随着大模型时代的到来,原先通过修改模型结构提升性能写论文的方式已经有点out of date了,同时写文章的倾向已经从改架构成SOTA慢慢转变为回归任务背景以及讲好一个完整故事并给出自己的findings和insight了.也因此,在协作感知方面,论文方向也逐渐在转变,这里看看最近的文章整理一下思路.
Domain gap
Bridging the Domain Gap for Multi-Agent Perception ICRA
摘要
现有的多智能体感知算法通常选择在智能体之间共享从原始感知数据中提取的深度神经特征,以实现精度和通信带宽限制之间的权衡.然而,这些方法假设所有智能体具有相同的神经网络,这在现实世界中可能是不实用的。
当模型不同时,传递的特征可能存在较大的领域差距(domain gap),导致多智能体感知性能急剧下降.
在本文中,我们提出了第一个轻量级框架来为多智能体感知弥合这种领域鸿沟,它可以作为大多数现有系统的插件模块,同时保持机密性.
我们的框架包括一个可学习的特征成形模来对齐多个维度的特征,以及一个用于领域自适应的稀疏跨域转换器.在公开的多智能体感知数据集V2XSet上的大量实验表明,对于基于点云的三维目标检测,我们的方法可以有效地弥合不同领域特征之间的差距,并显著优于其他基线方法至少8%。
引言
最近的研究表明,通过利用车联网( Vehicle-to- Everything,V2X )通信技术共享视觉信息,多智能体感知系统可以通过透视遮挡和感知更远的范围来显著提高单智能体系统的性能.
现有方法通常不共享原始感知数据或检测输出,而是共享由传感器数据计算得到的中间神经特征,因为它们可以在精度和带宽需求之间实现最佳权衡.
此外,传递的中间特征对GPS噪声和通信延迟的鲁棒性更强.
这忽略了一个关键的事实:为所有智能体部署相同的模型是不现实的,特别是对于连接的自动驾驶.
不同公司的网联自动驾驶汽车( CAV )和基础设施产品的检测模型通常是不同的。即使对于同一公司,由于车载软件版本的不同,也可能存在不同的检测模型.当共享特征来自不同的骨干时,存在一个明显的域间隙,这很容易削弱协作的好处。
在本文中,我们深入研究了多智能体感知中,特别是自动驾驶中这一尚未解决的实际问题.我们首先仔细研究了不同特征图的领域差距,然后在分析的基础上提出了我们的框架.
Related works
由于数据标注的时间消耗和不同域之间的域差距,域适应被用来解决这些问题,通过适应在有标签的源域上训练的模型来解决无标签的目标域.
最近的领域自适应工作主要针对不同的计算机视觉任务
在领域自适应中,为了最小化不同领域之间的领域偏移,特征分布可以在共同的层次上对齐:领域层次和类别层次。
领域级对齐通常涉及最小化源和目标特征分布之间的某种距离度量,如最大均值差异.
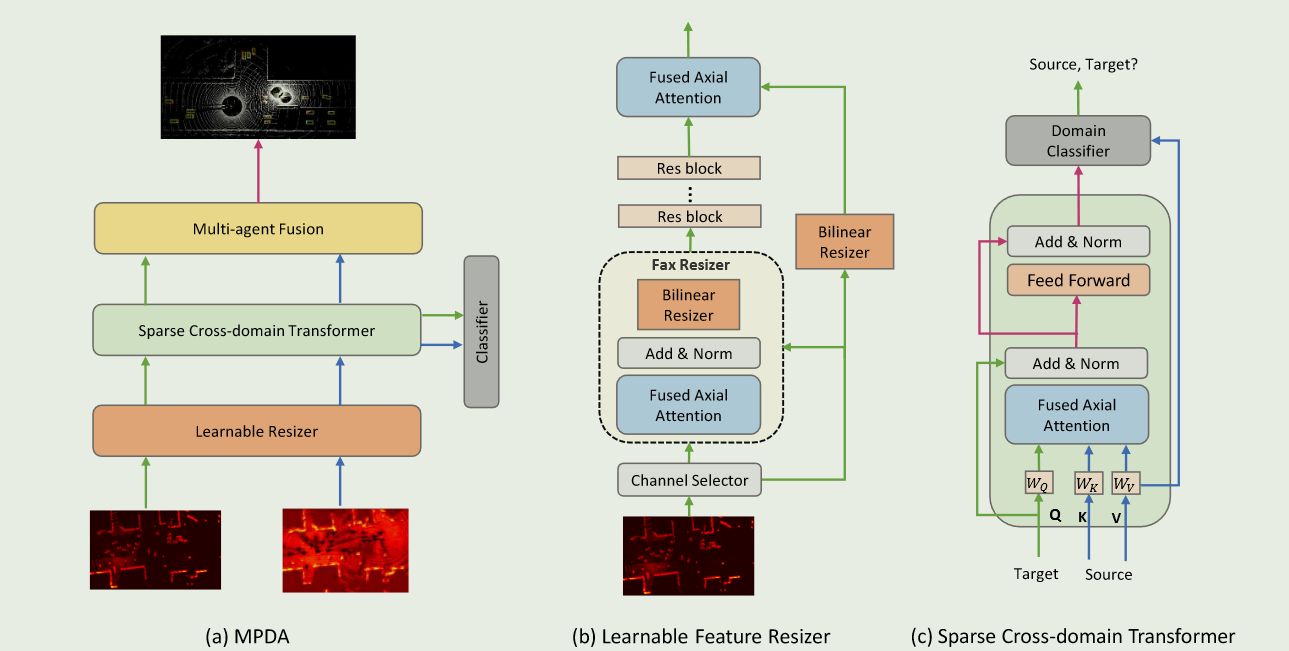
Learnable Feature Resizer
在ego代理上计算特征图作为source domain,接受其他代理的特征作为target domain.
特征缩放器Φ的目标是以可学习的方式将源域特征的维度与目标域进行对齐
我们将Φ与多智能体检测模型联合训练,使其能够智能地学习调整特征尺寸的最优方法,这与双线性插值等简单的尺寸调整方法有根本的不同。
可学习特征成形模的体系结构设计所示,它包括四个主要组件:通道对齐器,FAX成形模,跳跃连接和res - block。
Channel Aligner:使用一个简单的1 × 1卷积层对齐通道维度,其输入通道数为$C_{in}$ = 2$C_S$,输出CS通道。当$C^T > C^{in}$时,随机丢弃$C^{in} - C^{T}$通道,应用1 × 1卷积层得到新的特征.我们在$F^T$上重复这个过程n次,得到$n×H^T×W^T×C^S$维度的特征,并沿第一个维度进行平均。
通过这种方式,我们改善了由于信道衰落造成的信息丢失.当$CT$ < $C{in}$时,我们从FT中随机选择通道进行填充,以满足1 × 1卷积所需的输入通道数。
FAX Resizer
由于LiDAR特征通常由于空体素而具有稀疏性,应用大核卷积获取全局信息可能会将无意义的信息扩散到重要区域.因此,我们在双线性缩放之前应用了融合的轴向( FAX )注意力块,以获得更好的特征表示.
跳跃连接:在跳跃连接中,使用了双线性特征调整方法,以使学习更容易。
残差块( Res-Block ):在重新调整特征图大小后执行标准残差块r次,以进一步细化特征图.
Sparse Cross-Domain Transformer
在检索到缩放后的特征$F^′_{T}$后,需要将其模式从domain classifier中转换为不可区分的模式,以获得领域不变特征.为了达到这个目的,我们需要有效地从局部和全局两个方面来推理$F^{′}_T$和$F_S$之间的相关性.因此,我们提出了稀疏跨域transformer,在避免昂贵计算的同时,享受了transformer架构带来的动态和全局关注的好处.
其中LN是层标准化,Q是查询,K是键,V是值.然后,我们将$F^{′′}_T$和$F_S$配对在一起,并将它们送入域分类器和多智能体融合模块.
Domain Classifier
设X为可能来自源域或目标域的特征图,h:X→{ 0,1 }为域分类器,试图预测源域样本$X_S$为0,目标域样本$X_T$为1
Multi-Agent Fusion
选择了一个最先进的模型V2X - ViT作为我们的多智能体融合算法。V2X - ViT依次采用异构多智能体自注意力块和多尺度窗口注意力块,对不同智能体的特征进行智能融合。
MACP: Efficient Model Adaptation for Cooperative Perception WACV
abstract
车对车(V2V)通信通过信息共享实现了 “看穿遮挡物”,极大地增强了联网和自动驾驶车辆(CAV)的感知能力,从而显著提高了性能。然而,当现有的单个代理模型显示出卓越的泛化能力时,从头开始开发和训练复杂的多代理感知模型可能既昂贵又没有必要。在本文中,我们提出了一个名为 MACP 的新框架,它能使预先训练好的单个代理模型具备合作能力。为了实现这一目标,我们确定了从单一代理转向合作设置所面临的关键挑战,并通过冻结大部分参数和添加一些轻量级模块来调整模型。我们在实验中证明,所提出的框架可以有效地利用合作观察,并在模拟和真实世界合作感知基准中优于其他最先进的方法,同时所需的可调参数大大减少,通信成本也降低了。
方法
我们的目标是求解一个最佳模型 $f^{∗}$,该模型能够检测和划定周围物体的边界框,并分配适当的标签.
