c++在网络编程中特别普及,特别是Linux服务器编程. 相关书籍也有很多,这里简单介绍一下(结合AI总结).
重要的数据结构
套接字地址
PF_INET:指的是协议族(Protocol Family),强调的是协议相关的概念。
AF_INET:指的是地址族(Address Family),关注的是地址格式。
虽然在许多实现中
PF_INET和AF_INET可以互换使用,但理论上它们代表不同的概念。为了保持代码的清晰性和一致性,推荐的做法是在创建套接字时使用AF_INET来指代地址族,而保留PF_INET用于协议族相关的上下文。不过,由于历史原因和广泛接受的习惯,这种区别在实践中往往被忽略。
在进行网络编程时,sockaddr_in、sockaddr 和 addrinfo 是三个不同的数据结构,它们各自有不同的用途和特点。
sockaddr
定义:
1
2
3
4struct sockaddr {
sa_family_t sa_family; // 地址族(如AF_INET, AF_INET6)
char sa_data[14]; // 地址信息,具体格式取决于地址族
};用途:
- 这是一个通用的套接字地址结构体,用于表示任何类型的套接字地址。它不特定于任何一种协议或地址家族。
- 它通常作为函数参数传递,以便支持多种不同类型的地址族(例如IPv4、IPv6等)。
局限性:
- 因为它的
sa_data字段是固定大小的字符数组,所以在处理复杂或长度不定的地址信息时不够灵活。
- 因为它的
sockaddr_in
定义:
1
2
3
4
5
6
7
8
9
10struct sockaddr_in {
sa_family_t sin_family; // 地址族,必须设置为AF_INET
in_port_t sin_port; // 端口号(使用htons()转换为网络字节序)
struct in_addr sin_addr; // IPv4地址
unsigned char sin_zero[8]; // 填充0以使结构体大小与sockaddr相同
};
struct in_addr {
in_addr_t s_addr; // 32位IPv4地址(网络字节序)
};用途:
- 专门用于IPv4地址的套接字地址结构体。
- 提供了明确的字段来存储端口号和IP地址,使得处理IPv4地址更加直观和方便。
优点:
- 相较于
sockaddr,它提供了更具体的字段,便于操作IPv4地址和端口信息。
- 相较于
sockaddr_in61
2
3
4
5
6
7
8struct sockaddr_in6
{
__SOCKADDR_COMMON (sin6_);
in_port_t sin6_port; /* Transport layer port # */
uint32_t sin6_flowinfo; /* IPv6 flow information */
struct in6_addr sin6_addr; /* IPv6 address */
uint32_t sin6_scope_id; /* IPv6 scope-id */
};
addrinfo
定义:
1
2
3
4
5
6
7
8
9
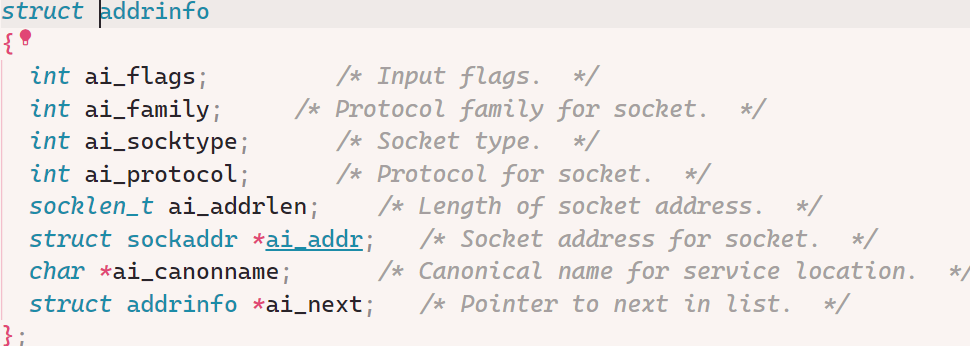
10struct addrinfo {
int ai_flags; // AI_PASSIVE, AI_CANONNAME, etc.
int ai_family; // AF_INET, AF_INET6, AF_UNSPEC
int ai_socktype; // SOCK_STREAM, SOCK_DGRAM
int ai_protocol; // 使用的协议
socklen_t ai_addrlen; // 地址长度
struct sockaddr *ai_addr; // 地址信息
char *ai_canonname; // 主机规范名称
struct addrinfo *ai_next; // 下一个addrinfo结构指针
};![image-20250227150905975]()
用途:
addrinfo结构体由getaddrinfo()函数返回,旨在提供一个统一的方式来处理不同类型的地址信息(包括IPv4和IPv6),并简化了主机名和服务名解析的过程。- 它可以包含多个结果(通过
ai_next链表连接),允许应用程序选择最适合其需求的结果。
优点:
- 支持现代互联网中常见的IPv4和IPv6地址。
- 能够处理复杂的配置需求,如指定被动监听(AI_PASSIVE)、获取规范主机名等。
- 更加灵活和强大,适合需要跨平台兼容性和灵活性的应用程序。
sockaddr_storage
sockaddr_storage 是一个在 <netinet/in.h> 或 <sys/socket.h> 头文件中定义的数据结构,旨在提供一个足够大的缓冲区来存储任何类型的套接字地址(包括 IPv4、IPv6 等)。它解决了由于不同协议族的地址结构大小不一致所带来的问题,例如 sockaddr_in 和 sockaddr_in6 分别用于 IPv4 和 IPv6 地址,它们有不同的大小。
定义与用途1
2
3
4struct sockaddr_storage {
sa_family_t ss_family; // 地址族
// 其余字段未指定,实现定义以确保足够的空间和对齐
};
- ss_family:这是唯一标准化的字段,表示地址族(如
AF_INET对应 IPv4,AF_INET6对应 IPv6)。 - 其他字段:这些字段的具体定义依赖于实现,主要是为了确保
sockaddr_storage能够容纳所有可能的套接字地址类型,并且保持正确的内存对齐。这意味着它的大小至少要能容纳最大的套接字地址结构(比如sockaddr_in6)。
主要特点
- 统一性:通过使用
sockaddr_storage,可以编写更加通用的代码,避免直接处理特定于协议的地址结构(如sockaddr_in或sockaddr_in6),从而提高代码的可移植性和灵活性。 - 大小保证:
sockaddr_storage的大小被设计为足以容纳系统支持的所有套接字地址结构,这使得它可以安全地转换为任何特定的套接字地址类型。 - 对齐要求:除了大小之外,
sockaddr_storage还满足了所有套接字地址结构的对齐要求,这对于高效访问数据至关重要。
总结
sockaddr:是一个通用的套接字地址结构体,适用于所有地址族。由于其设计较为通用,实际应用中常被特定于某种地址族的结构体替代,如sockaddr_in。sockaddr_in:专用于IPv4地址,提供了对IPv4地址和端口的具体支持,易于理解和使用。addrinfo:提供了一个更高级别的抽象,能够处理IPv4和IPv6地址,并且支持更多的选项和灵活性。它是推荐的方式来进行现代网络编程中的地址解析和套接字创建,特别是当你需要同时支持IPv4和IPv6时。
socketpair
socketpair 是一个用于创建一对互联的套接字描述符的系统调用,它允许在同一主机上的两个进程之间进行双向通信。通常,这些套接字被用于父子进程间的通信,但它们也可以用于任何需要双向(全双工)通信通道的场景1
2
3
4
int socketpair(int domain, int type, int protocol, int sv[2]);
- 参数:
domain:指定协议族,通常是AF_UNIX或AF_LOCAL(本地通信),但在某些实现中也可能支持其他域如AF_INET。type:指定套接字类型,常见的有SOCK_STREAM(提供有序、可靠、双向的连接)和SOCK_DGRAM(数据报套接字)。protocol:指定使用的协议,通常为0,表示使用默认协议。sv:指向一个包含两个整数元素的数组,这两个整数将作为返回的套接字描述符。
- 返回值:
- 成功时,返回
0并在sv数组中填充两个有效的套接字描述符。 - 失败时,返回
-1并设置errno。
- 成功时,返回
1 |
|
地址二进制与点分十进制转换
在网络编程中,有时需要将点分十进制表示的IPv4地址(如"192.168.1.1")转换成32位无符号整数形式以便于处理或计算。在C语言中,可以使用以下函数来实现这种转换:
inet_addr: 这是一个简单的函数,用于将点分十进制格式的IPv4地址转换为网络字节序的32位长整型值。然而,它不支持IPv6,并且如果输入无效,则返回INADDR_NONEinet_aton: 此函数不仅将点分十进制的IPv4地址转换为二进制形式,还会检查输入的有效性。它接受一个指向in_addr结构的指针作为第二个参数,并在此结构中填充相应的数值。如果转换成功,返回非零值;否则返回0inet_pton: 这是一个更为现代和推荐使用的函数,支持IPv4和IPv6地址的转换。对于IPv4,它的第二个参数是一个指向struct in_addr类型的指针,对于IPv6,则是指向struct in6_addr类型的指针。如果转换成功,返回1;如果输入格式不正确,则返回0;如果遇到系统错误,则返回-1。
| 特性 | inet_addr | inet_aton |
|---|---|---|
| 输入格式 | 点分十进制字符串 | 点分十进制字符串 |
| 输出格式 | 返回 in_addr_t(32 位整数) | 填充 struct in_addr 结构体 |
| 错误处理 | 错误时返回 INADDR_NONE | 错误时返回 0 |
| 线程安全性 | 安全 | 安全 |
| 推荐程度 | 不推荐(已过时) | 推荐 |
| 函数名 | 输入格式 | 输出格式 | 支持的地址类型 | 线程安全性 |
|---|---|---|---|---|
inet_pton | 字符串 | 二进制 | IPv4 和 IPv6 | 安全 |
inet_aton | 字符串 | 二进制 | 仅 IPv4 | 安全 |
inet_ntop | 二进制 | 字符串 | IPv4 和 IPv6 | 安全 |
inet_ntoa | 二进制 | 字符串 | 仅 IPv4 | 不安全 |
端口字节序转换
在网络编程中,处理不同系统间的数据传输时,经常需要将数据在主机字节序(Host Byte Order)和网络字节序(Network Byte Order)之间进行转换。这是因为不同的计算机架构可能使用不同的字节序来存储多字节数据类型,如整数。为了确保数据在网络上传输的一致性,通常采用大端字节序(Big Endian),也被称作网络字节序
针对这种需求,有几组常用的函数用于在主机字节序和网络字节序之间进行转换:
htonl和htons:这两个函数分别用于将32位整型(long)和16位整型(short)从主机字节序转换为网络字节序。htonl(uint32_t hostlong): Host to Network Longhtons(uint16_t hostshort): Host to Network Short
ntohl和ntohs:与上述相反,这两个函数用于将32位和16位整型从网络字节序转换为主机字节序。ntohl(uint32_t netlong): Network to Host Longntohs(uint16_t netshort): Network to Host Short
为了保证网络通信的兼容性,通常采用大端字节序(Big Endian),也称为网络字节序,来表示跨网络传输的数据。
需要转换为网络字节序的数据类型
- 端口号:端口号通常是16位的整数,在发送之前应该从主机字节序转换为网络字节序。
- IP地址:虽然IP地址通常以字符串形式表示(例如“192.168.0.1”),但在某些情况下,你可能会处理32位整型的IPv4地址或128位的IPv6地址。对于这些情况,如果需要直接操作整型值,则应确保它们是网络字节序。
- 序列号、确认号等TCP头部字段:这些字段都是32位的整数,用于TCP协议中的状态跟踪和数据流控制,因此也需要转换为网络字节序。
- 其他自定义协议中的多字节字段:如果你设计了一个自定义的应用层协议,并且该协议包含多字节整数字段(如长度指示符、版本号等),那么这些字段也应该按照网络字节序进行编码。
设置套接字等选项
setsockopt 是一个用于设置套接字选项的函数,它允许开发者对套接字的行为进行精细控制。通过 setsockopt,可以调整套接字的各种属性,例如地址复用、接收/发送缓冲区大小、超时时间等。1
2
3
int setsockopt(int sockfd, int level, int optname, const void *optval, socklen_t optlen);
sockfd:- 套接字描述符。
- 指定要设置选项的目标套接字。
level:- 选项所属的协议层。
- 常见值包括:
SOL_SOCKET: 套接字通用选项(如地址复用、广播等)。IPPROTO_TCP: TCP 协议相关选项。IPPROTO_IP: IP 协议相关选项。IPPROTO_IPV6: IPv6 相关选项。
optname:- 具体的选项名称。
- 根据
level的不同,可以选择不同的选项。
optval:- 指向选项值的指针。
- 选项值的具体类型和格式取决于
optname。
optlen:optval缓冲区的大小(以字节为单位)
1 | int opt = 1; |
常用选项
SO_REUSEADDR
- 作用: 允许绑定到已被占用的地址和端口。
- 场景: 通常用于避免因端口被占用而导致服务器无法启动的问题。
2. SO_REUSEPORT
- 作用: 允许多个进程或线程绑定到同一个端口。
- 场景: 适用于多线程或多进程服务器模型。
- 注意: 需要与
SO_REUSEADDR配合使用
3. SO_RCVBUF 和 SO_SNDBUF
作用
:
SO_RCVBUF: 设置接收缓冲区大小。SO_SNDBUF: 设置发送缓冲区大小。
4. SO_BROADCAST
- 作用: 启用广播功能。
- 场景: 用于 UDP 广播通信
5. SO_KEEPALIVE
- 作用: 启用 TCP 的保活机制。
- 场景: 检测长时间空闲的连接是否仍然有效。
6. SO_LINGER
- 作用: 控制关闭套接字时的行为。
- 场景: 当需要确保所有数据在关闭前被发送时。
7. TCP_NODELAY
- 作用: 禁用 Nagle 算法,减少小数据包的延迟。
- 场景: 对于实时性要求较高的应用(如在线游戏、实时聊天)。
设置文件描述符选项
函数原型1
2
int fcntl(int fd, int cmd, ... /* arg */ );
fd:目标文件描述符。cmd:指定要执行的操作类型,常见的命令包括:
F_GETFL:获取文件描述符的状态标志。F_SETFL:设置文件描述符的状态标志。F_GETFD:获取文件描述符的文件描述符标志。F_SETFD:设置文件描述符的文件描述符标志。F_DUPFD:复制文件描述符。F_DUPFD_CLOEXEC:复制文件描述符并设置FD_CLOEXEC标志。
