最近大语言模型及其相关应用实在是太火了,可以在一些公司或者个人博客查看最前沿进展,也可以通过代码项目、课程学习,还可以看看经典论文.这里就看看一些LLM的论文学习学习.
下面论文都可以在Arxiv上找到.
A Survey of Large Language Models
这篇文章有80多页,引用有40页.
Scaling laws
KM scaling law
Scaling laws for neural language models首次提出了神经语言模型的模型性能与模型大小(N)、数据集大小(D)和训练计算量(C)三大因素的幂律关系模型。
$N{c}$、$D{c}$ 和 Cc 分别以非嵌入参数数、训练标记数和 FP 日数来衡量。
L(-) 表示 nats 中的交叉熵损失,OpenAI 的后续研究 表明,语言建模损失可分解为两部分,即不可还原损失(真实数据分布的熵)和可还原损失(真实分布和模型分布之间 KL 分歧的估计值)。
在一些假设条件下(如一个因素的分析不应受到其他两个因素的瓶颈限制),通过拟合不同数据量(2200 万到 2300 亿个 token)、模型大小(768 万到 1500 亿个非嵌入参数)和训练计算的模型性能,得出了这三个定律.他们的研究表明,模型性能与三个因素有很强的依赖关系.
Chinchilla scaling law
霍夫曼等人提出了另一种缩放定律形式,用于指导 LLM 的计算优化训练.其中E = 1.69, A = 406.4, B = 410.7, α = 0.34 and β = 0.28
通过优化 C ≈ 6N D 约束条件下的损失 L(N,D),他们证明了计算预算对模型大小和数据大小的最优分配如下
a = α/(α+β) , b = β/(α+β) ,G 是一个缩放系数,可由 A、B、α 和 β 计算得出。
涌现能力
在Emergent abilities of large language models中LLMs 的涌现能力被正式定义为 “在小型模型中不存在而在大型模型中出现的能力”,这是 LLMs 区别于以往 PLMs 的最显著特征之一。它进一步引入了出现突发性能力时的一个显著特征:当规模达到一定程度时,性能会明显高于随机水平。通过类比,这种突现模式与物理学中的相变现象有着密切联系。原则上,新兴能力可以根据某些复杂任务来定义,而我们更关注的是可用于解决各种任务的一般能力。
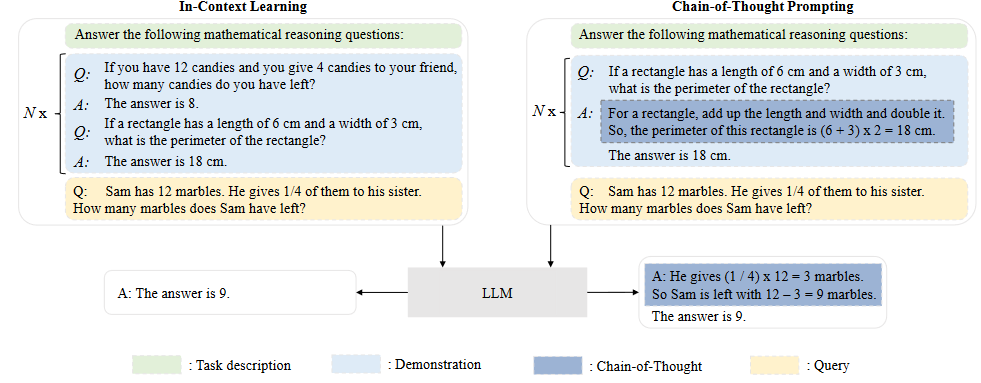
简要介绍 LLMs 的三种典型涌现能力以及具备这种能力的代表性模型: 1)In-context learning 2) Instruction following 3)step-by-step reasoning
GPT-3正式引入了语境中学习(ICL)能力:假设语言模型已经获得了自然语言指令和/或多个任务演示,那么它就可以通过完成输入文本的词序来生成测试实例的预期输出,而无需额外的训练或梯度更新。
通过对自然语言描述格式的多任务数据集进行微调(称为指令微调),LLM 在同样以指令形式描述的未见任务上表现出色。通过指令调整,LLMs 可以在不使用明确示例的情况下,根据任务指令完成新任务,从而提高泛化能力.
对于小型语言模型而言,通常很难解决涉及多个推理步骤的复杂任务,例如数学文字问题.相比之下,使用思维链(CoT)提示策略,LLM 可以利用提示机制来解决此类任务,这种机制涉及到推导最终答案的中间推理步骤.