为了简化符号,我们用一个 d′维向量 $y_j∈R^{d′}$ 来表示每个边界框及其类别标签。
在不失一般性的前提下,物体检测模型 f 是一个从点云空间到边界框及其标签的联合空间 f : X → Y 的映射,经过训练的模型理想地描述了以观测点云集 x 为条件观测边界框集 y 的概率,其值为
如果我们用 pS (x) 表示在单个代理感知中观察到点云集的边际概率,用 pC(x) 表示在合作感知中观察到精确点云集的概率,由于 V2V 通信共享了额外的点云,这两个概率可能不同,即 pS (x) ̸= pC(x) 。
预训练模型给出的点云和边界框的联合分布偏离合作环境下的地面实况联合分布
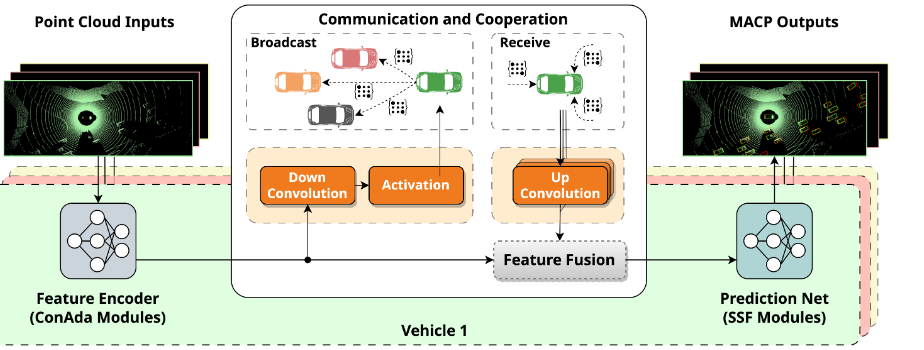
Convolution Adapter
ConAda 模块是特征编码器的关键组件。特征编码器网络是卷积块的级联,其中卷积层的输出经过 ConAda 模块,并通过残差连接加回自身。我们只在训练过程中训练 ConAda 参数,并在卷积层和 ConAda 模块之后的其他层中冻结预训练参数。
同时,ConAda 还充当车辆之间的通信通道。在通信过程中,ConAda 模块中的下卷积层和激活层帮助压缩和加密编码特征,以便进行广播,而上卷积层则用于解压缩接收信号,以便进行特征融合。
SSF Operator for Fused Feature
我们在连续的神经网络层中执行 SSF 算子,以考虑域偏移.
假设卷积层的输出特征图由 $X^{output}_{i,j}$ ∈ $R^{H′×W ′×C′}$ 给出,我们使用缩放因子 $\gamma$∈ $R^{C′}$和移动因子 β ∈ $R^{C′}$更新特征图
最后,基于 ConAda 的通信信道可以灵活压缩信号传输,从而缓解通信瓶颈.
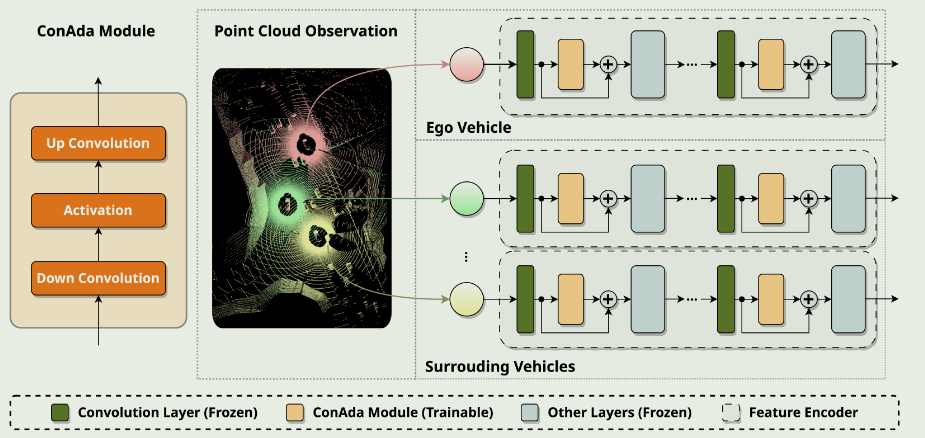
这篇文章主要基于微调的方法和思想,使用的是Adapter,此外还有LoRA等.关于大模型压缩技术还有剪枝、蒸馏以及量化等等,感觉都可以试试.
DI-V2X: Learning Domain-Invariant Representation for Vehicle-Infrastructure Collaborative 3D Object Detection AAAI
Task Collaborative 3D Object Detection
method learn domain-invariant representation
inner thoughts distillation
摘要
车对物(V2X)协同感知最近获得了极大关注,因为它能够通过整合来自不同代理(如车辆和基础设施)的信息来增强场景理解能力。然而,目前的研究通常对来自每个代理的信息一视同仁,忽略了每个代理使用不同激光雷达传感器所造成的固有领域差距,从而导致性能不尽如人意。
也就是不同的LiDAR传感器本身的不同会导致一种domain gap,会使性能下降.这种说法看起来make sense,但加上一些示意图补充可能更好.这篇文章就加了一张.
提出了 DI-V2X,旨在通过一个新的蒸馏框架来学习领域不变表征,以减轻 V2X 3D 物体检测中的领域差异。
DI-V2X 包括三个基本组件:域混合实例增强(DMA)模块、渐进式域不变性蒸馏(PDD)模块和域自适应融合(DAF)模块.
具体来说,DMA 在训练过程中为教师模型和学生模型建立了一个领域混合三维实例库,从而形成对齐的数据表示.接下来,PDD 鼓励来自不同领域的学生模型逐步学习与教师领域无关的特征表示,并利用代理之间的重叠区域作为指导,促进提炼过程.
此外,DAF 通过校准感知领域自适应注意力,缩小了学生之间的领域差距.在具有挑战性的 DAIR-V2X 和 V2XSet 基准数据集上进行的大量实验表明,DI-V2X 性能卓越,超过了之前所有的 V2X 模型.
Introduction
它充分利用从不同代理(即车辆和路边基础设施)收集到的传感器数据,精确感知复杂的驾驶场景.例如,在车辆视线可能受阻的情况下,由于基础设施的视角不同,它们提供的信息可以作为重要的冗余.
与以往的单车自动驾驶系统相比,这种合作从根本上扩大了感知范围,减少了盲点,提高了整体感知能力.
为了有效融合来自不同代理的信息,领先的 V2X 方法倾向于采用基于特征的中间协作,即中间融合)。这种方法在特征层保留了每个代理的基本信息,然后对其进行压缩以提高效率。因此,中间融合确保了性能与带宽的权衡,优于早期融合或后期融合方法,前者需要在代理之间传输原始点云数据,而后者则容易受到每个模型产生的不完整结果的影响。
然而,当前的中间融合模型主要集中在增强来自不同代理的特征之间的交互。
如图 1(a)所示,车辆和基础设施可能拥有不同类型的激光雷达传感器,因此直接融合不同来源的点云数据或中间特征难免会影响最终性能。因此,在这种情况下,如何从多源数据中明确学习域不变表示仍有待探索。

为此,DI-V2X 引入了一种新的师生提炼模型.在训练过程中,我们强制要求学生模型(即车辆和基础设施)学习与早期融合的教师模型一致的领域不变表示法,即把来自多个视角的点云整合为一个整体视图来训练教师。在推理过程中,只保留学生模型。具体来说,DI-V2X 由三个必要组件组成:领域混合实例增强(DMA)模块、渐进式领域不变性提炼(PDD)模块和领域自适应融合(DAF)模块
其实基础思想就是蒸馏,搞一个结构相似但参数量更小的模型替代原本较大的模型. 关键是让小模型学会大模型的”知识”
DMA 的目的是在训练过程中建立一个mixed ground-truth instance bank,以对齐教师和学生的点云输入,其中的实例来自车侧、路侧或融合侧。
之后,PDD 的目标是在不同阶段,即在领域适应性融合之前和之后,逐步将信息从教师传递给学生.例如,在融合之前,引导学生在非重叠区域分别学习领域不变的表征。而在融合之后,我们将重点放在重叠区域内的提炼上,因为信息已经得到了很好的汇总.