arg:可选参数,具体取决于cmd的值。例如,在使用F_SETFL时,arg是新的状态标志
在网络编程中,将套接字设置为非阻塞模式是一种常见的优化手段。非阻塞模式允许在尝试读取或写入数据时立即返回,而不会阻塞进程。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// 将文件描述符设置为非阻塞模式
int set_nonblocking(int fd) {
int flags = fcntl(fd, F_GETFL, 0); // 获取当前文件描述符的标志
if (flags == -1) {
perror("fcntl F_GETFL failed");
return -1;
}
// 添加 O_NONBLOCK 标志
if (fcntl(fd, F_SETFL, flags | O_NONBLOCK) == -1) {
perror("fcntl F_SETFL failed");
return -1;
}
return 0;
}
在非阻塞模式下:
- 如果没有数据可读,
read()或recv()会立即返回-1,并设置errno为EAGAIN或EWOULDBLOCK。 - 如果无法立即写入数据,
write()或send()也会返回-1,并设置errno为EAGAIN或EWOULDBLOCK。
文件状态标志可以通过 fcntl(fd, F_GETFL) 获取当前设置,并通过 fcntl(fd, F_SETFL, flags) 修改。
O_RDONLY,O_WRONLY,O_RDWR:打开文件的模式(只读、只写、读写),通常在打开文件时确定,不能通过F_SETFL修改。O_APPEND:每次写入时将数据追加到文件末尾。O_NONBLOCK:设置非阻塞模式。对于文件或设备,这意味着尝试的操作(如读取或写入)如果无法立即完成,则会立即返回而不是阻塞等待。在网络编程中,这通常用于套接字以实现异步I/O。O_ASYNC:当I/O可用时发送信号(通常是SIGIO)给进程。此功能允许进程异步地处理I/O事件。O_DSYNC和O_SYNC:要求同步写入。O_DSYNC确保数据同步写入磁盘,而O_SYNC还包括文件元数据的同步写入。
在 TCP 套接字中,
read()和recv()都无法保证一次调用就能读取完整的数据包。可能需要循环读取,直到接收到完整的数据。如果套接字是非阻塞模式,且没有数据可读,
read()会立即返回-1,并设置errno为EAGAIN或EWOULDBLOCK。
- 如果套接字是阻塞模式,且没有数据可读,
read()会阻塞,直到有数据到达或发生错误。read()不区分消息边界(特别是在 TCP 套接字中)。它只是简单地从流中读取尽可能多的数据。非阻塞模式
- 在非阻塞模式下,如果没有数据可读,
read()和recv()都会立即返回-1,并设置errno为EAGAIN或EWOULDBLOCK。- 在这种情况下,通常需要结合事件通知机制(如
select()、poll()或epoll())来监听可读事件。错误处理
- 处理
EINTR(信号中断):如果read()或recv()返回-1并且errno为EINTR,通常需要重试。- 处理
EAGAIN或EWOULDBLOCK:说明当前没有更多数据可读,等待下次事件通知即可。
信号机制
信号是操作系统向进程发送的一种异步通知机制,用于告知进程某个事件已经发生。信号可以被视为一种软件中断,它会打断进程的正常执行流程。
signal
signal() 函数
这是最基本的信号处理函数,用于设置对指定信号的处理方式。然而,它不如 sigaction 灵活和可靠。1
2
3
4
5
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);
signum:要捕获或忽略的信号编号。handler:信号处理函数指针,或者SIG_DFL(默认处理)、SIG_IGN(忽略)。
1 |
|
Linux 定义了许多标准信号,例如:
SIGINT(2):由用户按下Ctrl+C触发,通常用于终止进程。SIGTERM(15):请求终止进程的信号。SIGKILL(9):强制终止进程的信号,无法被捕获或忽略。SIGSEGV(11):段错误(访问非法内存地址)。SIGCHLD(17):子进程状态改变时发送给父进程的信号。SIGUSR1和SIGUSR2:用户自定义信号。
信号可以通过以下几种方式触发:
(1) 用户输入
- 按下
Ctrl+C会向当前前台进程发送SIGINT信号。 - 按下
Ctrl+\会向当前前台进程发送SIGQUIT信号。
(2) 系统调用
通过系统调用 kill 或 raise 可以向进程发送信号:
kill(pid_t pid, int sig):向指定进程 ID 的进程发送信号。raise(int sig):向当前进程自身发送信号。
(3) 硬件异常
当进程访问非法内存地址时,操作系统会发送 SIGSEGV 信号;当进行非法指令操作时,可能会发送 SIGILL 信号。
(4) 软件触发
通过调用 alarm 函数可以设置定时器,超时时会向进程发送 SIGALRM 信号。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
void handler(int sig) {
printf("Received signal: %d\n", sig);
}
int main() {
signal(SIGALRM, handler); // 注册信号处理函数
alarm(3); // 设置 3 秒后发送 SIGALRM 信号
printf("Waiting for the alarm signal...\n");
pause(); // 挂起进程,等待信号
return 0;
}
sigaction
sigaction 是 POSIX 标准定义的一种机制,用于定义进程对特定信号的响应行为。它提供了一种比 signal() 更加灵活和强大的方式来处理信号。sigaction 结构体用于指定如何处理信号、信号处理程序的属性以及信号掩码等信息。
sigaction 提供了比 signal() 更加精细和强大的信号处理功能。1
2
int sigaction(int signum, const struct sigaction *act, struct sigaction *oldact);
- 参数:
signum:信号编号。act:指向包含新动作的struct sigaction结构体的指针。oldact:如果非空,则保存旧的动作。
struct sigaction 结构体1
2
3
4
5
6
7struct sigaction {
void (*sa_handler)(int); // 信号处理函数
void (*sa_sigaction)(int, siginfo_t *, void *); // 用于带有附加信息的信号处理函数
sigset_t sa_mask; // 在执行信号处理器期间需要阻塞的信号集合
int sa_flags; // 控制信号处理的行为标志
void (*sa_restorer)(void); // 已废弃,不应使用
};
sigaction 结构体用于指定如何处理信号、信号处理程序的属性以及信号掩码等信息。
字段说明
sa_handler:- 这是一个指向信号处理函数的指针,或者可以设置为
SIG_DFL(默认信号处理)或SIG_IGN(忽略信号)。
- 这是一个指向信号处理函数的指针,或者可以设置为
sa_sigaction:- 当
sa_flags中设置了SA_SIGINFO标志时,此字段将作为信号处理函数使用。与sa_handler不同,sa_sigaction可以接收更多信息,包括一个指向siginfo_t结构的指针(包含有关信号的详细信息)和一个指向处理器上下文的指针(通常不使用)。
- 当
sa_mask:- 定义了一个信号集,在调用信号处理程序之前,这些信号会被加入到当前的信号屏蔽字中。这意味着在执行信号处理程序期间,这些信号会被暂时阻塞。
sa_flags:- 控制信号处理的行为。常见的标志包括:
SA_RESTART:如果信号中断了某个系统调用,则自动重启该系统调用(而不是返回错误)。SA_NOCLDSTOP:仅对SIGCHLD信号有效,如果设置了此标志,则子进程停止或恢复时不会发送SIGCHLD信号给父进程。SA_NOCLDWAIT:仅对SIGCHLD信号有效,阻止创建僵尸进程。SA_SIGINFO:指示使用sa_sigaction字段中的信号处理函数,而非sa_handler。这允许访问扩展的信号信息。
- 控制信号处理的行为。常见的标志包括:
sa_restorer:- 这个字段已废弃,不应该被使用。
使用示例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
void handler(int signum, siginfo_t *info, void *context) {
printf("Caught signal %d\n", signum);
// 打印更多关于信号的信息
printf("Signal code: %d\n", info->si_code);
}
int main() {
struct sigaction act;
// 初始化结构体
act.sa_sigaction = handler;
act.sa_flags = SA_SIGINFO; // 使用带有额外参数的信号处理函数
// 填充信号掩码,这里我们不限制任何额外的信号
sigemptyset(&act.sa_mask);
// 设置 SIGINT 的信号处理程序
if (sigaction(SIGINT, &act, NULL) == -1) {
perror("sigaction");
exit(EXIT_FAILURE);
}
printf("Waiting for SIGINT (Ctrl+C)...\n");
// 挂起进程,等待信号
while (1) {
pause(); // 等待信号
}
return 0;
}
stat
stat 函数是 Unix 和类 Unix 操作系统(如 Linux)中的一个系统调用,用于获取文件或文件系统对象的相关信息。它通过填充一个 struct stat 结构体来提供文件的元数据,包括文件大小、权限、创建时间等1
2
3
4
5
int stat(const char *pathname, struct stat *statbuf);
- 参数:
pathname:要查询的文件或目录的路径。statbuf:指向一个struct stat结构体的指针,该结构体将被用来存储文件的状态信息。
- 返回值:
- 成功时返回
0。 - 失败时返回
-1并设置errno来指示错误类型。
- 成功时返回
除了 stat,还有其他几个类似的函数可以用于不同的场景:
fstat:与stat类似,但它接受一个文件描述符而不是路径名作为第一个参数。1
int fstat(int fd, struct stat *statbuf);
lstat:与stat类似,但如果目标是一个符号链接(symlink),它会返回符号链接本身的信息,而不是它指向的目标文件的信息。1
int lstat(const char *pathname, struct stat *statbuf);
struct stat 包含了大量的关于文件的信息。以下是一些常用的字段:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15struct stat {
dev_t st_dev; // 文件所在设备的标识符
ino_t st_ino; // inode 编号
mode_t st_mode; // 文件类型和访问权限
nlink_t st_nlink; // 硬链接数量
uid_t st_uid; // 文件所有者的用户 ID
gid_t st_gid; // 文件所有者的组 ID
dev_t st_rdev; // 如果文件是一个设备文件,则为其设备编号
off_t st_size; // 文件大小(字节数)
blksize_t st_blksize; // 文件系统的 I/O 块大小
blkcnt_t st_blocks; // 分配给文件的块数
time_t st_atime; // 最后访问时间
time_t st_mtime; // 最后修改时间
time_t st_ctime; // 最后状态改变时间(在 Unix 中通常为元数据更改时间)
};
在 struct stat 的 st_mode 字段中,文件类型和权限信息被编码在一起。可以通过位操作提取这些信息:
- 文件类型:
S_IFMT:文件类型的掩码。S_IFDIR:目录。S_IFCHR:字符设备。S_IFBLK:块设备。S_IFREG:普通文件。S_IFIFO:命名管道(FIFO)。S_IFLNK:符号链接。S_IFSOCK:套接字。
- 权限:
S_IRUSR,S_IWUSR,S_IXUSR:用户(拥有者)的读、写、执行权限。S_IRGRP,S_IWGRP,S_IXGRP:组的读、写、执行权限。S_IROTH,S_IWOTH,S_IXOTH:其他人的读、写、执行权限。
1 | if ((sb.st_mode & S_IFMT) == S_IFREG && (sb.st_mode & S_IRUSR)) { |
mmap
mmap 是 Unix 和类 Unix 系统(如 Linux)中的一个系统调用,用于将文件或设备的内存映射到进程的地址空间。这种机制允许程序以类似于访问内存的方式访问文件内容,从而简化了文件操作,并且可以提高性能,特别是在处理大文件时。
- 文件映射:将文件的内容映射到进程的虚拟内存中,使得可以通过指针直接访问文件的数据,而不需要通过常规的文件 I/O 操作(如
read和write)。 - 共享内存:允许多个进程共享同一块内存区域,实现高效的进程间通信(IPC)。
- 匿名映射:创建不与任何文件关联的内存映射,适用于需要动态分配大块内存的情况
1 |
|
- 参数:
addr:建议的映射起始地址(通常设为NULL,让系统选择合适的地址)。length:映射区域的大小(字节数)。- prot:指定映射区域的保护标志(如可读、可写、可执行等)。
PROT_READ:映射区域可读。PROT_WRITE:映射区域可写。PROT_EXEC:映射区域可执行。
- flags:控制映射区域的行为。
MAP_SHARED:映射区域会被多个进程共享,修改会反映到文件中。MAP_PRIVATE:创建私有副本,修改不会影响原文件。MAP_ANONYMOUS:映射匿名内存(不与文件关联)。
fd:要映射的文件描述符(对于匿名映射,应设置为-1)。offset:从文件开头开始的偏移量(必须是页面大小的倍数)。
返回值:
- 成功时返回指向映射区域的指针。
- 失败时返回
MAP_FAILED(通常定义为(void *) -1),并设置errno。
