for Multi-Agent Perception 2021
abs
为了促进多智能体感知更好的性能-带宽权衡,我们提出了一种新的提取协作图(DiscoGraph)来建模智能体之间的可训练、姿势感知和自适应协作。我们的主要新颖之处在于两个方面。
数据集
目前找到的数据集还是不少的.
OPV2V 2022
推出了首个大规模开放式车对车感知模拟数据集。该数据集包含 70 多个有趣的场景、11,464 个帧和 232,913 个注释三维车辆边界框,收集自 CARLA 的 8 个城镇和洛杉矶卡尔弗城的一个数字城镇。然后,我们构建了一个包含 16 个实施模型的综合基准,以评估几种信息融合策略(即早期、后期和中间融合)与最先进的激光雷达检测算法。
V2XSet 2022
研究了如何应用 “车对物”(V2X)通信来提高自动驾驶汽车的感知性能。我们利用新颖的视觉转换器(Vision Transformer)提出了一个具有 V2X 通信功能的稳健合作感知框架。具体来说,我们建立了一个整体注意力模型,即 V2X-ViT,以有效融合道路代理(即车辆和基础设施)之间的信息。V2X-ViT 由异构多代理自我注意和多尺度窗口自我注意交替层组成,可捕捉代理间的交互和每个代理的空间关系。这些关键模块采用统一的 Transformer 架构设计,以应对常见的 V2X 挑战,包括异步信息共享、姿势错误和 V2X 组件的异构性。
车与道路 CARLA和OPENCDA创建的模拟数据集
DAIR-V2X 2022
为了加速车辆-基础设施协同自动驾驶(VICAD)的计算机视觉研究和创新,我们发布了 DAIR-V2X 数据集,这是首个用于 VICAD 的大规模、多模态、多视角真实场景数据集。
V2X-Sim 2022
车对物(V2X)通信技术实现了车辆与邻近环境中许多其他实体之间的协作,可以从根本上改善自动驾驶的感知系统。然而,公共数据集的缺乏极大地限制了协同感知的研究进展。为了填补这一空白,我们提出了 V2X-Sim—一个用于 V2X 辅助自动驾驶的综合模拟多代理感知数据集。V2XSim 提供:(1)来自路边装置(RSU)和多辆车的多代理传感器记录,可实现协同感知;(2)多模态传感器流,可促进多模态感知;以及(3)多种地面实况,可支持各种感知任务。同时,我们建立了一个开源测试平台,并在检测、跟踪和分割等三个任务上为最先进的协同感知算法提供了基准。V2X-Sim 试图在现实数据集广泛可用之前,促进自动驾驶的协同感知研究。
V2V4Real 2023
最近的研究表明,车对车(V2V)协同感知系统在彻底改变自动驾驶行业方面具有巨大潜力。然而,真实世界数据集的缺乏阻碍了这一领域的发展。为了促进协同感知的发展,我们提出了 V2V4Real,这是首个大规模真实世界多模态 V2V 感知数据集。