在 DAF 模块中,来自不同领域的特征会根据其空间重要性进行自适应融合。此外,DAF 还通过整合校准偏移来增强模型对姿态误差的适应能力,从而确保 V2X 检测性能的稳健性。
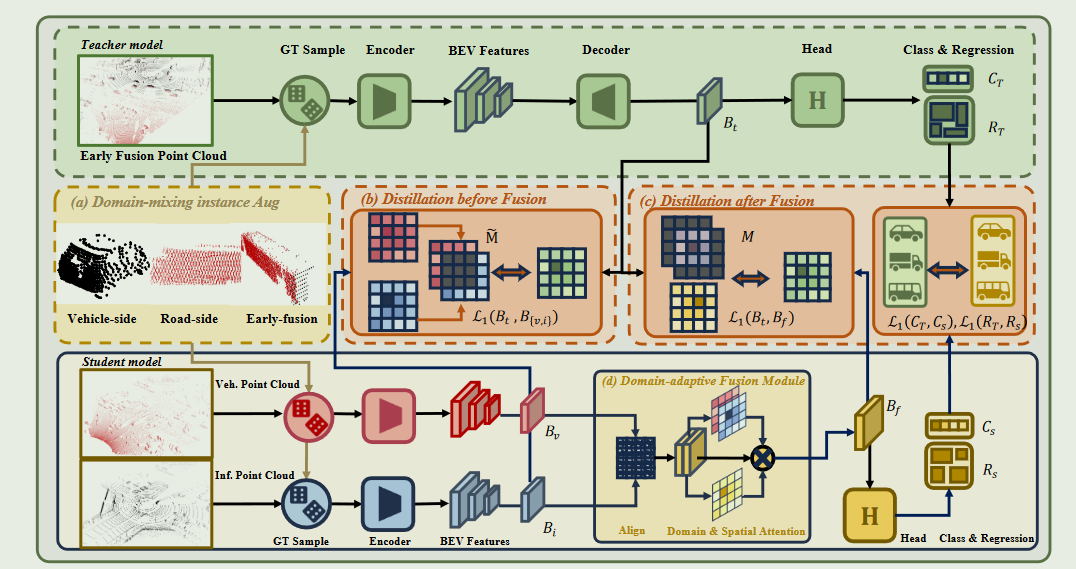
在DMA中,对于教师模型,使用车端数据,路端数据以及早期融合后的数据(就是转换到统一坐标系后的点云结果)利用PointPillars的decoder进行增强,使用增强后的$P_e$,再使用VoxelNet处理成BEV的二维特征图$B_t$.
学生模型结构跟教师模型类似,处理$P_v$和$P_i$提取得到对应特征图.然后使用DAF进行融合得到$B_f$
在训练的时候,在DAF融合之前和之后会有一个PDD模型将学生模型得到的特征和老师模型得到的特征利用overlapping area进行对齐.
DMA本是类似一个数据增强模块,首先将 $Pi$ 投影到自我车辆的坐标系上,这样 $P^T_i$ =$T(i→v)$$P^T_i$,其中 $T(i→v)$ ∈ $R^{4×4} $是基础设施到车辆系统的变换矩阵.然后,我们利用地面实况边界框 $B{gt}$ = {$bk$} 从 $P_v$ 和 $P_i$ 获取实例.来自不同domain、对应于同一地面实况对象的实例将被合并,得到一个早期融合实例 pk = Concat($p^v_k$, $p^i_k$) ∈ $R^{N{k}×4}$,其中 $p^v_k$∈ Pv 和 $p^i_k$∈ Pi 是来自两个领域、以 $b_k$为索引的实例点。由于代理之间的相对位置会随着自我车辆的运动而发生动态变化,因此有些实例可能仅来自单个域,而另一些实例则可能直接来自早期融合的重叠区域。为了确定每个实例的域来源,我们通过计算来自每个域的点比例,将这些实例分为三类:
$N^{v}{k}$ 和 $N^{i}{k}$ 分别代表车辆侧和基础设施侧的点数,τl、τh 表示阈值.然后,得到一个实例库$D{mixed}$ = $D_i$ ∪ $D_f$ ∪ $D_v$,其中包含来自所有领域(即包括融合领域)的混合实例。在训练过程中,我们按照一定的概率从$D{mixed}$中随机抽取实例,并将这些实例添加给教师和学生.
通过涉及不同领域的实例增强了训练数据的多样性.此外,从每个学生的角度来看,来自其他领域的信息也会通过实例级混合被纳入其中(Zhang 等人,2018 年).这种方法从根本上调整了教师模型和学生模型之间的数据分布,从而在随后的知识提炼过程中产生了更具普适性的特征。
为了获得跟域无关的特征,采用了两阶段蒸馏策略,即在领域自适应融合(DAF)模块之前和之后进行蒸馏。第一个蒸馏阶段是将学生的分布与教师模型相一致,作为 DAF 的输入,这对准确的信息融合至关重要。
然而,根据经验发现,直接对学生和教师之间的整个特征图进行蒸馏会产生次优性能.为此选择在第一阶段对非重叠区域进行蒸馏.在第二阶段,由于学生特征已通过 DAF 得到很好的融合,我们可以集中精力对重叠区域进行蒸馏.这种两阶段的提炼过程可使学生模型与来自不同区域的教师模型的特征表示相匹配,从而缩小学生之间的差距.
在融合之前的蒸馏,首先需要计算重叠掩码,以确定重叠区域.
将基础设施一侧的感知区域转换到车辆一侧,得到一个新的矩形 $Ai$ = ($x_i,y_i,2R_x, 2R_y, θ_i$)。然后我们可以计算 $A_v$ 和 $A_i$ 之间的重叠区域,即 $P{overlap}$ = Intersection($Av$,$A_i$)。然后对得到的 $P{overlap}$(即多边形)进行下采样,以匹配特征地图 $B_v$ ∈ $R^{H×W ×C}$ 的大小.
M(i, j) ∈ 0, 1 表示(i, j)坐标处的二进制值。通过只对非重叠区域 进行提炼,我们允许每个学生集中学习与各自领域一致的表征。这就避免了强制要求不完整的学生特征向教师的完整特征学习的严格约束
在融合后的蒸馏,使用 DAF 模块有效地合并了来自不同领域的学生特征.因此,我们得到了一个能力很强的融合表征,用 Bf 表示,它可以与教师的特征表征 $B_t$ 配对.
直观地说,Bt 是通过混合点云数据的早期协作获得的,其本质上涉及最小的信息损失.通过强制中间融合特征 $B_f$ 逐步与$B_t$ 保持一致,可以有效地确保在整个学习过程中始终整合通过早期融合阶段获得的基本知识,从而形成与领域无关的特征表征.
此外,我们还可以超越特征级对齐,扩展到预测级对齐.由于我们的最终目标是从两个 $B_f$ 解码出最终的三维边界框,确保预测层面的对齐将进一步提高结果的一致性和准确性.
DAF 模块的目标是聚合车辆和基础设施的特征,创建一个包含各领域有价值信息的增强表示.然而,这一融合过程面临着两大挑战:双方姿势的潜在错位和设计合适的特征交互策略.

由于传感器噪声、动态运动和不同时间戳的不一致性等原因,现实世界中车辆和基础设施的相对姿态很容易受到影响,这将影响 V2X 感知的准确性.为了解决这个问题,利用校准偏移来动态纠正潜在的姿势误差.
首先用卷积层预测校准偏移,使$B_i$与$B_v$更好地对齐,记为
空间自适应注意力可以通过聚合多粒度特征,提供稳健而灵活的注意力图
最后结果展示包括在两个数据集上与No fusion,early和late fusion以及一些列经典中期融合模型对比.
然后证明domain generalization实验证明模型学到了域不变的特征.此外还有消融实验,证明提出的每个组件的作用.
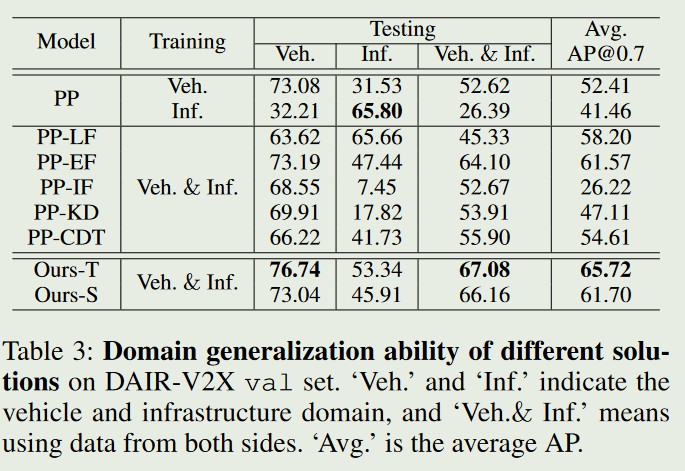
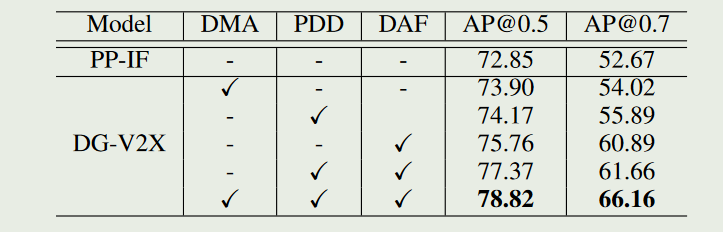
Model-Agnostic Multi-Agent Perception Framework ICRA
Abs
现有的多智能体感知系统假设每个智能体使用相同的模型,具有相同的参数和结构,这在现实世界中往往是不切实际的.当感知模型存在明显差异时,多智能体系统带来的显著性能提升会显著降低.