munmap:解除内存映射。1
int munmap(void *addr, size_t length);
msync:同步内存映射区域到文件或设备。1
int msync(void *addr, size_t length, int flags);
解析传入参数
Linux中getopt 是一个用于解析命令行选项的标准 C 库函数。它使得程序能够处理以短格式(如 -a, -b value)提供的命令行参数。getopt 函数及其扩展版本 getopt_long 为开发者提供了便捷的方式来解析和处理命令行选项。
get_opt函数
1 |
|
参数:
argc和argv:分别是从main函数传递过来的参数计数和参数数组。optstring:包含程序所支持的选项字符组成的字符串。如果某个选项需要参数,则在该选项字符后加上冒号(:),表示该选项需要一个值。
返回值:
- 成功时,返回下一个选项字符。
- 当所有选项都已处理完毕,返回
-1。 - 如果遇到无效选项或缺少必需的参数,返回
?并设置optopt变量为无效选项字符。
全局变量:
optind:指向下一个要处理的argv元素的索引。optarg:指向当前选项的参数(如果有)。opterr:控制getopt是否打印错误消息,默认为 1(开启)。optopt:存储无效选项字符或缺失参数的选项字符。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
int main(int argc, char *argv[]) {
int opt;
while ((opt = getopt(argc, argv, "ab:c")) != -1) {
switch (opt) {
case 'a':
printf("Option -a\n");
break;
case 'b':
printf("Option -b with value %s\n", optarg);
break;
case 'c':
printf("Option -c\n");
break;
case '?':
if (optopt == 'b') {
fprintf(stderr, "Option -b requires an argument.\n");
} else {
fprintf(stderr, "Unknown option character `\\x%x'.\n", optopt);
}
return 1;
default:
abort();
}
}
// 处理非选项参数
for (int index = optind; index < argc; index++) {
printf("Non-option argument: %s\n", argv[index]);
}
return 0;
}
getopt_long 函数
对于支持长格式选项(如 --option, --option=value)的应用程序,可以使用 getopt_long 函数。
函数原型
1 |
|
参数:
shortopts:与getopt相同,定义短格式选项。longopts指向描述长格式选项的struct option
1
2
3
4
5
6struct option {
const char *name; // 长格式选项名
int has_arg; // 是否需要参数,可能值:no_argument, required_argument, optional_argument
int *flag; // 若不为 NULL,函数将此指针指向的变量设为 val;若为 NULL,函数返回 val
int val; // 返回给 `getopt_long` 的值或设置到 `flag` 指向的变量中
};longindex:如果非NULL,则指向一个变量,该变量接收匹配的长选项在longopts数组中的索引。
返回值:
- 成功时,返回匹配选项的字符(对于短选项)或
val字段的值(对于长选项)。 - 当所有选项都已处理完毕,返回
-1。 - 对于无效选项或缺少必需的参数,返回
?。
- 成功时,返回匹配选项的字符(对于短选项)或
getopt:适用于处理短格式选项的简单场景。通过指定一个选项字符串来定义允许的选项及是否需要参数。getopt_long:扩展了getopt,支持长格式选项,并允许更灵活地配置每个选项的行为(是否需要参数、如何处理等)。
分散/聚集IO
分散/聚集 I/O(Scatter/Gather I/O)是一种允许在单次系统调用中处理多个数据缓冲区的技术。它特别适用于需要处理多个不连续的数据块的应用场景,如网络通信、数据库操作等。通过分散/聚集 I/O,可以减少系统调用的次数,提高性能和效率。
分散 I/O(Scatter I/O)
分散读取(Scatter Read)指的是从一个输入源(例如文件或套接字)读取数据,并将这些数据分散到多个缓冲区中。这种技术通常用于接收长度未知的数据流,并将其分割成多个部分存储在不同的缓冲区中。
聚集 I/O(Gather I/O)
聚集写入(Gather Write)则是指将多个缓冲区中的数据收集起来,然后一次性写入到输出目标(例如文件或套接字)。这种方法可以简化编程模型,并且通过减少系统调用的数量来提高性能。
在 Unix 和类 Unix 系统(如 Linux)中,分散/聚集 I/O 主要通过 readv 和 writev 系统调用来实现。
readv 和 writev 函数
readv:从文件描述符读取数据并分散到多个缓冲区。writev:从多个缓冲区收集数据并写入到文件描述符。
1 | struct iovec { |
1 |
|
TCP流程
TCP Server1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
int main() {
int server_fd, new_socket;
struct sockaddr_in address;
int addrlen = sizeof(address);
char buffer[BUFFER_SIZE] = {0};
const char *response = "Hello from server";
// 创建套接字
if ((server_fd = socket(AF_INET, SOCK_STREAM, 0)) == 0) {
perror("Socket creation failed");
exit(EXIT_FAILURE);
}
// 绑定地址和端口
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(PORT);
if (bind(server_fd, (struct sockaddr *)&address, sizeof(address)) < 0) {
perror("Bind failed");
close(server_fd);
exit(EXIT_FAILURE);
}
// 监听连接
if (listen(server_fd, 3) < 0) {
perror("Listen failed");
close(server_fd);
exit(EXIT_FAILURE);
}
printf("Server is listening on port %d...\n", PORT);
// 接受客户端连接
if ((new_socket = accept(server_fd, (struct sockaddr *)&address, (socklen_t *)&addrlen)) < 0) {
perror("Accept failed");
close(server_fd);
exit(EXIT_FAILURE);
}
// 读取客户端数据
int valread = read(new_socket, buffer, BUFFER_SIZE);
printf("Client: %s\n", buffer);
// 发送响应
send(new_socket, response, strlen(response), 0);
printf("Response sent to client.\n");
close(new_socket);
close(server_fd);
return 0;
}
TCP Client1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
int main() {
int sock = 0;
struct sockaddr_in serv_addr;
char buffer[BUFFER_SIZE] = {0};
const char *message = "Hello from client";
// 创建套接字
if ((sock = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
perror("Socket creation failed");
exit(EXIT_FAILURE);
}
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(PORT);
// 将 IP 地址转换为二进制形式
if (inet_pton(AF_INET, "127.0.0.1", &serv_addr.sin_addr) <= 0) {
perror("Invalid address/ Address not supported");
close(sock);
exit(EXIT_FAILURE);
}
// 连接到服务器
if (connect(sock, (struct sockaddr *)&serv_addr, sizeof(serv_addr)) < 0) {
perror("Connection failed");
close(sock);
exit(EXIT_FAILURE);
}
// 发送消息
send(sock, message, strlen(message), 0);
printf("Message sent to server.\n");
// 接收响应
int valread = read(sock, buffer, BUFFER_SIZE);
printf("Server: %s\n", buffer);
close(sock);
return 0;
}
int main() {
int sock = 0;
struct sockaddr_in serv_addr;
char buffer[BUFFER_SIZE] = {0};
const char *message = "Hello from client";
// 创建套接字
if ((sock = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
perror("Socket creation failed");
exit(EXIT_FAILURE);
}
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(PORT);
// 将 IP 地址转换为二进制形式
if (inet_pton(AF_INET, "127.0.0.1", &serv_addr.sin_addr) <= 0) {
perror("Invalid address/ Address not supported");
close(sock);
exit(EXIT_FAILURE);
}
// 连接到服务器
if (connect(sock, (struct sockaddr *)&serv_addr, sizeof(serv_addr)) < 0) {
perror("Connection failed");
close(sock);
exit(EXIT_FAILURE);
}
// 发送消息
send(sock, message, strlen(message), 0);
printf("Message sent to server.\n");
// 接收响应
int valread = read(sock, buffer, BUFFER_SIZE);
printf("Server: %s\n", buffer);
close(sock);
return 0;
}
UDP流程
UDP Server1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
const int PORT = 8080;
const int BUFFER_SIZE = 1024;
int main() {
int sockfd;
char buffer[BUFFER_SIZE];
sockaddr_in servaddr, cliaddr;
socklen_t len = sizeof(cliaddr);
const char *response = "Hello from server";
// 创建套接字 SOCK_DGRAM
if ((sockfd = socket(AF_INET, SOCK_DGRAM, 0)) < 0) {
perror("Socket creation failed");
exit(EXIT_FAILURE);
}
memset(&servaddr, 0, sizeof(servaddr));
memset(&cliaddr, 0, sizeof(cliaddr));
// 绑定地址和端口
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = INADDR_ANY;
servaddr.sin_port = htons(PORT);
if (bind(sockfd, (const struct sockaddr *)&servaddr, sizeof(servaddr)) < 0) {
perror("Bind failed");
close(sockfd);
exit(EXIT_FAILURE);
}
printf("Server is listening on port %d...\n", PORT);
// 服务端绑定套接字后 直接开始读了
// 接收客户端数据
int n = recvfrom(sockfd, (char *)buffer, BUFFER_SIZE, 0,
(struct sockaddr *)&cliaddr, &len);
buffer[n] = '\0';
printf("Client: %s\n", buffer);
// 发送响应
sendto(sockfd, (const char *)response, strlen(response), 0,
(const struct sockaddr *)&cliaddr, len);
printf("Response sent to client.\n");
close(sockfd);
return 0;