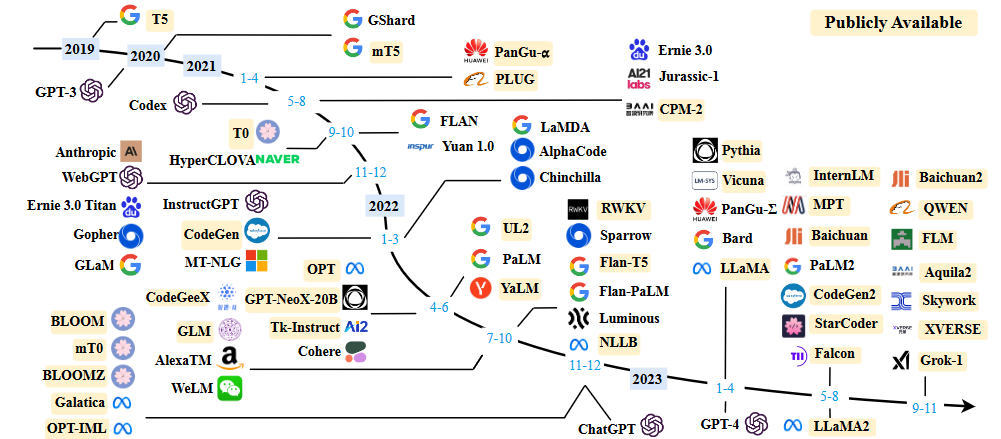
LLM 经过漫长的发展才达到了目前的状态:通用的、有能力的学习者。在发展过程中,人们提出了许多重要技术,这些技术在很大程度上提高了 LLM 的能力,包括scaling,training,ability eliciting,Alignment tuning等等.
PEFT方法
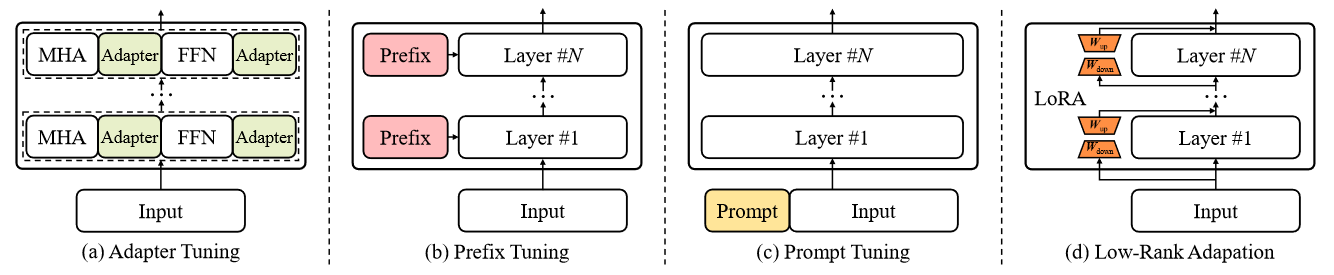
Prefix Tuning
Prefix Tuning在语言模型的每个transformer层中预置一系列前缀,这些前缀是一组可训练的连续向量.这些前缀向量是针对特定任务的,可视为虚拟标记嵌入。为了优化前缀向量,有人提出了一种重参数化技巧 ,即学习一个 MLP 函数,将一个较小的矩阵映射到前缀的参数矩阵,而不是直接优化前缀。
摘要
在本文中,我们提出了前缀调整技术,它是自然语言生成任务中微调技术的轻量级替代方案,可保持语言模型参数不变,但会优化一个小的连续任务特定向量(称为前缀).
Prefix-tuning draws inspiration from prompting, allowing subsequent tokens to attend to this prefix as if it were “virtual tokens”.
相当于让模型参数不变,优化连续的任务相关数据,让模型关注增加的前缀.
我们发现,只需学习 0.1% 的参数,前缀调整就能在全数据环境下获得与之相当的性能,在低数据环境下优于微调,并能更好地推断出训练期间未见过主题的示例.
方法
我们认为适当的语境可以在不改变 LM 参数的情况下引导 LM。例如,如果我们希望 LM 生成一个单词(如 Obama),我们可以将其常见搭配作为上下文(如 Barack)的前置词,这样 LM 就会为所需单词分配更高的概率。
我们可以将指令优化为连续的单词嵌入,而不是对离散的标记进行优化,其效果将向上传播到所有转换器激活层,并向右传播到后续标记。
前缀调整为自回归 LM 预置前缀,得到 z = [PREFIX;x;y],或为编码器和编码器预置前缀,得到 z = [PREFIX;x;PREFIX′;y]。

前缀调整初始化一个维度为 |$P{idx}$| × dim($h{i}$) 的可训练矩阵 $P{θ}$(参数为 θ),用于存储前缀参数.$P{idx}$ 表示前缀索引序列,我们用 |$P_{idx}$| 表示前缀长度.语言模型参数 φ 是固定的,前缀参数 θ 是唯一可训练的参数.