在这项工作中,我们提出了一个model-agnostic的多Agent框架,以减少模型差异带来的负面影响,并保持机密性(隐私?).具体来说,我们通过集成一个新颖的不确定性校准器来考虑智能体之间的感知异质性,该校准器可以消除智能体预测置信度评分之间的偏差.每个代理在一个标准的公共数据库上独立地执行这种校准,因此知识产权可以得到保护。
为了进一步细化检测精度,我们还提出了一种新的算法,称为”促进-抑制聚合” ( Promotion-Suppression Aggregation,PSA ),该算法不仅考虑了proposals的置信度评分,还考虑了其邻居的空间一致性.
我们的实验强调了跨不同代理进行模型校准的必要性,结果表明我们提出的方法在开放的OPV2V数据集上的3D目标检测性能优于最先进的基线方法.
Intro
深度学习的最新进展提高了现代感知系统在许多任务上的性能,如目标检测、语义分割和视觉导航。尽管取得了令人瞩目的进展,但由于单视角的限制,单智能体感知系统仍然存在许多局限性。例如,自动驾驶车辆( Autonomous Vehicles,AVs )通常会遭受遮挡,由于缺乏对遮挡区域的感官观察,这种情况很难处理。为了解决这一问题,最近的研究探索了无线通信技术,使附近的智能体能够共享感知信息并协同感知周围环境。
尽管现有方法获得了显著的3D目标检测性能提升,但它们假设所有协作智能体共享相同的模型,且具有相同的参数,这在实际中往往不成立,特别是在自动驾驶中。在AV之间分配模型参数可能会引起隐私和保密问题,特别是对于来自不同汽车公司的车辆。对同步良好的检测器的依赖是不可靠的,因为AV可能具有不同的更新频率
如果不妥善处理不一致性挑战,共享的感知信息可能存在较大的领域鸿沟,多智能体感知带来的优势将迅速减弱。
由于不同主体使用的模型不同,不同主体提供的置信度得分可能存在系统性偏差,即不同主体具有不同的置信度估计偏差。
一些代理置信度更高另一些较低,忽略这种偏见并通过非极大值抑制( NMS )直接融合来自相邻代理的边界框建议,可能会由于存在过度自信但低质量的建议而导致较差的检测精度。
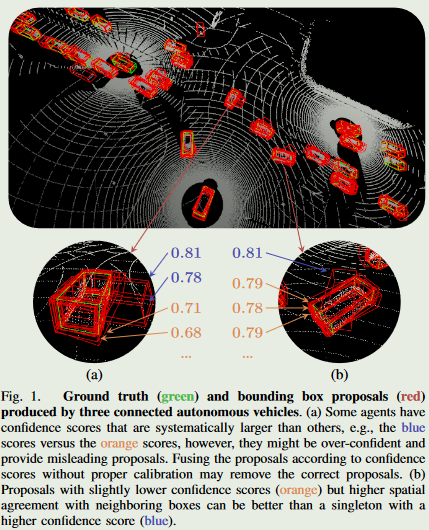
一些代理的信心分数系统性地大于其他代理人,例如,蓝色分数相对于橙色分数,然而,他们可能过度自信并提供误导性建议.根据置信度得分对建议进行融合,而不进行适当的校准可能会删除正确的建议.置信度得分稍低(橙色)但与邻近框具有较高空间一致性的提议可以优于置信度得分较高的单个提议.
在我们的框架中,我们集成了一个灵活而简单的不确定性校准器,称为双边界校准( Doubly Bounded Scaling,DBS ),以减轻失调。
此外,在bbox aggregation阶段,我们还提出了一个新的模块- -促进-抑制聚合( Promotion-Suppression Aggregation,PSA ),以替代经典的NMS,并利用box proposals在Agent之间的空间相关性和一致性,进一步细化最终结果.
我们在一个开源的大规模多智能体感知数据集OPV2V [ 12 ]上评估了我们的方法。实验表明,当涉及到智能体之间的模型差异时,我们的框架显著提高了基于多智能体LiDAR的三维目标检测性能,在平均精度( Average Precision,AP )方面比现有方法至少提高了6 %。
Methodology
在本文中,我们考虑了异构多智能体系统中的协作感知,其中智能体通信以共享来自不同感知模型的感知信息,而不泄露模型信息,即模型不可知协作。
我们专注于自动驾驶中的3D LiDAR检测任务,但该方法也可以定制并用于其他协同感知应用中。我们的目标是开发一个健壮的框架来处理代理之间的异质性,同时保持机密性。
因此,我们提出了一个模型不可知的集体感知框架,可以分为两个阶段。在离线阶段,我们训练了一个模型特定的校准器。在在线阶段,对实时的道路传感信息进行校准和汇总。
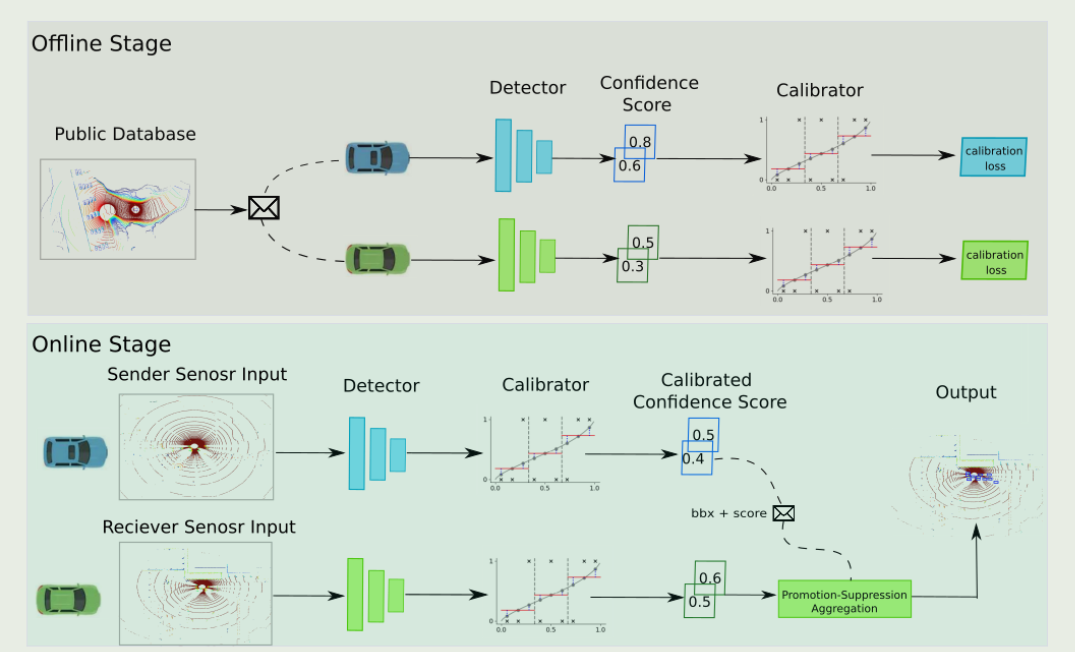
Conclusion
在合作感知情境下,来自不同的代理人具有异质性模式。由于机密性的考虑,与模型和参数相关的信息不应该被透露给其他代理。
由于机密性的考虑,与模型和参数相关的信息不应该被透露给其他代理。在这项工作中,我们提出了一个模型无关的协作框架,解决了纯晚期融合策略的两个关键挑战.首先,我们提出了一个Doubly Bounded Scaling不确定性校准器来对齐不同智能体的置信度得分分布。其次,新的提升抑制聚合算法通过充分利用共享信息(bounding box spatial congruence and confidence score propagation.),进一步提高了检测精度。
在大规模协作感知数据集上的实验表明了跨异构代理进行模型校准的必要性。结果表明,当不同的智能体使用不同的感知模型时,结合所提出的两种技术可以提高协作3D目标检测的
HEAL
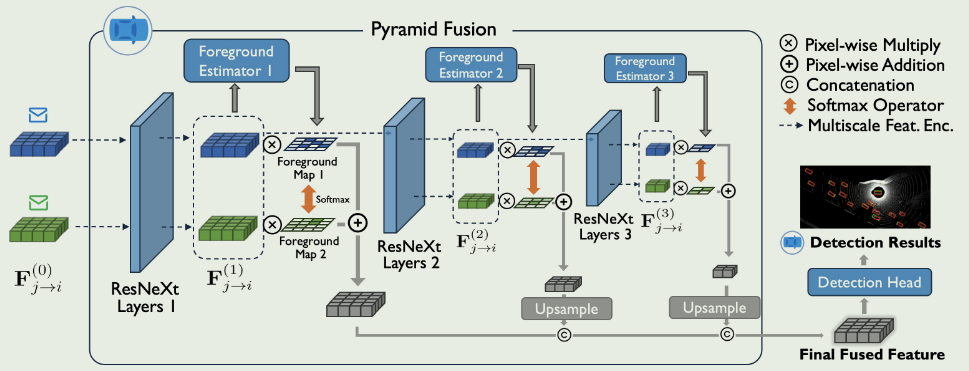
协作感知旨在通过促进多个智能体之间的数据交换来减轻单智能体感知的局限性,例如遮挡。
然而,目前的大多数工作都考虑了一种同质场景,即所有代理都使用传感器和感知模型。
在现实中,异构智能体类型可能会不断出现,并且在与现有智能体协作时不可避免地面临领域差距。在本文中引入了一个新的开放异构问题:如何在保证高感知性能和低集成成本的同时,将不断涌现的新异构代理类型适应到协作感知中?