}
UDP Client1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
int main() {
int sockfd;
char buffer[BUFFER_SIZE];
struct sockaddr_in servaddr;
const char *message = "Hello from client";
// 创建套接字
if ((sockfd = socket(AF_INET, SOCK_DGRAM, 0)) < 0) {
perror("Socket creation failed");
exit(EXIT_FAILURE);
}
memset(&servaddr, 0, sizeof(servaddr));
// 设置服务器地址
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(PORT);
servaddr.sin_addr.s_addr = INADDR_ANY;
// 将 IP 地址转换为二进制形式
if (inet_pton(AF_INET, "127.0.0.1", &servaddr.sin_addr) <= 0) {
perror("Invalid address/ Address not supported");
close(sockfd);
exit(EXIT_FAILURE);
}
// 创建套接字 后直接发送消息 需要连接的地址,不需要connect
// 发送消息
sendto(sockfd, (const char *)message, strlen(message), 0,
(const struct sockaddr *)&servaddr, sizeof(servaddr));
printf("Message sent to server.\n");
// 接收响应
socklen_t len = sizeof(servaddr);
int n = recvfrom(sockfd, (char *)buffer, BUFFER_SIZE, 0,
(struct sockaddr *)&servaddr, &len);
buffer[n] = '\0';
printf("Server: %s\n", buffer);
close(sockfd);
return 0;
}
异步IO机制
[译] Linux 异步 I/O 框架 io_uring:基本原理、程序示例与性能压测(2020)
Linux 网络编程的5种IO模型:异步IO模型 - schips - 博客园
POSIX异步IO
POSIX异步I/O提供了一种机制,允许应用程序在执行I/O操作时不会被阻塞,这意味着程序可以在I/O操作完成的同时继续执行其他任务。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25/* Asynchronous I/O control block. */
struct aiocb
{
int aio_fildes; /* File descriptor. */
int aio_lio_opcode; /* Operation to be performed. */
int aio_reqprio; /* Request priority offset. */
volatile void *aio_buf; /* Location of buffer. */
size_t aio_nbytes; /* Length of transfer. */
struct sigevent aio_sigevent; /* Signal number and value. */
/* Internal members. */
struct aiocb *__next_prio;
int __abs_prio;
int __policy;
int __error_code;
__ssize_t __return_value;
#ifndef __USE_FILE_OFFSET64
__off_t aio_offset; /* File offset. */
char __pad[sizeof (__off64_t) - sizeof (__off_t)];
#else
__off64_t aio_offset; /* File offset. */
#endif
char __glibc_reserved[32];
};
struct aiocb:这是异步I/O控制块,包含了关于异步I/O操作的所有信息。包括但不限于文件描述符、缓冲区地址、请求的状态等。通知方式有不通知,信号通知,在新线程中调用指定函数等
1 | typedef struct sigevent |
sigev_notify:指定通知的方式。常见的选项包括:SIGEV_NONE:不发送任何通知。SIGEV_SIGNAL:当异步事件发生时,向进程发送指定的信号。SIGEV_THREAD:当异步事件发生时,在新线程中调用指定的函数。SIGEV_THREAD_ID:特定于Linux的一个扩展,允许向特定线程发送信号。
1
2
3
4
5
6
7
8
9
10
11
12
13
14enum
{
SIGEV_SIGNAL = 0, /* Notify via signal. */
SIGEV_NONE, /* Other notification: meaningless. */
SIGEV_THREAD, /* Deliver via thread creation. */
SIGEV_THREAD_ID = 4 /* Send signal to specific thread.
This is a Linux extension. */
};sigev_signo:如果选择了SIGEV_SIGNAL作为通知方式,则此字段应设置为希望发送的信号编号(例如SIGIO)。sigev_value:这是一个联合体,可用于将数据传递给信号处理器或回调函数。这可以是任意数据,通常用于标识哪个异步I/O操作触发了通知。sigev_notify_function:当选择SIGEV_THREAD作为通知方式时,此字段应指向一个函数,该函数将在新线程中被调用来处理事件。sigev_notify_attributes:如果选择了SIGEV_THREAD作为通知方式,可以通过此字段提供线程属性对象,以定制创建的新线程的特性。
aio_read()- 发起一个异步读操作。它接受一个指向
aiocb结构的指针作为参数,并返回一个整数值。如果成功,则返回0;如果失败,则返回-1,并设置相应的错误码。
- 发起一个异步读操作。它接受一个指向
aio_write()- 发起一个异步写操作。与
aio_read()类似,它也接受一个指向aiocb结构的指针,并根据是否成功返回0或-1。
- 发起一个异步写操作。与
aio_error()- 检查指定的异步I/O操作的状态。如果操作还在进行中,它将返回
EINPROGRESS;如果操作已经完成,但发生了错误,它会返回相应的错误码;如果操作成功完成,它会返回0。
- 检查指定的异步I/O操作的状态。如果操作还在进行中,它将返回
aio_return()- 获取已完成的异步I/O操作的返回状态。只有当
aio_error()对特定的aiocb结构返回除了EINPROGRESS之外的值时,调用aio_return()才有意义。
- 获取已完成的异步I/O操作的返回状态。只有当
aio_cancel()- 尝试取消一个或多个尚未完成的异步I/O请求。可以针对特定的
aiocb取消,也可以尝试取消某个文件描述符上的所有异步I/O请求。
- 尝试取消一个或多个尚未完成的异步I/O请求。可以针对特定的
aio_suspend()- 挂起调用进程或线程,直到指定的一个或多个异步I/O请求完成或者发生超时(如果提供了超时参数)。这对于等待一组异步I/O操作完成特别有用。
lio_listio()- 同时发起一系列的读写操作。这可以是一个列表的读操作、写操作或是两者的组合。此函数支持两种模式:同步和异步。在异步模式下,即使I/O操作未完成,该函数也会立即返回。
1 |
|
1 |
|
上述aio其实是用户层使用线程模拟的异步io,缺点是占用线程资源而且受可用线程的数量限制。Linux2.6版本后有了libaio,这完全是内核级别的异步IO,IO请求完全由底层自由调度
Linux原生AIO
Linux Native AIO 是 Linux 支持的原生 AIO,为什么要加原生这个词呢?因为Linux存在很多第三方的异步 IO 库,如 libeio 和 glibc AIO。所以为了加以区别,Linux 的内核提供的异步 IO 就称为原生异步 IO。很多第三方的异步 IO 库都不是真正的异步 IO,而是使用多线程来模拟异步 IO,如 libeio 就是使用多线程来模拟异步 IO 的。
一般来说,使用 Linux 原生 AIO 需要 3 个步骤:
- 1) 调用 io_setup 函数创建一个一般 IO 上下文。
- 2) 调用 io_submit 函数向内核提交一个异步 IO 操作。
- 3) 调用 io_getevents 函数获取异步 IO 操作结果。
可以通过libaio库调用原生系统调用
io_setup()- 初始化一个AIO上下文,返回一个上下文标识符供后续操作使用。
io_submit()- 提交一个或多个异步I/O请求到指定的AIO上下文中。
io_getevents()- 获取已完成的异步I/O操作的结果。可以通过此函数查询已提交的I/O请求的状态。
io_destroy()- 销毁一个AIO上下文,释放相关资源。
struct iocb- 这个结构用于描述单个I/O操作的信息,包括操作类型(读、写等)、文件描述符、缓冲区地址及大小等。
1 | struct iocb { |
data:用户可以设置一个指针,用于在回调或完成事件中标识这个请求。aio_lio_opcode:指定操作类型,例如读取 (IO_CMD_PREAD) 或写入 (IO_CMD_PWRITE)。aio_fildes:目标文件的文件描述符。u.c:包含具体操作的参数(如缓冲区地址、偏移量、字节数等)。
1 | struct io_event { |
data和obj:用于匹配完成事件和原始请求。res:表示操作的结果。如果大于等于 0,则表示成功完成的字节数;如果小于 0,则表示发生错误,其值为负的错误码(如-EIO)。res2:通常不使用,但在某些情况下可能包含额外的信息。
`io_context_t
作用:表示一个异步 I/O 上下文,用于管理一组异步 I/O 请求。
定义
1
typedef struct io_context *io_context_t;
说明
- 一个
io_context_t可以管理多个异步 I/O 请求。
- 一个
注意添加链接库1
sudo apt install libaio-dev
1
2
3
4target_link_libraries(linux_aio
PRIVATE
-laio
)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
int main() {
io_context_t ctx;
struct iocb cb;
struct iocb *cbs[1];
int fd;
char buf[] = "Hello,world";
fd = open("test1.txt", O_RDWR | O_CREAT | O_DIRECT, 0644);
if (fd < 0) {
perror("open:");
return -1;
}
memset(&ctx, 0, sizeof(io_context_t));
// io事件的初始化
if (io_setup(1, &ctx) < 0) {
perror("io_setup:");
return -1;
}
// 提交io事件
memset(&cb, 0, sizeof(struct iocb));
cb.aio_fildes = fd;
cb.aio_lio_opcode = IO_CMD_PWRITE;
char msg[] = "aio query";
cb.data = msg;
cb.u.c.buf = buf;
cb.u.c.nbytes = strlen(buf);
cb.u.c.offset = 0;
cbs[0] = &cb;
if (io_submit(ctx, 1, cbs) < 0) {
perror("io_submit:");
return -1;
}
struct io_event events[1];
if (io_getevents(ctx, 1, 1, events, nullptr) < 0) {
perror("io_getevents:");
return -1;
}
if (events[0].res < 0) {
perror("io_getevents:");
return -1;
}
std::cout << "aio getevents:" << (char *)events[0].data << std::endl;
std::cout << "aio getevents:" << events[0].res << std::endl;
std::cout << "aio getevents:" << events[0].res2 << std::endl;
io_destroy(ctx);
close(fd);
return 0;
}
注意,如果使用O_DIRECT标志打开有限制.O_DIRECT 是一种特殊的文件打开模式,它绕过操作系统的页缓存,直接与磁盘设备交互。
(1) 缓冲区对齐
- 地址对齐:缓冲区的起始地址必须是对齐的,通常是硬件块大小的倍数(通常是 512 字节或 4KB)。
- 大小对齐:缓冲区的大小也必须是硬件块大小的倍数。
- 偏移量对齐:文件读写的偏移量也必须是对齐的。
如果不满足这些对齐要求,open() 或 read()/write() 调用可能会失败。
(2) 文件系统支持
- 并非所有文件系统都支持
O_DIRECT。例如,某些网络文件系统(如 NFS)可能不支持直接 I/O。
(3) 性能权衡
- 直接 I/O 绕过了页缓存,因此对于小文件或频繁的小 I/O 操作,性能可能不如普通缓存 I/O。
关键修改点
(1) 使用 posix_memalign() 分配对齐内存
posix_memalign()1
2
3
4if (posix_memalig(&buffer, 4096, BUFFER_SIZE)) {
perror("posix_memalign");
return 1;
}
- 第二个参数指定对齐边界(这里是 4KB)。
- 第三个参数指定分配的大小。
posix_memalign是一个 POSIX 标准的函数,用于分配对齐的内存。它允许用户指定内存块的起始地址对齐边界.