$h{i}$(对于所有 i)是可训练 $P{θ}$ 的函数。
Prefix Tuning是PEFT方法之一,Prefix Tuning之前的工作主要是人工设计模板或者自动化搜索模板,也是prompt范式的第一阶段,就是在输入上加上prompt文本,再对输出进行映射。这种离散模板对模型的鲁棒性很差。所以后续的研究都将离散的方式转成连续。Prefix Tuning在模型输入前添加一个连续的且任务特定的向量序列称之为prefix,固定PLM(预训练模型)的所有参数,只更新优化特定任务的prefix
P-tuning V1&&V2
提示调整只对使用冻结语言模型的连续提示进行调整,从而大大减少了训练时每个任务的存储和内存使用量.

在情感分析中,我们可以将样本(如 “了不起的电影!”)与提示语 “这部电影是[MASK]”连接起来,然后要求预先训练好的语言模型预测屏蔽标记为 “好 “和 “坏 “的概率,从而决定样本的标签.
提示法完全不需要训练,只需存储一份模型参数。
Prompt tuning2 是一种只对连续提示进行调整的想法.在原始输入词嵌入序列中添加可训练的连续嵌入(也称为连续提示)
P-Tuning v2(论文: P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks),该方法在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这带来两个方面的好处:
- 更多可学习的参数(从
P-Tuning和Prompt Tuning的0.01%增加到0.1%-3%),同时也足够参数高效。 - 加入到更深层结构中的
Promp能给模型预测带来更直接的影响
大模型的Prompt构造方式严重影响下游任务的效果。比如:GPT-3采用人工构造的模版来做上下文学习(in-context learning),但人工设计的模版的变化特别敏感,加一个词或者少一个词,或者变动位置都会造成比较大的变化
LoRA
自然语言处理的一个重要范式是在一般领域数据上进行大规模预训练,然后适应特定任务或领域。随着我们预训练的模型越来越大,重新训练所有模型参数的全面微调就变得不那么可行了。以 GPT-3 175B 为例,部署微调模型的独立实例(每个实例有 175B 个参数)的成本过高。我们提出了(Low-Rank Adaptation,简称 LoRA)技术,它可以冻结预训练模型权重,并将可训练的等级分解矩阵注入 Transformer 架构的每一层(injects trainable rank decomposition matrices into each layer of the Transformer architecture),从而大大减少下游任务的可训练参数数量.
LoRA 允许我们通过优化密集层在适应过程中的变化的秩分解矩阵来间接训练神经网络中的某些密集层,同时保持预先训练的权重不变.

神经网络包含许多执行矩阵乘法的密集层.这些层中的权重矩阵通常具有全秩。Aghajanyan 等人(2020)的研究表明,在适应特定任务时,预训练的语言模型具有较低的 “本征维度”,即使随机投影到较小的子空间,仍能高效学习.受此启发,我们假设权重更新在适应过程中也具有较低的 “本征等级”。
对于一个预先训练好的权重矩阵 $W{0}∈R^{d×k}$, d是满秩,r是低秩.我们用一个低秩分解 $W{0} + ∆W = W{0} + BA$ 来表示后者,其中 B∈$R{d×r}$, A∈$R_{r×k}$, 秩为 r<< min(d,k).
在训练过程中,$W_{0}$被冻结,不会接收梯度更新,而 A 和 B 则包含可训练参数.
注意,$W_{0}$ 和 ∆W = BA 都与相同的输入相乘.它们各自的输出向量按坐标相加.
对 A 使用随机高斯初始化,对 B 使用零初始化,因此训练开始时 ∆W = BA 为零.然后,我们用 α/r 对 $∆Wx$ 进行缩放,其中 α 是 r 中的一个常数.在使用Adam进行优化时,如果我们适当缩放初始化,调整 α 与调整学习率大致相同.因此,我们只需将 α 设为我们尝试的第一个 r,而无需调整.
1、选择目标层
2、初始化映射矩阵和逆映射矩阵
为目标层创建两个较小的矩阵A和B,然后进行变换
A是映射矩阵(一般用随机高斯分布初始化,维度上是降维)
B是逆映射矩阵(用0矩阵初始化),维度上是升维
之后做参数变换:将目标层的原始参数矩阵W通过映射矩阵A和逆映射矩阵B进行变换,计算公式为:W' = W + A * B,这里W'是变换后的参数矩阵
3、微调模型
使用新的参数矩阵W'替换目标层的原始参数矩阵W,然后在特定任务的训练数据上对模型进行微调
4、梯度更新
Adapter
适配器调整将小型神经网络模块(称为适配器)纳入transformer模型 .为了实现适配器模块,中提出了一种瓶颈架构,它首先将原始特征向量压缩到较小的维度(然后进行非线性变换),然后将其恢复到原始维度.

在 NLP 中,微调大型预训练模型是一种有效的传输机制。然而,在有许多下游任务的情况下,微调的参数效率很低:每个任务都需要一个全新的模型。作为替代方案,我们建议使用适配器模块进行转移。适配器模块产生了一个紧凑且可扩展的模型;它们只为每个任务添加少量可训练参数,并且可以添加新任务,而无需重新检查之前的任务。原始网络的参数保持不变,从而实现了高度的参数共享。
Prompt Tuning
Prompt Tuning主要侧重于在输入层加入可训练的提示向量.