为了解决这个问题提出了一种新型的可扩展协作感知框架HEterogeneous ALliance(HEAL)。HEAL首先通过一种的多尺度前景感知金字塔融合网络,与初始代理建立了一个统一的特征空间。当异构的新智能体以以前看不见的模式或模型出现时,我们通过创新的后向对齐方式将它们与已建立的统一空间对齐。此步骤仅涉及对新代理类型的个人培训,因此具有极低的培训成本和高可扩展性。
为了丰富智能体的数据异构性引入了OPV2V-H,这是一个新的大规模数据集,具有更多样化的传感器类型。在OPV2V-H和DAIR-V2X数据集上的大量实验表明,在集成3种新的智能体类型时,HEAL在性能上超过了SOTA方法,同时减少了91.5%的训练参数。
Sim2Real
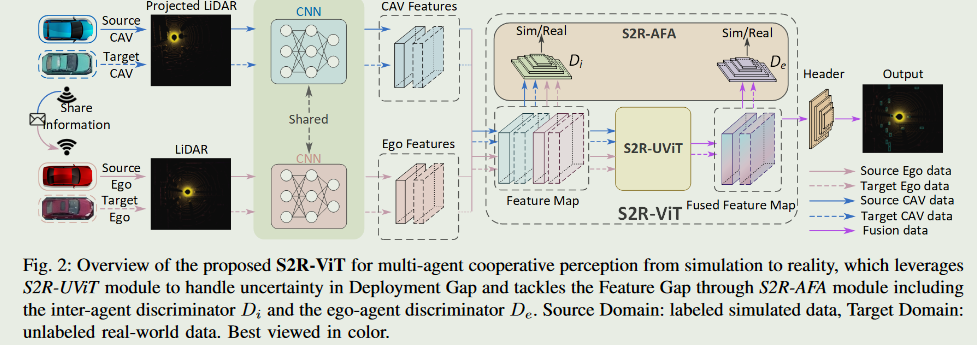
S2R-ViT for Multi-Agent Cooperative Perception: Bridging the Gap from Simulation to Reality ICRA
摘要
由于缺乏足够的真实多智能体数据且标注耗时,现有的多智能体协同感知算法通常选取模拟的传感器数据进行训练和验证。然而,当这些经过仿真训练的模型被部署到真实世界时,由于仿真数据和真实数据之间存在显著的领域差距,感知性能会下降。
在本文中,我们提出了第一个使用新型视觉转换器的多智能体协作感知的仿真到现实迁移学习框架,命名为S2R - ViT,它同时考虑了模拟数据和真实数据之间的部署差距和特征差距。
我们研究了这两种类型的域间隙的影响,并提出了一种新的不确定感知视觉转换器来有效地缓解部署间隙,并提出了一种基于代理的特征自适应模块,通过代理间和代理间的鉴别器来减小特征间隙。
在公开的多智能体协同感知数据集OPV2V和V2V4Real上的大量实验表明,本文提出的S2R - ViT方法能够有效地弥补仿真与现实之间的差距,在基于点云的三维目标检测中显著优于其他方法。
引言
多智能体协作感知的最新进展显示出克服单智能体感知受感知范围和遮挡挑战的局限性的潜力.多智能体协作感知系统通过利用智能体之间的通信技术共享信息,相比于单智能体感知,能够显著提升感知性能
由于在真实世界中收集具有通信的多智能体数据的困难,在多样化和复杂的真实世界环境中收集足够多的真实数据是昂贵且不容易的。此外,多智能体协同感知系统的地面真值数据标注和统一坐标投影尤为耗时。因此,现有的许多多智能体协同感知研究工作通常选取模拟数据进行模型训练和验证
然而,当我们将用模拟数据训练的模型应用于真实世界时,感知性能通常会下降。这种现象是由于模拟数据和真实数据之间存在显著的域差距。
在本文中,我们的研究重点是利用有标记的模拟数据和无标记的真实世界数据作为迁移学习,以减少多智能体协作感知的领域差距。
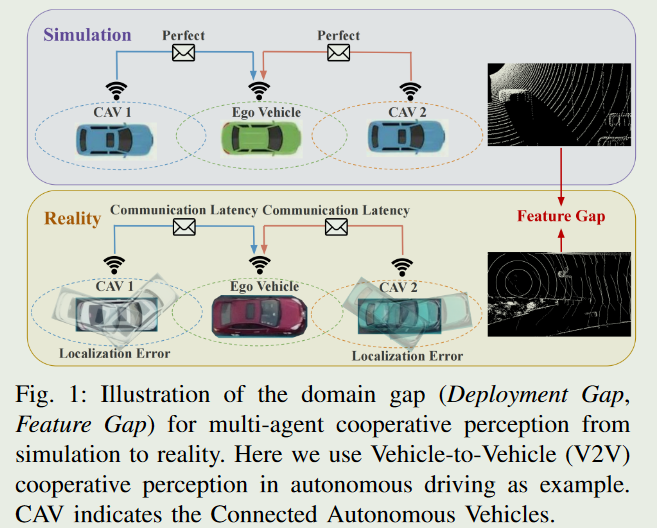
我们观察到,多智能体协作感知从模拟到现实的领域差距包括以下两个角度
部署差距( Deployment Gap ):与理想的仿真环境不同,在现实世界的智能体通信过程中,由于不可避免的GPS误差和通信延迟(时间延迟),多个智能体可能存在定位(位置和航向)错误
特征差距( Feature Gap ):现实世界的点云特征分布可能与仿真数据有显著差异,例如更复杂的驾驶场景、不同的激光雷达通道数、混合交通流、各种点云变化等。
在本文中,我们提出了第一个使用新型视觉转换器( ViT )的多智能体协作感知的仿真到现实( S2R )迁移学习框架,命名为S2R - ViT,同时考虑了部署间隙和特征间隙。我们选择车辆到车辆( Vehicle-to-Vehicle,V2V )协同感知任务作为基于点云的三维目标检测的算法开发。具体来说,我们的框架将来自模拟的有标记点云数据和来自真实世界的无标记数据作为输入,从而大量地利用模拟数据。在机器学习研究中,这种设置被广泛称为从源域(模拟)到目标域(现实)的无监督域适应。
S2R - ViT包括两个关键部分:( 1 ) S2R-UViT:一种新型的S2R不确定感知视觉转换器,可以有效地缓解develomment gap带来的不确定性。具体来说,S2R - UViT包括一个局部和全局的多头自注意力( LG-MSA )模块,以增强所有智能体空间位置上的特征交互,以容忍不确定性的缺陷;还包括一个不确定性感知模块( UAM ),通过考虑不同不确定性水平的共享其他智能体特征来增强自我智能体的特征.(2)S2R-AFA:基于S2R Agent的特征自适应以缩小特征差距。S2RAFA利用智能体间和自我代理的判别器提取领域不变特征,以弥合feature gap。
Uncertainty-aware vision Transformer,可有效缓解development gap带来的不确定性.
通过一个S2R agent-based feature adaptation利用代理间和自我代理判别器提取domain-invariant features. 注意这里domain-invariant features已经被之前的2024的DI-V2X文章提到了,但这里更偏重虚拟到显示,而DI-V2X偏重代理的不同.
相关工作
Multi-Agent Perception.多智能体感知系统通过智能体之间的通信技术,能够克服遮挡和短距离感知的挑战,实现大范围感知,引起了众多研究者的关注.与交换原始传感数据或检测输出相比,当代方法通常共享由神经网络提取的中间特征.该策略在精度和带宽需求之间提供了一个最佳的平衡.
Challenges in Multi-Agent Perception:多Agent感知系统也引入了一些新的挑战,如定位误差、通信延迟、对抗攻击等。这些挑战可能会减少合作的好处.
Domain Adaptation for Perception:领域自适应是指将源领域训练的机器学习模型自适应到目标领域。许多领域自适应工作主要集中在RGB相机数据,而在LiDAR数据中提出了更多的领域自适应工作来解决这一问题.
与交换原始传感数据或检测输出相比,当代方法通常共享由神经网络提取的中间特征.
这种策略在精度和带宽需求之间提供了一个最佳的平衡.