参数说明
memptr
- 输出参数,指向一个指针变量。
- 如果分配成功,
*memptr将存储分配的内存块的地址。alignment
- 内存块的对齐边界,以字节为单位。
- 必须是 2 的幂次方,并且至少为
sizeof(void *)(通常是 8 字节或更大)。size
- 要分配的内存大小,以字节为单位。
(2) 添加 O_DIRECT 标志
在open()中添加
O_DIRECT1
int fd = open("output.txt", O_WRONLY | O_CREAT | O_TRUNC | O_DIRECT, 0644);
(3) 确保缓冲区大小和偏移量对齐
- 缓冲区大小设置为 4KB(
BUFFER_SIZE)。 - 文件偏移量设置为 0(默认对齐)
Why does O_DIRECT require I/O to be 512-byte aligned? - Quora
要求缓存大小和对齐都需要512及其倍数字节.
libaio的缺点是,(1)想要使用该种方式的文件必须支持以O_DIRECT标志打开,然而并不是所有的文件系统都支持。如果你没有使用O_DIRECT打开文件,它可能仍然“工作”,但它可能不是异步完成的,而是变为了阻塞的。
(2)仍然可能被阻塞。即使应用层主观上,希望系统层采用异步 IO,但是客观上,有时候还是可能会被阻塞。
(3) 拷贝开销大。每个 IO 提交需要拷贝 64+8 字节,每个 IO 完成需要拷贝 32 字节,总共 104 字节的拷贝。这个拷贝开销是否可以承受,和单次 IO 大小有关:如果需要发送的 IO 本身就很大,相较之下,这点消耗可以忽略,而在大量小 IO 的场景下,这样的拷贝影响比较大。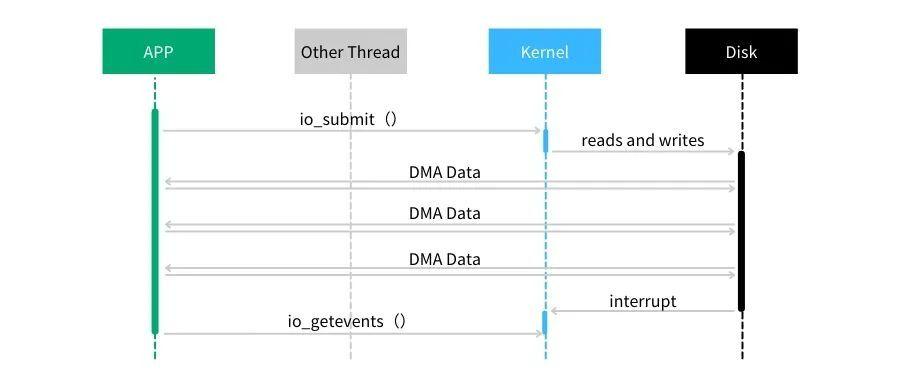
io_uring
io_uring 是 Linux 内核5.1版本引入的一种高性能异步I/O框架。与传统的 POSIX AIO 相比,io_uring 提供了更高效的零拷贝I/O操作,减少了上下文切换和系统调用开销。
io_uring 围绕高效进行设计,其设计了一对共享的 ring buffer 用于应用和内核之间的通信,通过该设计实现了如下的三个好处:
(1)避免在提交和完成事件中存在内存拷贝;
(2)避免了 libaio 中在提交和完成任务的时候系统调用过程;
(3)该队列采用了无锁的访问模式,通过内存屏障减少了竞争;
在共享的 ring buffer 设计中,针对提交队列(SQ),应用是 IO 提交的生产者(producer),内核是消费者(consumer);反过来,针对完成队列(CQ),内核是完成事件的生产者,应用是消费者。
另外,io_uring 还存在如下的优势:
(1)提交和完成不需要经过系统调用,而且减少了对用户态线程的阻塞;该部分的支持主要通过共享的 ring buffer 和设置 polling 模式来实现。
(2)支持 Block 层的 polling 模式
(3)支持 buffered IO,充分利用缓存,减少数据碰盘产生的系统延迟;
1 | sudo apt install liburing-dev |
1 | target_link_libraries(io_uring |
liburing 是一个基于 io_uring 接口的用户空间库,它是 Linux 内核开发者 Axboe 于 2019 年发布的一个开源项目。io_uring 是一种新的 Linux 异步 I/O 接口,它通过使用一对环形缓冲区(ring buffer)来实现用户空间和内核空间之间的通信,从而避免了传统异步 I/O 接口(如 AIO)所需的系统调用、信号、回调等机制。这样,用户空间可以直接向内核提交 I/O 请求,并从内核获取 I/O 结果,而无需等待或切换上下文。这大大提高了异步 I/O 操作的效率和性能。
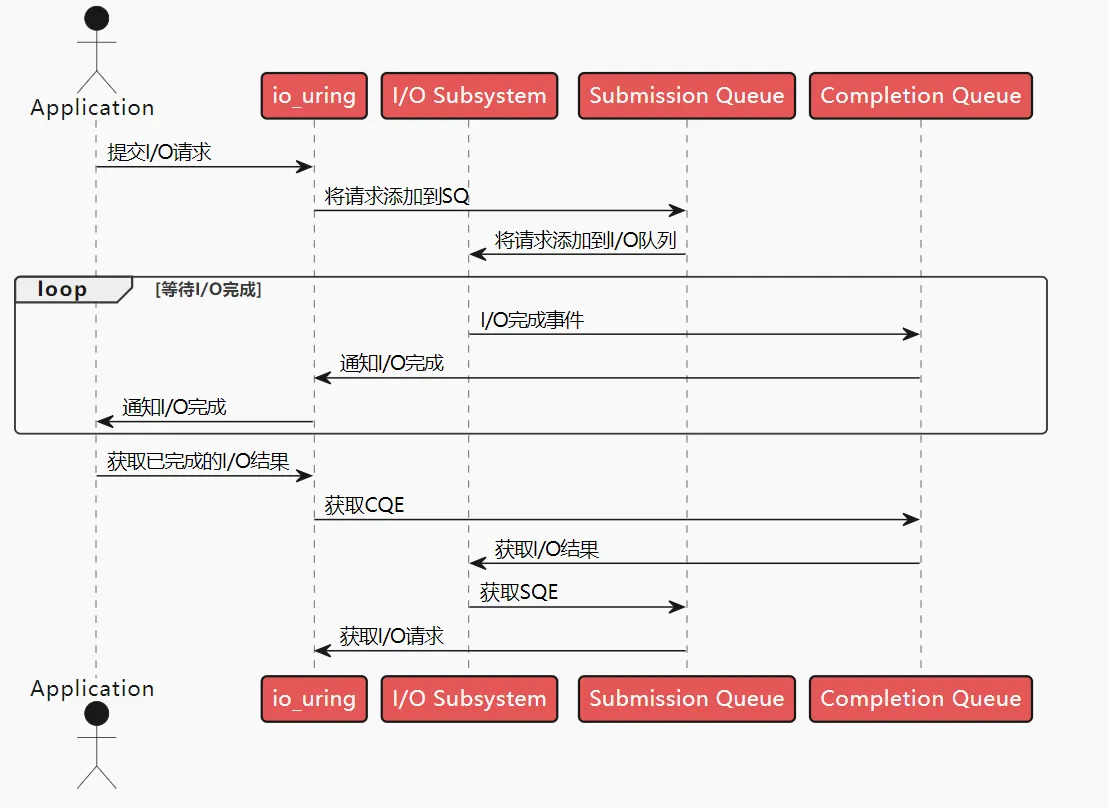
每个 io_uring 实例都有两个环形队列(称为 ring),在内核和应用程序之间共享:
- 提交队列:submission queue( SQ )
- 完成队列:completion queue( CQ )
这两个队列:
- 都是单生产者、单消费者的队列,size 为 2 的幂次方。
- 提供无锁接口,内部使用内存屏障来进行同步。
请求时:
- 应用创建 SQ Entries (SQE),更新 SQ tail
- 内核消费 SQE,更新 SQ head
完成后:
- 内核为完成的一个或多个请求创建 CQ Entries (CQE),更新 CQ tail
- 应用消费 CQE,更新 CQ head
- 完成事件可能以任意顺序到达,到总是与特定的 SQE 相关联的
- 消费 CQE 过程无需切换内核态
这样做的好处在于:
- 原本需要多次系统调用,现在变成批处理一次提交
- 此外,io_uring 使异步 I/O 的使用场景也不再仅限于数据库应用, 普通的非数据库应用也能用
io_uring 的三种工作模式:
- 中断驱动模式 (interrupt-driven)
- 默认模式, 可通过 io_uring_enter()提交 I/O 请求,然后直接检查 CQ 状态判断是否完成。
- 轮询模式 (polling)
- Busy waiting for I/O completion,而不是通过异步 IRQ(Interrupt Request)来接收通知
- 这种模式需要文件系统和块设备支持轮询功能。相比中断驱动模式,这种方式延迟更低,但是 CPU 占用率可能会更高。
- 目前,只有指定了 O_DIRECT 标志打开的文件描述符才能使用这种模式。当一个读或写请求提交给轮询上下文之后,应用必须调用 io_uring_enter()来轮询 CQ 队列,判断请求是否完成。
- 对于一个 io_uring 实例来说,不支持混合使用轮询和非轮询模式。
- 内核轮询模式 (kernel polling)
- 这种模式会创建一个内核线程来执行 SQ 的轮询工作。
- 使用这种模式的 io_uring 实例,应用无需切到内核态就能触发 I/O 操作。通过 SQ 来提交 SQE,以及监控 CQ 的完成状态,应用无需任何系统调用,就能提交和收割 I/O。
- 如果内核线程的空闲事件超过了用户的配置值,它会通知应用,然后进入 idle 状态。这种情况下,应用必须调用 io_uring_enter()来唤醒内核线程。如果 I/O 一直很繁忙,内核线程是不会 sleep 的。
(1)io_uring_setup:初始化一个新的 io_uring 上下文,内核通过一块和用户共享的内存区域进行消息的传递。
(2)io_uring_enter:提交任务以及收割任务。
(3)io_uring_register:注册用户态和内核态的共享 buffer。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
int main() {
constexpr int BUFFER_SIZE = 4096;
// 初始化io_uring实例
struct io_uring ring;
char buffer[BUFFER_SIZE];
int fd;
if (io_uring_queue_init(8, &ring, 0) < 0) {
perror("io_uring_queue_init");
return 1;
}
fd = open("output.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
if (fd < 0) {
perror("open");
io_uring_queue_exit(&ring);
return 1;
}
memset(buffer, 'A', BUFFER_SIZE); // 填充缓冲区为字符 'A'
struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);
if (!sqe) {
perror("io_uring_get_sqe");
close(fd);
io_uring_queue_exit(&ring);
return 1;
}
// 准备写入请求
io_uring_prep_write(sqe, fd, buffer, BUFFER_SIZE, 0);
sqe->user_data = 1; // 设置用户数据
// 提交请求
if (io_uring_submit(&ring) < 0) {
perror("io_uring_submit");
close(fd);
io_uring_queue_exit(&ring);
return 1;
}
printf("Asynchronous write operation initiated.\n");
struct io_uring_cqe *cqe;
if (io_uring_wait_cqe(&ring, &cqe) < 0) {
perror("io_uring_wait_cqe");
close(fd);
io_uring_queue_exit(&ring);
return 1;
}
if (cqe->res < 0) {
fprintf(stderr, "Error: %s\n", strerror(-cqe->res));
} else {
printf("Write completed successfully.\n");
}
io_uring_cqe_seen(&ring, cqe); // 标记完成事件为已处理
close(fd);
io_uring_queue_exit(&ring); // 清理io_uring实例
return 0;
}
每一个io_uring实例,都会被分配一个fd,该过程是通过io_uring_setup()系统调用实现的。
io_uring_setup()调用会根据用户提供的参数,分配一块共享内存。