在离散提示的情况下(Schick 和 Schütze, 2020),提示标记 {“它”、”是”、”[MASK]”} ⊂ V 可用来对电影评论进行分类。
Lester 等人引入了可训练连续提示,作为自然语言提示的替代,用于冻结预训练语言模型的参数的 NLU。给定可训练连续嵌入[h0, …, hi],输入嵌入序列被写成[e(x), h0, …, hi, e(“[MASK]”)], 事实证明,在简单的分类任务中,即时调整的效果与对百亿参数模型进行微调的效果相当.
%E7%B3%BB%E5%88%97%E8%AE%BA%E6%96%87%E6%80%BB%E7%BB%93/image-20240107102116261.png)
在这项工作中,我们探索了 “提示调整”,这是一种简单而有效的机制,用于学习 “软提示”,使冻结语言模型能够执行特定的下游任务。与 GPT-3 使用的离散文本提示不同,软提示是通过反向传播学习的,可以进行调整,以纳入来自任意数量标注示例的信号
Quantization方法
在模型压缩领域,量化已成为一种广受欢迎的技术,可减轻深度学习模型的存储和计算开销.传统表示法采用浮点数,而量化则将其转换为整数或其他离散形式.这种转换大大降低了存储要求和计算复杂度。虽然会有一些固有的精度损失,但仔细的量化技术可以在实现大量模型压缩的同时,将精度降低到最低程度.目前量化方法主要分为PTQ和QAT,前者不需要训练,后者需要数据重新训练,LLMs包含大量的参数,PTQ方法的计算成本远低于QAT方法,因而更受青睐。
这方面可以看看Short Courses | Learn Generative AI from DeepLearning.AI上的视频,质量很高.
在神经网络压缩中,量化通常指从浮点数到整数的映射过程,尤其是 8 位整数量化(即 INT8 量化).对于神经网络模型,通常有两类数据需要量化,即权重(模型参数)和激活(隐藏激活),这两类数据最初用浮点数表示。
为了说明模型量化的基本思想,介绍一个简单但常用的量化函数:$x{q} = R(x/S)-Z$,它将浮点数 x 转换为量化值 $x{q}$。在这个函数中,S 和 Z 分别表示缩放因子(涉及两个参数 α 和 β,决定clipping range和zero-point factor(决定对称或不对称量化),R(-) 表示四舍五入运算,将缩放浮动值转换为近似整数。作为逆过程,去量化相应地从量化值中恢复出原始值: x= S - (xq + Z)。量化误差计算为原始值 x 与恢复值 ̃ x 之间的数值差。范围参数 α 和 β 对量化性能有很大影响,通常需要根据实际数据分布进行静态(离线)或动态(运行时)校准。
经常使用的线性quantizaiton,
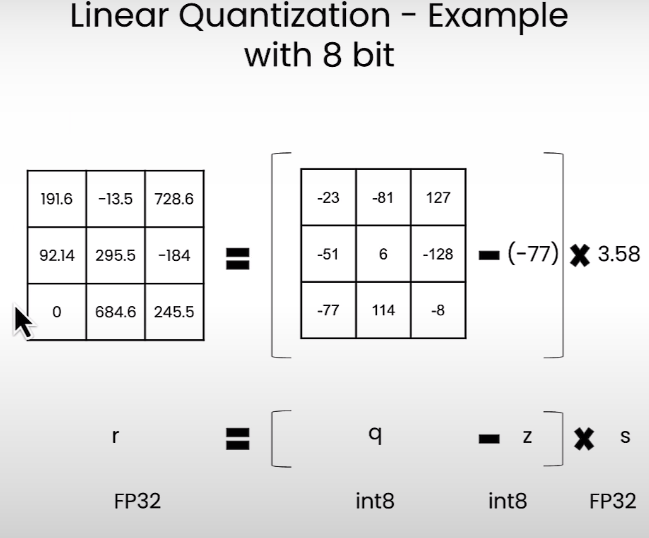
q=int(round(r/s+z))1
2
3
4
5
6
7
8
9
10
11
12
13def linear_q_with_scale_and_zero_point(
tensor, scale, zero_point, dtype = torch.int8):
scaled_and_shifted_tensor = tensor / scale + zero_point
rounded_tensor = torch.round(scaled_and_shifted_tensor)
q_min = torch.iinfo(dtype).min
q_max = torch.iinfo(dtype).max
q_tensor = rounded_tensor.clamp(q_min,q_max).to(dtype)
return q_tensor
这样得到量化后的结果再转回去与原本的差距,就是quantizaiton error.1
2
3
4
5
6
7
8
9
10
11
12
13
14### a dummy tensor to test the implementation
test_tensor=torch.tensor(
[[191.6, -13.5, 728.6],
[92.14, 295.5, -184],
[0, 684.6, 245.5]]
)
### these are random values for "scale" and "zero_point"
### to test the implementation
scale = 3.5
zero_point = -70
quantized_tensor = linear_q_with_scale_and_zero_point(
test_tensor, scale, zero_point)
dequantized_tensor = scale * (quantized_tensor.float() - zero_point)
(dequantized_tensor - test_tensor).square().mean()

要计算s和z,首先我们知道r_min,r_max以及q_min,q_max,由此得到s,再通过s,q_min和r_min计算得到z.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def get_q_scale_and_zero_point(tensor, dtype=torch.int8):
q_min, q_max = torch.iinfo(dtype).min, torch.iinfo(dtype).max
r_min, r_max = tensor.min().item(), tensor.max().item()
scale = (r_max - r_min) / (q_max - q_min)
zero_point = q_min - (r_min / scale)
# clip the zero_point to fall in [quantized_min, quantized_max]
if zero_point < q_min:
zero_point = q_min
elif zero_point > q_max:
zero_point = q_max
else:
# round and cast to int
zero_point = int(round(zero_point))
return scale, zero_point

1
2
3
4
5
6
7
8
9
10
11
12
13def linear_quantization(tensor, dtype=torch.int8):
scale, zero_point = get_q_scale_and_zero_point(tensor,
dtype=dtype)
quantized_tensor = linear_q_with_scale_and_zero_point(tensor,
scale,
zero_point,
dtype=dtype)
return quantized_tensor, scale , zero_point
def linear_dequantization(q_tensor,scale,zero_point):
tensor = (q_tensor.float()-zero_point)*scale