方法

S2R-ViT。从其他周围CAV聚合的中间特征被输入到我们的主要组件S2R - ViT中,该组件由S2R - UViT和S2R - AFA模块组成。在接收到最终的融合特征后,我们利用预测头进行3D物体分类和定位
从仿真到现实的部署差距给自我和邻居智能体带来了不同的不确定性,例如GPS误差导致的空间偏差,通信延迟导致的坐标投影中的空间错位
在本文中提出从两个角度来回答这个问题:不确定性可以通过增强( 1 )所有智能体空间位置上的特征交互来更全面地缓解;( 2 )通过考虑不同不确定性水平的共享其他智能体特征来缓解自我-智能体特征。
这两个视角促使我们分别开发了新颖的局部-全局多头自注意力( LG-MSA )模块和不确定性感知模块( UAM )。
局部和全局多磁头自注意力机制( Local-and-Global多头Self Attention,LGMSA ):为了更全面地增强所有智能体空间位置上的特征交互,我们提出了LG - MSA来促进所有智能体空间位置上的局部和全局特征交互。在提出的LGMSA中,基于局部特征的注意力用于关注空间特征的局部细节,而基于全局特征的注意力用于关注空间特征的广泛范围。就是一个融合模块,使用不同窗口大小的类似swin-transformer模型.
以h = 8为头数,n = 2为窗口类型数,将标准多头自注意力模块( MSA ) [ 24 ]的多头h均匀划分为2组不同窗口大小,即局部分支为4 × 4,全局分支为8 × 8。在局部分支中,将分割后的特征F^l^~e,o~∈R^h/n×H×W×kC/h^以4 × 4的小窗口尺寸输入MSAL,以增强空间特征的局部细节。在全局分支中,另一个分裂特征F^g^~e,o~∈R^h/n×H×W×kC/h^以8 × 8的大窗口尺寸输入MSAG以捕获全局空间特征信息
Uncertainty-Aware Module (UAM).
不确定性图,说白了得到一个跟特征图大小一样的map对除了ego代理的特征进行选择,这种设计在其他很多方法中都涉及.
以中位数为阈值,将具有高不确定度等级(即,低置信度)的预测不确定度等级图M中的特征值重置为1.
UPN是由简化而来的基于编码器-解码器的神经网络,可以在我们整个架构的端到端训练过程中学习.
受进化机制中自然选择的启发,以中位数为阈值,将具有高不确定性水平(即,低置信度)的预测不确定性水平图M中的特征值重置为1.它产生了一个新的不确定性等级图M~t~ .
基于共享的他者-施动者特征来增强自我-施动者特征,不应忽视其不同的不确定性水平.
Δ [ · ]表示阈值过程,⊛表示矩阵点积。
S2R-AFA: simultaion-to-Reality Agent-based Feature Adaptation.
为了缩小仿真特征Fs与真实特征Fr之间的特征差距,在融合前和融合后分别设计了两个领域判别器/分类器,使用BCE损失用于二分类.
E~s,r~分别表示仿真和现实中的领域分类误差,G~m~是我们的整体模型(主干网、S2R - UViT和检测头),可以认为是生成对抗网络的生成器.
由于S2R - AFA,我们的生成模型G~m~将具有提取模拟和现实的域不变特征的能力. 损失包含目标检测损失和Agent-based Feature Adaptation损失.
DUSA: Decoupled Unsupervised Sim2Real Adaptation for Vehicle-to-Everything Collaborative Perception MM
Abstract
车联网( Vehicle-to-Ething,V2X )协同感知对于自动驾驶的推进至关重要。然而,实现高精度的V2X感知需要大量有标注的真实世界数据,而这些数据往往是昂贵和难以获得的。
由于模拟数据可以以极低的成本大规模生产,因此受到了广泛的关注。然而,模拟数据和真实世界数据之间显著的域差距,包括传感器类型、反射模式和道路环境的差异,往往导致在模拟数据上训练的模型在真实世界数据上评估时性能较差。
此外,现实世界中的协作智能体之间仍然存在域间鸿沟,例如不同类型的传感器可能安装在具有不同外在特征的自动驾驶车辆和路边基础设施上,进一步增加了sim2现实泛化的难度。
为了充分利用模拟数据,提出了一种新的用于V2X协作检测的无监督Sim2真实域自适应方法,称为解耦无监督Sim2real域自适应( Decoupled Unsupervised Sim2Real Adaptation,DUSA )。
我们的新方法将V2X协作sim2真实域自适应问题解耦为sim2real域自适应和智能体间自适应两个子问题。对于sim2real自适应,我们设计了一个位置自适应的Sim2Real Adapter ( LSA )模块,从特征图的关键位置自适应地聚合特征,并在聚合的全局特征上通过sim / real判别器对模拟数据和真实数据之间的特征进行对齐。对于智能体间自适应,我们进一步设计了一个置信度感知的智能体间适配器( Confidence-aware Inter-agent Adapter,CIA )模块,在智能体间置信图的指导下,对来自异构智能体的细粒度特征进行对齐。
实验证明了本文提出的DUSA方法在从模拟的V2XSet数据集到真实的DAIR -V2X-C数据集的无监督sim2real自适应上的有效性。
相关工作
Collaborative 3D Object Detection
利用协作感知来支持单车的自动驾驶已经成为一个越来越受关注的研究课题。方法Cooperative Perception for 3D Object Detection in Driving Scenarios Using Infrastructure Sensors 首先介绍了车辆和基础设施之间的协同感知系统中的早期和晚期融合方案。
WIBAM模型提出了一种使用弱监督来微调交通观测相机模型的技术
Cooper利用来自多个车辆的原始点云,开发了SPOD网络。F-Cooper 在Cooper的基础上实现了特征级融合,在保证精度的同时减少了通信数据量。
V2VNet 引入了中间融合方法,该方法使用一种感知空间关系的图神经网络来合并来自多个车辆的数据。DiscoNet 使用知识蒸馏来训练一个椎间盘造影术,这有助于在多智能体感知中实现性能和带宽使用之间的最佳平衡。V2X-ViT 提出了一种视觉transformer框架来实现车辆和基础设施之间的特征融合。SyncNet解决了时域同步问题。where2comm 提出使用空间置信图来减少所需的通信带宽量。这是通过限制不必要数据的传输来实现的。CoBEVT 利用融合的轴向注意力来协同生成多个智能体和相机之间的鸟瞰图( BEV )预测。AdaFusion 提出了3种自适应模型用于鸟瞰图( BEV )中的特征融合,以提高感知精度。MPDA识别了在不同代理之间出现的域间隙问题,并通过使用完整的特征图来标准化模式来解决。
Unsupervised Domain Adaptation
无监督领域自适应( UDA )旨在利用有标签的源数据和无标签的目标数据,生成一个能够有效泛化到目标领域的鲁棒模型。许多工作利用对抗学习,通过最小化两个域之间的H -散度或Jensen - Shannon散度来对齐不同域之间的特征分布。另一类方法针对未标记的目标域开发多种伪标签,实现自训练
在三维目标检测的领域自适应方面,PointDAN 是第一个使用对抗学习来匹配具有非自动驾驶场景的领域之间点云分布的方法。
SN利用来自目标域的对象统计信息对源域中的对象大小进行归一化处理,以减少大小层次上的域间隙。
SRDAN提出了尺度感知和范围感知的域对齐策略,利用三维数据的几何特征来指导两个域之间的分布对齐。MLC-Net 采用师生范式,利用多层一致性来促进跨域迁移。ST3D 提出了一种基于随机对象缩放策略的伪标签生成和训练过程的综合流水线。此外,ST3D + +进一步提出了3D UDA背景下去噪伪标注的优化策略。
在这项工作中,我们解决了面向V2X协作3D检测的无监督sim2real域适应问题。在这个问题中,我们有一组带有标签的模拟样本作为源域,一组未标记的真实世界样本作为目标域。每个样本包含多个协同智能体,每个智能体包含一个LiDAR点云及其在世界坐标下的位姿。协作代理可以在传感器类型和位置等方面具有异构性。我们期望该模型能够充分地利用已标注的模拟样本来提高其在未标注的真实世界样本上的性能。
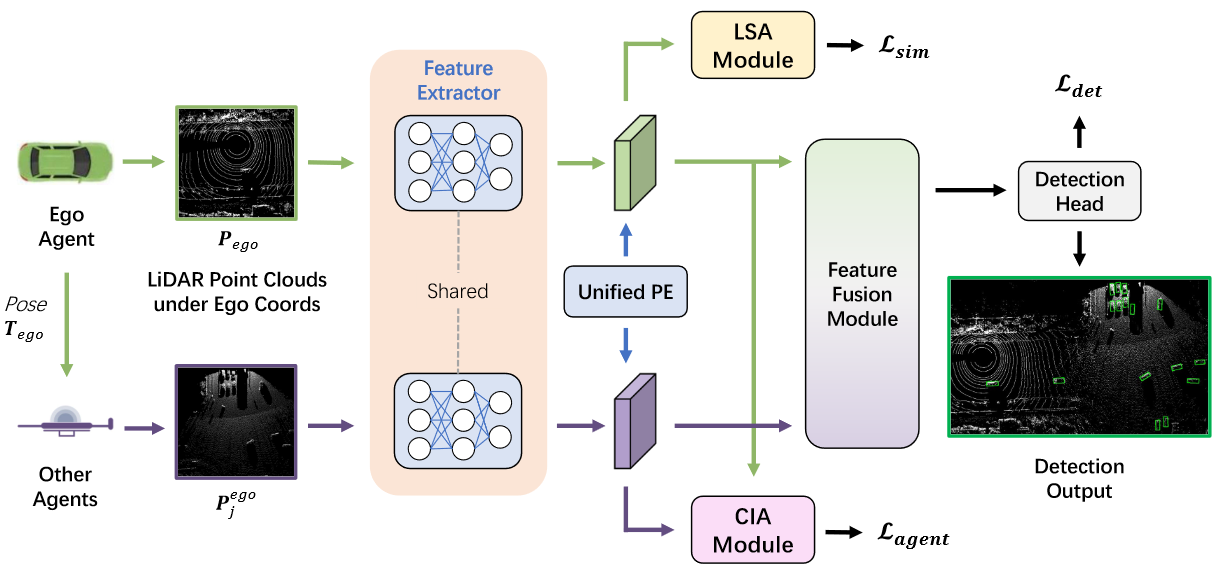
在自适应之前,一个统一的位置编码被连接到每个代理的特征上。我们将具有位置编码的特征记为” F ( Xi ; θ) “。统一位置编码是一个2D坐标,表示与自我主体的相对距离。这样,与自我代理距离相近的位置将被分配到相同的坐标。
LSA模块和CIA模块在训练过程中对齐来自不同域和代理的特征。LSA模块引入了自我Agent的特征,并区分Agent是来自仿真还是真实世界。CIA模块接收每个真实世界Agent的特征和置信图,并判别Agent的类型。两个模块鼓励特征提取器通过对抗训练产生sim / real - invariant和agent - invariant特征,其中两个模块和特征提取器的训练目标是相反的。
与简单区分所有协作Agent是模拟的还是真实的相比,DUSA将区分问题解耦为两个更具体、更少纠缠的子任务,即sim / real区分和Agent类型区分。解耦后的任务可以让判别器发现更详细的域间隙,并通过对抗训练增加特征提取器的域不变性。
Location-adaptive Sim2Real Adapter
位置自适应的Sim2Real Adapter ( LSA )模块旨在弥合模拟数据和真实世界数据之间的域鸿沟。为了将智能体之间的域间隙从sim / real域间隙中完全排除,LSA模块只对具有相对相似传感器的智能体进行特征区分。从这两个领域中选择自我主体的特征” F (ego Pego ) ; θ) “来进行区分,因为他们通常在顶部安装有机械式激光雷达,无论他们来自模拟还是真实数据.