这块共享内存中,包含了一个SQ(提交队列)、一个CQ(完成队列)和一个SQE(提交实体)数组。
其中,SQ和CQ是两个环形队列,队列中的元素是SQE在SQE数组中的偏移量,使用这种方式可以使得提交实体能够被随机访问,提高灵活性。
io_uring_setup()调用返回的fd,该内存可以通过mmap()的方式映射到用户态
用户从CQ的头部获取SEQ,将想要执行的操作(如文件的读写)初始化到其中,并添加到SQ队列的尾部,然后使用io_uring_enter()系统调用来进行提交队列的处理。
用户态和内核态共享 提交队列(submission queue)和 完成队列(completion queue),这两条队列通过mmap共享,高效且安全。
提交队列(SQ)给内核源源不断的布置任务,然后从另外一条队列完成队列(CQ)获取结果;
内核则按需进行 epoll(),并在一个线程池中执行就绪的任务。
用户态支持Polling模式,不会发生中断,也就没有系统调用,通过轮询即可消费事件;
内核态也支持Polling模式,同样不会发生上下文切换。
可以看出关键的设计在于,内核通过一块和用户共享的内存区域进行消息的传递,可以绕过Linux 的 syscall 机制。
内核会从SQ中依次取出对应的io request 提交实体,并根据io request 提交实体中定义的动作来执行对应的操作。由于用户只操作SQ尾部,而内核只操作头部,因此两者对于共享队列的访问并不会产生冲突,节省了锁的开销。1
2
3
4
5
6
7
8
9struct io_uring {
struct io_uring_sq sq;
struct io_uring_cq cq;
unsigned flags;
int ring_fd; // id
unsigned features;
unsigned pad[3];
}; // io_uring结构1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18struct io_uring_sq { // 提交队列
unsigned *khead;
unsigned *ktail;
unsigned *kring_mask;
unsigned *kring_entries;
unsigned *kflags;
unsigned *kdropped;
unsigned *array;
struct io_uring_sqe *sqes;
unsigned sqe_head;
unsigned sqe_tail;
size_t ring_sz;
void *ring_ptr;
unsigned pad[4];
};1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48struct io_uring_sqe { // 提交队列entry
__u8 opcode; /* type of operation for this sqe */
__u8 flags; /* IOSQE_ flags */
__u16 ioprio; /* ioprio for the request */
__s32 fd; /* file descriptor to do IO on */
union {
__u64 off; /* offset into file */
__u64 addr2;
};
union {
__u64 addr; /* pointer to buffer or iovecs */
__u64 splice_off_in;
};
__u32 len; /* buffer size or number of iovecs */
union {
__kernel_rwf_t rw_flags;
__u32 fsync_flags;
__u16 poll_events; /* compatibility */
__u32 poll32_events; /* word-reversed for BE */
__u32 sync_range_flags;
__u32 msg_flags;
__u32 timeout_flags;
__u32 accept_flags;
__u32 cancel_flags;
__u32 open_flags;
__u32 statx_flags;
__u32 fadvise_advice;
__u32 splice_flags;
__u32 rename_flags;
__u32 unlink_flags;
__u32 hardlink_flags;
};
__u64 user_data; /* data to be passed back at completion time */
/* pack this to avoid bogus arm OABI complaints */
union {
/* index into fixed buffers, if used */
__u16 buf_index;
/* for grouped buffer selection */
__u16 buf_group;
} __attribute__((packed));
/* personality to use, if used */
__u16 personality;
union {
__s32 splice_fd_in;
__u32 file_index;
};
__u64 __pad2[2];
};
Epoll事件的Channel类
1 | typedef union epoll_data |
epoll时间和数据如上,events为要监听的事件,比如EPOLLIN,EPOLLLT等.
绪状态。enum EPOLL_EVENTS 定义了一系列的标志位,用于指定感兴趣的事件类型或报告发生的事件。下面是一些常用的 EPOLL_EVENTS 常量及其用途:
EPOLLIN (0x001):表示对应的文件描述符可以读取(即有数据可读)。EPOLLOUT (0x004):表示对应的文件描述符可以写入(即准备好接受数据写入)。EPOLLPRI (0x002):表示对应文件描述符有紧急数据可读(带外数据)。这在处理 TCP 紧急指针时有用。EPOLLERR (0x008):表示对应的文件描述符发生了错误。这个事件总是会被监控,无需显式地将其加入到感兴趣的事件集合中。EPOLLHUP (0x010):表示对应的文件描述符被挂起(即连接被关闭)。与EPOLLERR类似,此事件也会自动被监控。EPOLLRDHUP (0x2000):自 Linux 2.6.17 起可用,表示对端关闭了连接或者关闭了写入一半的连接。这对于检测对等方关闭连接特别有用。
此外,还有一些不太常用但同样重要的事件:
EPOLLET (1u << 31):设置边缘触发模式。默认情况下,epoll使用水平触发模式;当启用边缘触发模式后,只有在文件描述符的状态发生变化时才会触发事件通知,而不是每次轮询都可能返回就绪状态。EPOLLONESHOT (1u << 30):一旦被指定的文件描述符上的事件发生并被处理后,相应的文件描述符将不再处于监听状态。要再次监听该文件描述符上的事件,需要重新添加到epoll实例中。EPOLLEXCLUSIVE (1u << 28):从 Linux 内核 4.5 开始支持,允许多个epoll实例独立地监听同一个文件描述符。这样可以避免多个进程同时收到相同的事件通知,从而减少竞争条件。
1 | enum EPOLL_EVENTS |
既然可以传一个void*指针,那么可以设计一个Channel类,这个类可以包含监听的fd以及对应的事件等信息. 同时可以设计回调方法,对于server_fd,回调方法可以为接收客户端fd,客户端channel回调方法为读取数据.1
2
3
4
5
6
7
8class Channel{
private:
Epoll *ep;
int fd;
uint32_t events;
uint32_t revents;
bool inEpoll;
};
显然每个文件描述符会被分发到一个
Epoll类,用一个ep指针来指向。类中还有这个Channel负责的文件描述符。另外是两个事件变量,events表示希望监听这个文件描述符的哪些事件,因为不同事件的处理方式不一样。revents表示在epoll返回该Channel时文件描述符正在发生的事件。inEpoll表示当前Channel是否已经在epoll红黑树中,为了注册Channel的时候方便区分使用EPOLL_CTL_ADD还是EPOLL_CTL_MOD。
服务器与事件驱动核心类
30dayMakeCppServer/day06-服务器与事件驱动核心类登场.md at main · yuesong-feng/30dayMakeCppServer
目前从新建socket、接受客户端连接到处理客户端事件,整个程序结构是顺序化、流程化的,我们甚至可以使用一个单一的流程图来表示整个程序。而流程化程序设计的缺点之一是不够抽象,当我们的服务器结构越来越庞大、功能越来越复杂、模块越来越多,这种顺序程序设计的思想显然是不能满足需求的。
对于服务器开发,我们需要用到更抽象的设计模式。从代码中我们可以看到,不管是接受客户端连接还是处理客户端事件,都是围绕epoll来编程,可以说epoll是整个程序的核心,服务器做的事情就是监听epoll上的事件,然后对不同事件类型进行不同的处理。这种以事件为核心的模式又叫事件驱动,事实上几乎所有的现代服务器都是事件驱动的。和传统的请求驱动模型有很大不同,事件的捕获、通信、处理和持久保留是解决方案的核心结构。libevent就是一个著名的C语言事件驱动库。
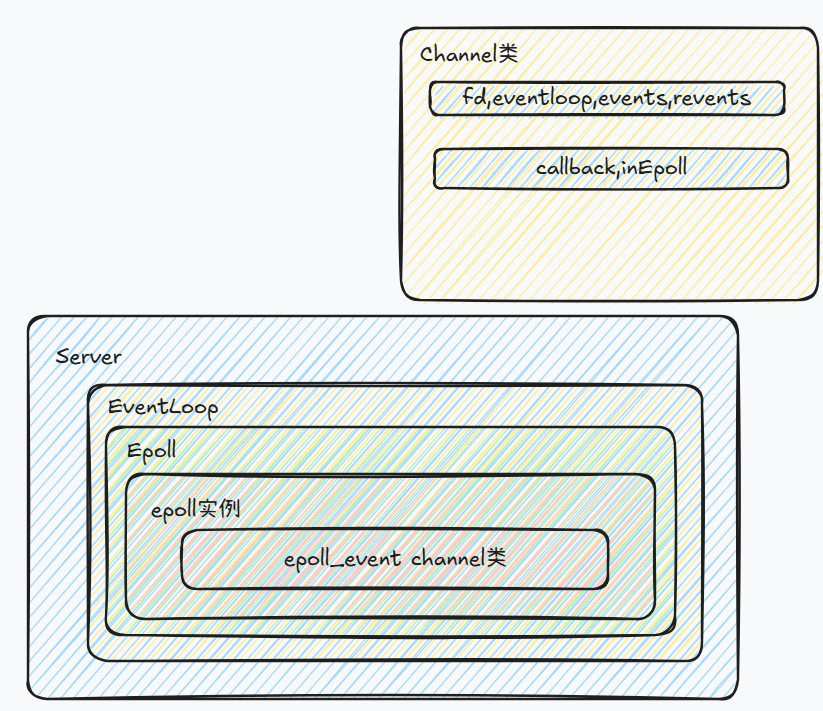
Acceptor类
当server socket监听到事件时,需要做的就是通过accept函数创建新连接,这需要server的socket.