return tensor
在线性量化中有对称和非对称模式,非对称就是上面的方式.对称模式将[-$r{max}$,$r{max}$]投影到[-$q{max}$,$q{max}$],$r{max}$是max(|$r{tensor}$|)
计算公式是
1 | def get_q_scale_symmetric(tensor, dtype=torch.int8): |
对比,对称模式会导致有些量化范围的值用不上,但是它比较简单而且不用存0值. 在量化到更低位时考虑使用非对称模式。
量化的不同粒度,包括per tensor,per channel,per group.
对于通道来说1
2
3
4for index in range(output_dim):
sub_tensor = test_tensor.select(dim,index)
# print(sub_tensor)
scale[index] = get_q_scale_symmetric(sub_tensor)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23def linear_q_symmetric_per_channel(r_tensor, dim, dtype=torch.int8):
output_dim = r_tensor.shape[dim]
# store the scales
scale = torch.zeros(output_dim)
for index in range(output_dim):
sub_tensor = r_tensor.select(dim, index)
scale[index] = get_q_scale_symmetric(sub_tensor, dtype=dtype)
# reshape the scale
scale_shape = [1] * r_tensor.dim()
scale_shape[dim] = -1
scale = scale.view(scale_shape)
quantized_tensor = linear_q_with_scale_and_zero_point(
r_tensor, scale=scale, zero_point=0, dtype=dtype)
return quantized_tensor, scale
dequantized_tensor_0 = linear_dequantization(
quantized_tensor_0, scale_0, 0)
plot_quantization_errors(
test_tensor, quantized_tensor_0, dequantized_tensor_0)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28def linear_q_symmetric_per_group(tensor, group_size,
dtype=torch.int8):
t_shape = tensor.shape
assert t_shape[1] % group_size == 0
assert tensor.dim() == 2
tensor = tensor.view(-1, group_size)
quantized_tensor, scale = linear_q_symmetric_per_channel(
tensor, dim=0, dtype=dtype)
quantized_tensor = quantized_tensor.view(t_shape)
return quantized_tensor, scale
def linear_dequantization_per_group(quantized_tensor, scale,
group_size):
q_shape = quantized_tensor.shape
quantized_tensor = quantized_tensor.view(-1, group_size)
dequantized_tensor = linear_dequantization(quantized_tensor,
scale, 0)
dequantized_tensor = dequantized_tensor.view(q_shape)
return dequantized_tensor
量化权重和激活.1
2
3
4
5
6
7
8def quantized_linear_W8A32_without_bias(input, q_w, s_w, z_w):
assert input.dtype == torch.float32
assert q_w.dtype == torch.int8
dequantized_weight = q_w.to(torch.float32) * s_w + z_w
output = torch.nn.functional.linear(input, dequantized_weight)
return output

1
output = quantized_linear_W8A32_without_bias(input, q_w, s_w, 0)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44class W8A16LinearLayer(nn.Module):
def __init__(self,in_features,out_features,bias=True,dtype=torch.float32):
super().__init__()
self.register_buffer(
"int8_weights",
torch.randint(
-128, 127, (out_features, in_features), dtype=torch.int8
)
)
self.register_buffer("scales",
torch.randn((out_features), dtype=dtype))
if bias:
self.register_buffer("bias",
torch.randn((1, out_features),
dtype=dtype))
else:
self.bias = None
def quantize(self, weights):
w_fp32 = weights.clone().to(torch.float32)
scales = w_fp32.abs().max(dim=-1).values / 127
scales = scales.to(weights.dtype)
int8_weights = torch.round(weights
/ scales.unsqueeze(1)).to(torch.int8)
self.int8_weights = int8_weights
self.scales = scales
def forward(self, input):
return w8_a16_forward(self.int8_weights,
input, self.scales, self.bias)