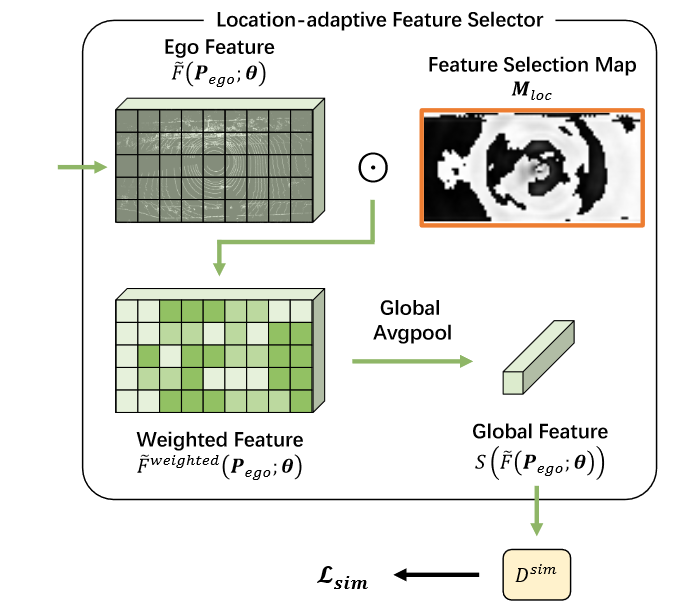
单个主体的显著位置分布有其内在规律。例如,靠近智能体的网格通常比远离智能体的网格拥有更多的领域线索,因为它们通常在附近的车辆上拥有更多的LiDAR点。此外,车辆前方的网格通常比车辆后方的网格更加显著。因此,我们设计了一个位置自适应的特征选择器模块,根据分布自适应地选择重要的特征。具体来说,我们使用一个可学习的特征选择图M~loc~来捕获分布的内部模式,并相应地从自我代理的特征图中选择具有重要意义的特征
然后使用全局平均池化操作来获得一个全局特征
我们对聚合后的全局特征S ( “ F “ ( P~ego~ ; θ) )进行sim / real判别。sim / real鉴别器包含若干个全连接层,具有ReLU激活和Dropout.我们将其记为D^sim^( · ; wsim),其中w^sim^是sim / real判别器的参数.
为了联合优化方程中的最大最小化优化问题,在LSA模块的输入之前插入一个梯度反转层( GRL ).
通过这样做,可以在单步内完成优化
Confidence-aware Inter-agent Adapter
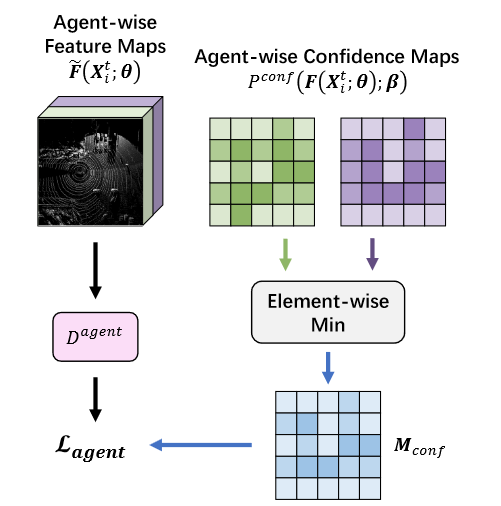
置信度感知的智能体适配器( CIA )模块旨在最小化现实世界中异构智能体之间的领域差距。它专注于识别真实世界智能体的细粒度特征图” F ( Xt i ; θ) “,排除了仿真和真实世界之间的领域差距。
我们对来自目标域(真实世界)的智能体细粒度特征图” F ( Xt i ; θ) “进行智能体间判别。智能体间判别器包括若干个具有ReLU激活的1 × 1卷积层。我们将其记为D^agent^ ( · ; w^agent^),其中w agent是agent间判别器的参数.
在智能体细粒度特征图中,存在一些几乎没有网格的网格,这些网格中的点非常少。因此,这些网格包含很少的关于传感器的线索,并且不适合进行智能体之间的区分。在这些网格上监督智能体之间的鉴别器可能会在梯度中包含噪声,并增加优化过程的不稳定性。为了解决这个问题,我们提出利用智能体间的置信图来reweight智能体间的区分度损失。
然后使用重称map M~conf~重新平衡每个网格的损失。
L~CE~为交叉熵损失,j表示agent个数。在CIA模块的输入之前还插入了一个梯度反转层( GRL )
Baselines
对比方法分为self-training和Naive sim/real discriminator.