对于每一个事件,不管提供什么样的服务,首先需要做的事都是调用
accept()函数接受这个TCP连接,然后将socket文件描述符添加到epoll。当这个IO口有事件发生的时候,再对此TCP连接提供相应的服务。
Acceptor可以设置回调函数.在Server中设置Acceptor回调函数为接收客户端连接并将fd加入epoll中,并设置相关回调函数.
Acceptor设置回调函数就是为channel设置回调
Acceptor类最主要的三个特点:
- 类存在于事件驱动
EventLoop类中,也就是Reactor模式的main-Reactor - 类中的socket fd就是服务器监听的socket fd,每一个Acceptor对应一个socket fd
- 这个类也通过一个独有的
Channel负责分发到epoll,该Channel的事件处理函数handleEvent()会调用Acceptor中的接受连接函数来新建一个TCP连接
Connection连接类
对于TCP协议,三次握手新建连接后,这个连接将会一直存在,直到我们四次挥手断开连接。因此,我们也可以把TCP连接抽象成一个Connection类,这个类也有以下几个特点:
- 类存在于事件驱动
EventLoop类中,也就是Reactor模式的main-Reactor - 类中的socket fd就是客户端的socket fd,每一个Connection对应一个socket fd
- 每一个类的实例通过一个独有的
Channel负责分发到epoll,该Channel的事件处理函数handleEvent()会调用Connection中的事件处理函数来响应客户端请求
可以看到,Connection类和Acceptor类是平行关系、十分相似,他们都直接由Server管理,由一个Channel分发到epoll,通过回调函数处理相应事件。唯一的不同在于,Acceptor类的处理事件函数(也就是新建连接功能)被放到了Server类中,而Connection类则没有必要这么做,处理事件的逻辑应该由Connection类本身来完成。
Buffer类
之前的读数据部分,都是读取之后立即写入.但是在ET模式下,当errno=EAGAIN才表示没有数据可读取,这时将之间读取的数据进行写入.
可以封装一个buffer类,每次读取数据1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Buffer {
private:
std::string buffer;
public:
const char *data() { return buffer.c_str(); }
size_t size() { return buffer.size(); }
void append(const char *data, size_t size) { buffer.append(data, size); }
void append(const std::string &buf, size_t size) { buffer.append(buf); }
void clear() { buffer.clear(); }
void resize(size_t size) { buffer.resize(size); }
};
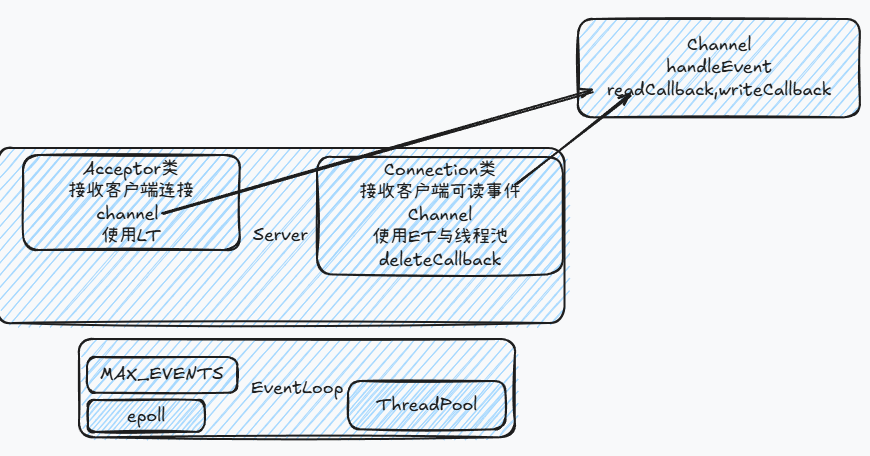
增加线程池
观察当前的服务器架构,不难发现我们的Reactor模型少了最关键、最重要的一个模块:线程池。当发现socket fd有事件时,我们应该分发给一个工作线程,由这个工作线程处理fd上面的事件。而当前我们的代码是单线程模式,所有fd上的事件都由主线程(也就是EventLoop线程)处理,这是大错特错的,试想如果每一个事件相应需要1秒时间,那么当1000个事件同时到来,EventLoop线程将会至少花费1000秒来传输数据,还有函数调用等其他开销,服务器将直接宕机。
线程池需要一个任务队列,工作线程,以及线程同步机制.
任务队列是一个生产者-消费者队列,通过mutex,condition_variable进行线程同步与通信. 工作线程不断地从队列中取出任务并执行.
这个线程池只是为了满足我们的需要构建出的最简单的线程池,存在很多问题。比如,由于任务队列的添加、取出都存在拷贝操作,线程池不会有太好的性能,只能用来学习,正确做法是使用右值移动、完美转发等阻止拷贝。另外线程池只能接受std::function<void()>类型的参数,所以函数参数需要事先使用std::bind(),并且无法得到返回值。
对于Acceptor,接受连接的处理时间较短、报文数据极小,并且一般不会有特别多的新连接在同一时间到达,所以Acceptor没有必要采用epoll ET模式,也没有必要用线程池。由于不会成为性能瓶颈,为了简单最好使用阻塞式socket,故今天的源代码中做了以下改变:
- Acceptor socket fd(服务器监听socket)使用阻塞式
- Acceptor使用LT模式,建立好连接后处理事件fd读写用ET模式
- Acceptor建立连接不使用线程池,建立好连接后处理事件用线程池
多线程Reactor模式
主从Reactor多线程模式
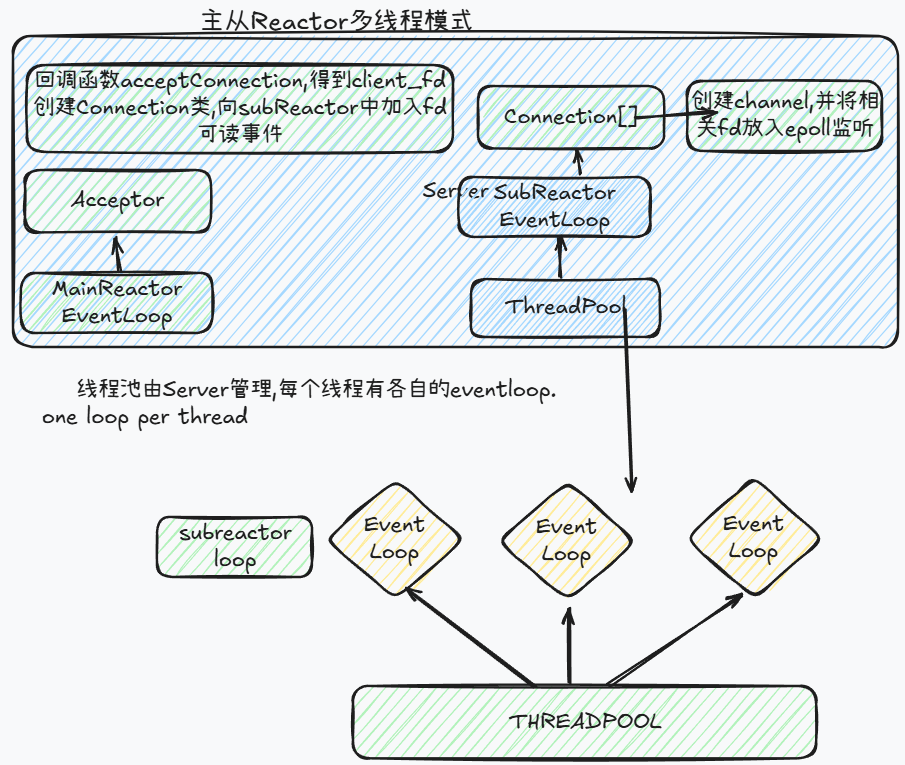
增加多平台支持
BSD系列操作系统提供了kqueue. kqueue 是一种高性能的事件通知接口,主要用于 BSD 系列操作系统(如 FreeBSD、macOS 和 OpenBSD)中。它提供了一种机制来高效地监视多个文件描述符上的 I/O 事件(例如可读、可写等),以及异步 I/O 操作的状态变化。
- kqueue:核心对象,用于注册感兴趣的事件,并从内核获取事件通知。
kevent:表示一个事件或事件类型。可以用来指定你感兴趣的事件(如文件描述符变为可读),也可以用来报告已发生的事件。
主要用途
(1) 监视文件描述符
- 可以监视文件描述符上的各种事件,比如:
- 文件描述符是否可读 (
EVFILT_READ) - 文件描述符是否可写 (
EVFILT_WRITE) - 文件元数据改变 (
EVFILT_VNODE) - 进程信号 (
EVFILT_PROC)
- 文件描述符是否可读 (
(2) 异步 I/O 通知
- 支持异步 I/O 操作的通知机制,允许应用程序在非阻塞模式下更高效地管理大量并发连接。
(3) 高效的事件分发
- 对比传统的轮询方式(如
select()和poll()),kqueue提供了更高的性能和更好的扩展性,特别是在处理大量的文件描述符时。
(1) 创建 kqueue1
2
3
4
5int kq = kqueue();
if (kq == -1) {
perror("kqueue");
exit(1);
}
(2) 设置 kevent
定义感兴趣的事件,并将其添加到 kqueue 中。例如,监视一个套接字是否可读:1
2
3
4
5
6
7
8struct kevent change;
EV_SET(&change, sockfd, EVFILT_READ, EV_ADD, 0, 0, NULL);
if (kevent(kq, &change, 1, NULL, 0, NULL) == -1) {
perror("kevent register");
close(kq);
exit(1);
}
(3) 等待事件发生
调用 kevent() 来等待事件的发生并处理它们:1
2
3
4
5
6
7
8
9
10
11struct kevent event;
int nev = kevent(kq, NULL, 0, &event, 1, NULL);
if (nev == -1) {
perror("kevent wait");
close(kq);
exit(1);
} else if (nev > 0) {
if (event.filter == EVFILT_READ) {
// 处理可读事件
}
}
解决Connection生命周期问题
当在处理connection连接关闭时,会在回调中移除connnection,这样会调用对应析构函数,但此时仍然在connection的channel的handleEvent方法中.