def w8_a16_forward(weight, input, scales, bias=None):
casted_weights = weight.to(input.dtype)
output = F.linear(input, casted_weights) * scales
if bias is not None:
output = output + bias
return output
量化线性层,可以替代一些模型的线性层,因为它自带quantize方法可以量化线性层的权重,这里的量化方法都是指的linear quantization,也就是通过原本值的范围和量化后的计算得到的scale和zero_point来将原本的矩阵进行量化.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def replace_linear_with_target(module,
target_class, module_name_to_exclude):
for name, child in module.named_children():
if isinstance(child, nn.Linear) and not \
any([x == name for x in module_name_to_exclude]):
old_bias = child.bias
new_module = target_class(child.in_features,
child.out_features,
old_bias is not None,
child.weight.dtype)
setattr(module, name, new_module)
if old_bias is not None:
getattr(module, name).bias = old_bias
else:
# Recursively call the function for nested modules
replace_linear_with_target(
child, target_class, module_name_to_exclude)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22def replace_linear_with_target_and_quantize(module,
target_class, module_name_to_exclude):
for name, child in module.named_children():
if isinstance(child, nn.Linear) and not \
any([x == name for x in module_name_to_exclude]):
old_bias = child.bias
old_weight = child.weight
new_module = target_class(child.in_features,
child.out_features,
old_bias is not None,
child.weight.dtype)
setattr(module, name, new_module)
getattr(module, name).quantize(old_weight)
if old_bias is not None:
getattr(module, name).bias = old_bias
else:
# Recursively call the function for nested modules
replace_linear_with_target_and_quantize(child,
target_class, module_name_to_exclude)
搭配huggingface量化大模型.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_id = "./models/Salesforce/codegen-350M-mono"
model = AutoModelForCausalLM.from_pretrained(model_id,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True)
tokenizer = AutoTokenizer.from_pretrained(model_id)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
replace_linear_with_target_and_quantize(model,
W8A16LinearLayer, ["lm_head"])
print(pipe("def hello_world():", max_new_tokens=20,
do_sample=False)[0]["generated_text"])
Weight packing
将可以使用int2,int4保存的多个数据使用一个或多个int8保存起来,也就是pack.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30def pack_weights(uint8tensor, bits):
if uint8tensor.shape[0] * bits % 8 != 0:
raise ValueError(f"The input shape needs to be a mutiple \
of {8 / bits} - got {uint8tensor.shape[0]}")
num_values = uint8tensor.shape[0] * bits // 8
num_steps = 8 // bits
unpacked_idx = 0
packed_tensor = torch.zeros((num_values), dtype=torch.uint8)
# 1 0 3 2 - 01 00 11 10
# [0000 0000] -> 0000 0001
# 0000 0001
# 0000 0000 - 0000 0000
# 0000 0011 - 0011 0000 - 0011 0001
# 1011 0001
for i in range(num_values):
for j in range(num_steps):
packed_tensor[i] |= uint8tensor[unpacked_idx] << (bits * j)
unpacked_idx += 1
return packed_tensor1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33def unpack_weights(uint8tensor, bits):
num_values = uint8tensor.shape[0] * 8 // bits
num_steps = 8 // bits
unpacked_tensor = torch.zeros((num_values), dtype=torch.uint8)