自训练在伪标签生成和微调之间交替进行。具体来说,协同检测模型首先在已标记的源域上训练,直到收敛,然后为未标记的目标域预测具有置信度分数的边界框。对预测结果应用一个置信度阈值来获得伪标签。然后,模型用生成的伪标签在目标域上微调自己。基线方法在两个进展之间交替进行,迭代地学习目标域的新分布
朴素的sim / real判别器只是简单地判别协作智能体是来自仿真还是来自真实世界,而不考虑智能体之间的异质性。具体来说,我们还在已标注的源域上预训练协作检测模型,直到收敛。然后,使用类似于Dsim的判别器来区分所有智能体F ( Xi ; θ)提取的特征是来自仿真还是真实世界。鉴别器通过GRL与检测器联合优化。对朴素sim / real判别器的监督也类似于对LSA模块的监督
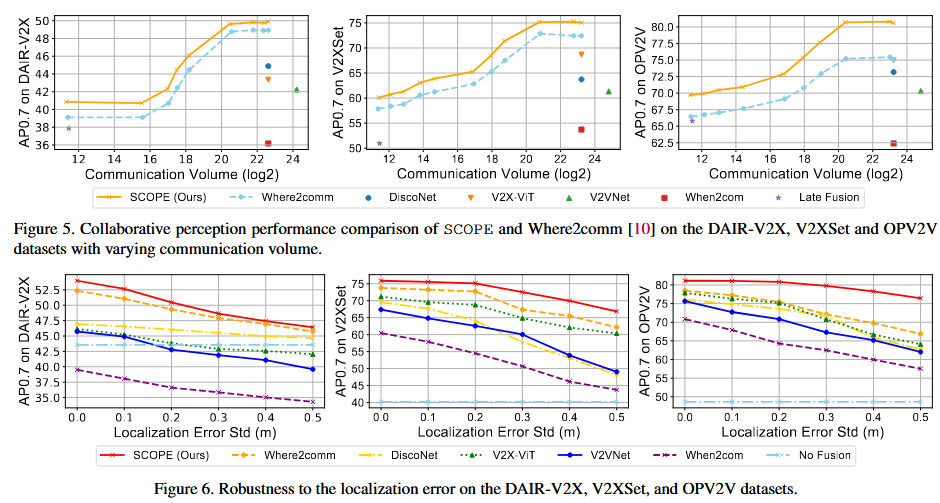
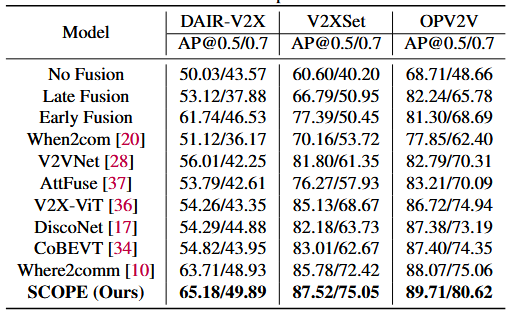
相关论文结果对比
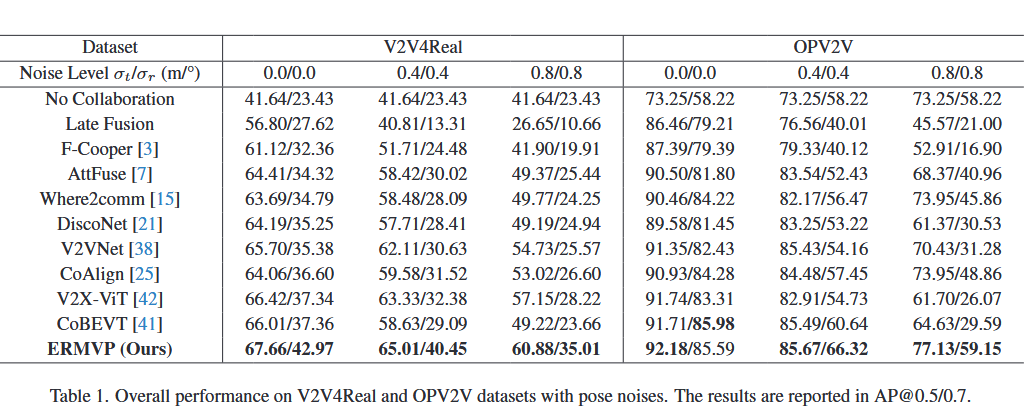
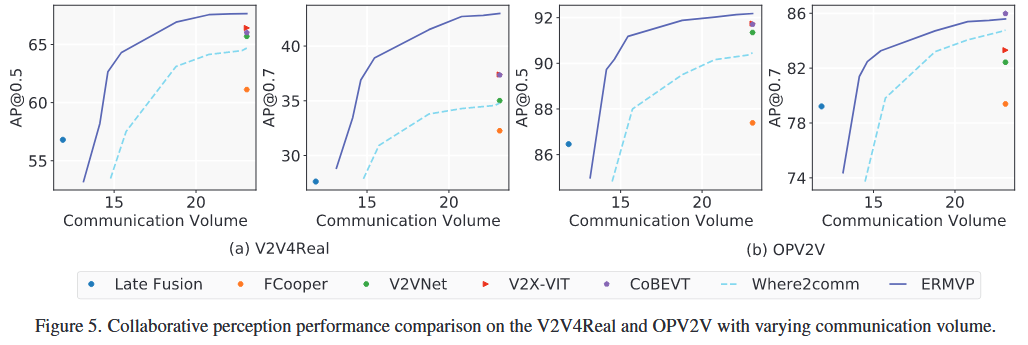
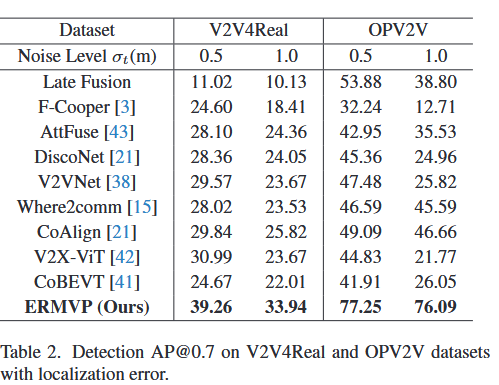
ERMVP
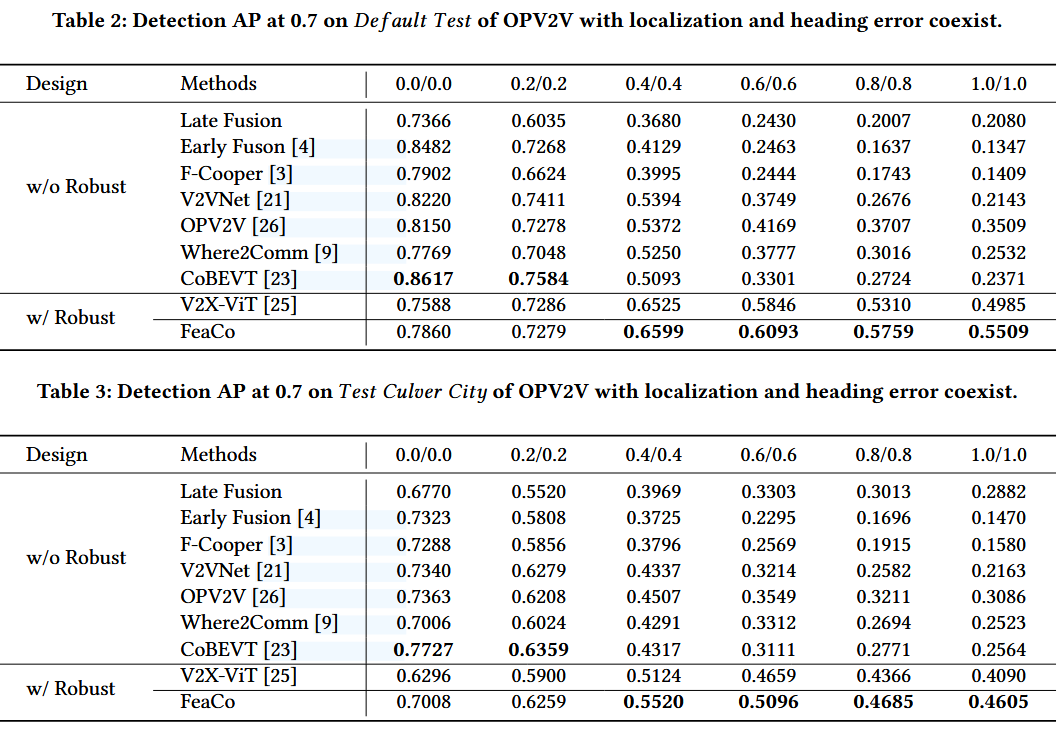
FeaCo
How2Comm
0.2/0.2的噪声下
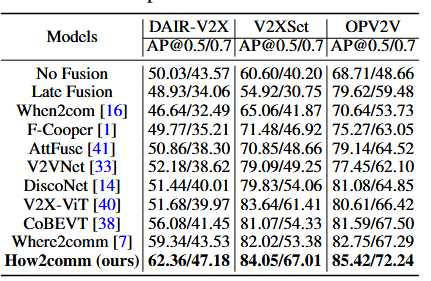
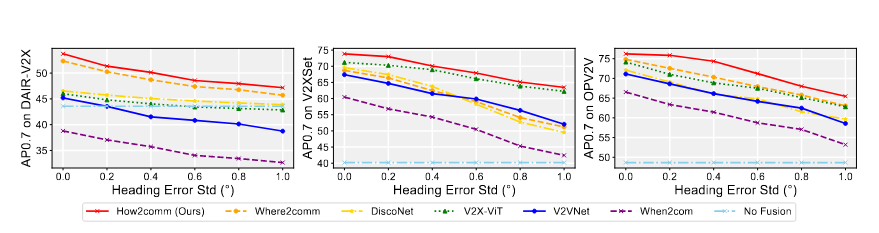
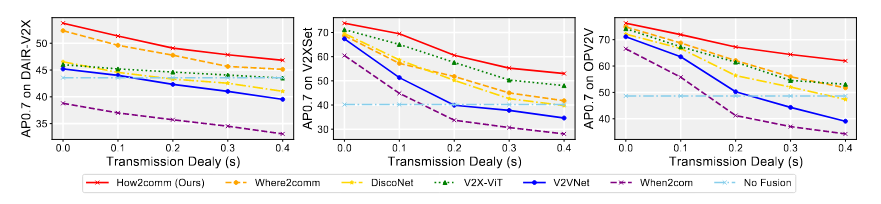
What2Com
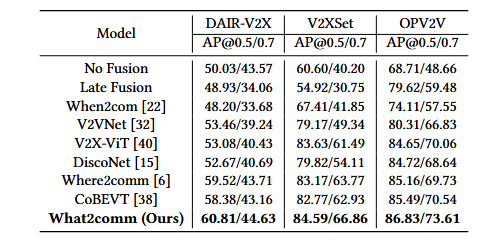
SCOPE