unpacked_idx = 0
# 1 0 3 2 - 01 00 11 10
# [00000000 00000000 00000000 00000000]
# [10110001 00101100 00001011 00000010]
# [00000001 00000000 00000011 00000010]
# 10110001
# 00000011
# 00000001
# 1: [10110001]
# 2: [00101100]
# 3: [00001011]
mask = 2 ** bits - 1
for i in range(uint8tensor.shape[0]):
for j in range(num_steps):
unpacked_tensor[unpacked_idx] |= uint8tensor[i] >> (bits * j)
unpacked_idx += 1
unpacked_tensor &= mask
return unpacked_tensor

数据处理
在收集大量文本数据后,必须对数据进行预处理,以构建预训练语料库,特别是去除噪声、冗余、不相关和潜在有毒的数据],这些数据可能会在很大程度上影响 LLM 的容量和性能。为了方便数据处理,最近的一项研究为 LLMs 提出了一个有用的数据处理系统,名为 Data-Juicermodelscope/data-juicer: A one-stop data processing system to make data higher-quality, juicier, and more digestible for LLMs! 🍎 🍋 🌽 ➡️ ➡️🍸 🍹 🍷为大语言模型提供更高质量、更丰富、更易”消化“的数据! (github.com),它提供了 50 多个处理算子和工具.在这一部分将回顾详细的数据预处理策略,以提高所收集数据的质量。
Quality Filtering
为了从收集到的语料库中剔除低质量数据,现有工作一般采用两种方法:(1) 基于分类器的方法;(2) 基于启发式的方法。前一种方法基于高质量文本训练选择分类器,并利用它来识别和过滤低质量数据。然而一些研究发现基于分类器的方法可能会导致方言、口语和社会方言语言中高质量文本的无意删除,这可能会导致预训练语料中的偏见,并减弱语料的多样性。
作为第二种方法,一些研究,如BLOOM 和Gopher,采用启发式方法,通过一组精心设计的规则来消除低质量文本,这些规则可以概括为:
·基于语言的过滤。如果LLM主要用于某些语言的任务,则可以过滤其他语言的文本。
·基于度量的过滤。生成文本的评价指标,例如困惑度,可以用来检测和去除不自然的句子。
·基于统计的过滤。语料库的统计特征,如标点符号分布,符词比和句子长度,可以用来衡量文本质量和过滤低质量数据。
·基于关键词的过滤。基于特定的关键字集合,噪声或无用的
De-duplication
现有工作发现语料库中的重复数据会降低语言模型的多样性,这可能会导致训练过程变得不稳定,从而影响模型性能。因此,有必要对重复数据删除语料进行预训练。特别地,重复数据删除可以在不同粒度下进行,包括句子级、文档级和数据集级重复数据删除。首先,应该去除包含重复单词和短语的低质量句子,因为它们可能会在语言建模中引入重复模式。在文档层面,现有研究大多依靠文档之间的表面特征重叠率(例如,单词和n元词串重叠)来检测和去除包含相似内容的重复文档。此外,为了避免数据污染问题,防止训练集和评估集之间的重叠也是至关重要的,通过从训练集中移除可能的重复文本。研究表明,这3个层次的去重对提高LLMs的训练是有益的,应该在实际中联合使用。
Privacy Reduction
大多数预训练文本数据是从Web来源获得的,包括用户生成的涉及敏感或个人信息的内容,这可能会增加隐私泄露的风险。因此,有必要从预训练语料中移除个人身份信息( PII )。一种直接而有效的方法是使用基于规则的方法,如关键字检测,来检测和去除PII,如名称,地址和电话号码。此外,研究人员还发现LLMs在隐私攻击下的脆弱性可以归因于预训练语料中存在重复的PII数据
Tokenization
normalization是为了去除不需要的空白,小写以及口音.
pre-tokenization会生成每个word的偏移量.Model就是BPE等方法.

标记化也是数据预处理的关键步骤。它的目的是将原始文本分割成一系列单独的令牌序列,然后将这些令牌序列作为LLMs的输入.在传统的NLP研究(例如,利用条件随机场进行序列标注)中,基于词的标记化是最主要的方法,它更符合人类的语言认知.主要有word-,character-以及subword-的分词方式.
训练tokenizer是一个统计过程,它试图确定哪些子词是特定语料的最佳选择,而选择子词的具体规则取决于标记化算法。它是确定性的,这意味着在同一语料库上使用同一算法进行训练时,总会得到相同的结果。
Byte-Pair encoding
它从一组基本符号(例如,字母和边界字符)开始,迭代地将语料库中频繁出现的连续两个token对组合为新的token (称为merge ).对于每一个合并,选择标准是基于两个连续标记的共现频率:选择最高的频繁对.合并过程一直持续到达到预定义的大小.
开始通过word分词得到类似下面的数据1
2Vocabulary: ["b", "g", "h", "n", "p", "s", "u", "ug"]
Corpus:("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
在获得基本词汇后,会通过学习合并规则来添加新的标记词,直到达到所需的词汇量为止,合并规则就是将现有词汇中的两个元素合并成一个新词汇.因此,一开始这些合并会产生两个字符的词库,然后随着训练的进行,会产生更长的子词.
在标记符训练过程中的任何一步,BPE 算法都会搜索现有标记符中出现频率最高的一对(这里的 “一对 “指的是一个词中连续出现的两个标记符)。这对频率最高的词对将被合并,然后我们重复下一步1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74from collections import defaultdict
word_freqs = defaultdict(int)
for text in corpus:
words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)
new_words = [word for word, offset in words_with_offsets]
for word in new_words:
word_freqs[word] += 1
alphabet = []
for word in word_freqs.keys():
for letter in word:
if letter not in alphabet:
alphabet.append(letter)
alphabet.sort()
print(alphabet)
vocab = ["<|endoftext|>"] + alphabet.copy() # 针对不同llm可能会有special tokens.
splits = {word: [c for c in word] for word in word_freqs.keys()}
def compute_pair_freqs(splits):
pair_freqs = defaultdict(int)
for word, freq in word_freqs.items():
split = splits[word]
if len(split) == 1:
continue
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
pair_freqs[pair] += freq
return pair_freqs
pair_freqs = compute_pair_freqs(splits)
for i, key in enumerate(pair_freqs.keys()):
print(f"{key}: {pair_freqs[key]}")
if i >= 5:
break
best_pair = ""
max_freq = None
for pair, freq in pair_freqs.items():
if max_freq is None or max_freq < freq:
best_pair = pair
max_freq = freq
def merge_pair(a, b, splits):
for word in word_freqs:
split = splits[word]
if len(split) == 1:
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
split = split[:i] + [a + b] + split[i + 2 :]
else:
i += 1
splits[word] = split
return splits
def tokenize(text):
pre_tokenize_result = tokenizer._tokenizer.pre_tokenizer.pre_tokenize_str(text)
pre_tokenized_text = [word for word, offset in pre_tokenize_result]
splits = [[l for l in word] for word in pre_tokenized_text]
for pair, merge in merges.items():
for idx, split in enumerate(splits):
i = 0
while i < len(split) - 1:
if split[i] == pair[0] and split[i + 1] == pair[1]:
split = split[:i] + [merge] + split[i + 2 :]
else:
i += 1
splits[idx] = split
return sum(splits, [])
SentencePiece
SentencePiece 是一种用于文本预处理的tokenization,它将文本视为 Unicode 字符序列,并用特殊字符 ▁ 替换空格.与 Unigram 算法结合使用,它甚至不需要预标记步骤,这对于不使用空格字符的语言(如中文或日文)非常有用
WordPiece
与 BPE 类似,WordPiece 也是从一个小词库开始的,其中包括模型使用的特殊标记和初始字母表.由于它是通过添加前缀(如 BERT 的 ##)来识别子词的,因此每个词最初都是通过将前缀添加到词内的所有字符来分割的.
同样的例子.1
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
拆开后有1
("h" "##u" "##g", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("h" "##u" "##g" "##s", 5)
WordPiece 学习合并规则.主要区别在于选择要合并的词对的方式.它不是选择最频繁的词对.
通过将词对的频率除以各部分频率的乘积,该算法会优先合并词汇中各部分频率较低的词对.
初始词汇将是[“b”、”h”、”p”、”##g”、”##n”、”##s”、”##u”](如果我们暂时不考虑特殊标记的话)。出现频率最高的词对是(”##u”,”##g”)(出现 20 次),但 “##u “的单个出现频率非常高,因此它的得分并不是最高的(1/36)。所有含有 “##u “的词对实际上都有相同的得分(1/36),因此得分最高的词对是(”##g”, “##s”)—唯一一个没有 “##u “的词对,得分是 1/20,第一次合并的结果是(”##g”, “##s”)->(”##gs”)1
2Vocabulary: ["b", "h", "p", "##g", "##n", "##s", "##u", "##gs"]
Corpus: ("h" "##u" "##g", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("h" "##u" "##gs", 5)
Unigram
Unigram 算法常用于 SentencePiece,而 SentencePiece 是 AlBERT、T5、mBART、Big Bird 和 XLNet 等模型使用的tokenization算法。
与 BPE 和 WordPiece 相比,Unigram 的工作方向相反:它从一个大词汇量开始,然后从中删除词组,直到达到所需的词汇量.有几种方法可以用来建立基本词库:例如,我们可以在预先标注的单词中提取最常见的子串,或者在初始语料库中应用 BPE,以获得较大的词汇量.
有几种方法可以用来建立基础词汇:例如,我们可以从预先标注的单词中选取最常见的子串,或者在初始语料库中应用 BPE,使其具有较大的词汇量。
在训练的每一步,Unigram 算法都会根据当前的词汇量计算语料库的损失.然后,对于词汇表中的每个符号,算法都会计算如果删除该符号,整体损失会增加多少,并寻找损失增加最少的符号.这些符号对语料库总体损失的影响较小,因此从某种意义上说,它们 “不那么需要”,是删除的最佳候选。
Retrieve Augmented Generation(RAG)
由 LLM 驱动的聊天机器人可处理用户提示并生成回复.该聊天机器人旨在与用户进行互动,并就广泛的主题与用户进行交流.
但是,它的回复仅限于所提供的上下文和基础培训数据.例如,GPT-4 的知识截止日期是 2021 年 9 月,这意味着它不了解这一时期之后发生的事件.此外,用于训练 LLM 的数据不包括个人笔记或公司产品手册等机密信息.
参考资料
- luban-agi/Awesome-AIGC-Tutorials: Curated tutorials and resources for Large Language Models, AI Painting, and more. (github.com)
- mlabonne/llm-course: Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks. (github.com)
- BradyFU/Awesome-Multimodal-Large-Language-Models: :sparkles::sparkles:Latest Papers and Datasets on Multimodal Large Language Models, and Their Evaluation. (github.com)