在当前状态下,在创建
TcpConnection会将其加入到connectionsMap_使其引用计数变成了1,之后当TcpConnection处理HandleEvent受到关闭信号时,会直接调用HandleClose,这时会将TcpConnection从connectionsMaps_释放,引用计数变成0,直接销毁,但是HandleEvent并没有处理结束,从而导致了内存泄漏。
增加的两点处理: 在处理事件之前,增加connection的引用计数,这样即使在connectionMap中移除连接,也不会直接释放内存. 此外在每次轮询epoll并处理完事件之后,统一执行一系列回调方法,这样就保证在channel的方法之外进行处理. 在handclose时向eventloop的toDoList中添加一个后处理方法,方法中可以将fd从epoll中移除
除了解决上面析构的生命周期、内存问题,此外如果mainReactor正要加入connection,而此时相同的eventloop中另一个连接要断开. 由于此时线程不同,存在不同线程读写问题,std::map不安全. 可以考虑在增删时加锁,或者将移除操作放在mainReactor的eventloop的toDoList中,相当于将移除connectionMap操作放在了最后. 如果处理的线程与mainReactor相同(主线程),就可以直接移除.
另外存在一个问题,由于移除连接交给了mainReacotr(避免connectionMap线程冲突操作),当有多个连接关闭任务放在mainReacotor的toDoList时,如果其阻塞在epoll_wait就会对性能造成影响,因此可以使用eventfd进行事件通知,类似一个文件描述符,可以加入epoll中并进行读写操作,这可以实现异步唤醒. 每当有Connection进行关闭时,由mainReactor执行,将回调加入toDoList后同时向mainReactor的对应eventfd写入,此时主线程(监听serverfd的EventLoop)就会执行eventfd的channel设置的都操作进行唤醒,然后执行toDoList.
第三方库
网络I/O库总结(libevent,libuv,libev,libeio) - 知乎
- libuv/libuv: Cross-platform asynchronous I/Oenki/libev: Full-featured high-performance event loop loosely modelled after libevent
- libevent/libevent: Event notification library
- Asio C++ Library
其他
在windows上的异步I/O机制
异步 I/O(Asynchronous I/O)是一种高效的机制,用于处理文件、网络套接字等设备的输入输出操作.Windows 提供了多种实现异步 I/O 的方式,包括 Overlapped I/O 和 I/O Completion Ports (IOCP)。
Overlapped I/O
概述
Overlapped I/O 是 Windows 提供的一种异步 I/O 机制,它通过使用 OVERLAPPED 结构体来标记一个 I/O 操作是否为异步。这种机制适用于文件操作和套接字通信。
- 如果一个文件句柄或套接字是以重叠(Overlapped)模式打开的,则可以对其进行异步操作。
- 异步操作完成后,可以通过以下方式通知应用程序:
- 使用事件对象(Event Object)。
- 调用回调函数(Completion Routine)。
- 使用 I/O 完成端口(IOCP)。
关键函数
ReadFile/WriteFile:用于读写文件或套接字。GetOverlappedResult:检查异步操作的状态。CancelIoEx:取消挂起的异步 I/O 操作。
示例代码
以下是一个使用 Overlapped I/O 进行异步文件读取的示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
void AsyncFileRead() {
HANDLE hFile = CreateFile(
"example.txt", // 文件名
GENERIC_READ, // 打开文件用于读取
0, // 不共享
NULL, // 默认安全属性
OPEN_EXISTING, // 打开已存在的文件
FILE_FLAG_OVERLAPPED, // 启用 Overlapped I/O
NULL // 无模板文件
);
if (hFile == INVALID_HANDLE_VALUE) {
printf("Failed to open file. Error: %d\n", GetLastError());
return;
}
char buffer[1024];
OVERLAPPED overlapped = {0};
overlapped.hEvent = CreateEvent(NULL, TRUE, FALSE, NULL); // 创建事件对象
if (!ReadFile(hFile, buffer, sizeof(buffer), NULL, &overlapped)) {
if (GetLastError() != ERROR_IO_PENDING) {
printf("ReadFile failed. Error: %d\n", GetLastError());
CloseHandle(hFile);
CloseHandle(overlapped.hEvent);
return;
}
}
// 等待异步操作完成
WaitForSingleObject(overlapped.hEvent, INFINITE);
DWORD bytesRead;
if (GetOverlappedResult(hFile, &overlapped, &bytesRead, FALSE)) {
printf("Read %d bytes: %.*s\n", bytesRead, bytesRead, buffer);
} else {
printf("GetOverlappedResult failed. Error: %d\n", GetLastError());
}
CloseHandle(hFile);
CloseHandle(overlapped.hEvent);
}
int main() {
AsyncFileRead();
return 0;
}
- Overlapped I/O 是 Windows 中最基础的异步 I/O 实现方式之一。它通过
OVERLAPPED结构体来标记一个 I/O 操作是否为异步。 - 当使用重叠模式打开文件或套接字时,可以发起异步操作,并且在操作完成前继续执行其他代码。
关键函数
CreateFile:创建或打开文件时指定FILE_FLAG_OVERLAPPED标志以启用重叠模式。ReadFile/WriteFile:用于读取或写入数据。对于异步操作,最后一个参数应指向一个有效的OVERLAPPED结构体。GetOverlappedResult:获取异步操作的结果。WaitForSingleObject或WaitForMultipleObjects:等待异步操作完成。
回调函数
在 Windows 中,回调函数通常通过 ReadFileEx 或 WriteFileEx 函数注册,而不是直接使用 ReadFile 或 WriteFile。
回调函数的原型必须符合以下格式:1
2
3
4
5VOID CALLBACK CompletionRoutine(
DWORD dwErrorCode, // 错误码
DWORD dwNumberOfBytesTransfered, // 转移的字节数
LPOVERLAPPED lpOverlapped // OVERLAPPED 结构体指针
);
使用 ReadFileEx 和 WriteFileEx 注册回调函数
ReadFileEx和WriteFileEx是专门用于异步 I/O 并支持回调函数的 API。- 它们需要一个有效的
OVERLAPPED结构体,并且文件句柄必须以重叠模式打开(即带有FILE_FLAG_OVERLAPPED标志)。 异步操作完成后,操作系统会调用指定的回调函数。
回调函数是一种轻量级的异步 I/O 处理方式,通过
ReadFileEx和WriteFileEx函数注册回调函数,在操作完成后自动调用。- 这种方式要求线程进入可提醒等待状态(Alertable Wait State),例如使用
SleepEx函数。
关键函数
ReadFileEx/WriteFileEx:用于启动异步 I/O 操作并注册回调函数。SleepEx:使当前线程进入可提醒等待状态,以便能够接收异步通知。
3. 示例代码
以下是一个使用回调函数处理异步文件读取的完整示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
// 回调函数定义
VOID CALLBACK FileIOCompletionRoutine(
DWORD dwErrorCode,
DWORD dwNumberOfBytesTransfered,
LPOVERLAPPED lpOverlapped)
{
if (dwErrorCode == 0) {
printf("Asynchronous read completed successfully.\n");
printf("Number of bytes read: %d\n", dwNumberOfBytesTransfered);
} else {
printf("Asynchronous read failed with error code: %d\n", dwErrorCode);
}
}
void AsyncFileReadWithCallback() {
HANDLE hFile = CreateFile(
"example.txt", // 文件名
GENERIC_READ, // 打开文件用于读取
0, // 不共享
NULL, // 默认安全属性
OPEN_EXISTING, // 打开已存在的文件
FILE_FLAG_OVERLAPPED, // 启用 Overlapped I/O
NULL // 无模板文件
);
if (hFile == INVALID_HANDLE_VALUE) {
printf("Failed to open file. Error: %d\n", GetLastError());
return;
}
char buffer[1024];
OVERLAPPED overlapped = {0};
// 启动异步读取操作
BOOL result = ReadFileEx(
hFile, // 文件句柄
buffer, // 缓冲区
sizeof(buffer), // 要读取的字节数
&overlapped, // OVERLAPPED 结构体
FileIOCompletionRoutine // 回调函数
);
if (!result) {
printf("ReadFileEx failed. Error: %d\n", GetLastError());
CloseHandle(hFile);
return;
}
// 等待异步操作完成
SleepEx(INFINITE, TRUE); // 进入可提醒等待状态,使回调函数得以执行
CloseHandle(hFile);
}
int main() {
AsyncFileReadWithCallback();
return 0;
}
I/O Completion Ports (IOCP)
概述
I/O Completion Ports(简称 IOCP)是 Windows 提供的一种高性能的异步 I/O 机制,特别适合于需要处理大量并发连接的服务器程序。IOCP 的核心思想是将多个 I/O 操作绑定到一个完成端口,并由一个线程池来处理完成的通知。
- IOCP 的优点:
- 高效地管理多个并发 I/O 操作。
- 自动负载均衡,多个工作线程可以高效协作。
- 支持大规模并发连接。
关键函数
CreateIoCompletionPort:创建或关联一个完成端口。PostQueuedCompletionStatus:向完成端口队列提交自定义的完成包。GetQueuedCompletionStatus:从完成端口队列中获取完成通知。
示例代码
以下是一个简单的 IOCP 示例,展示如何使用 IOCP 处理异步文件读取:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
typedef struct {
OVERLAPPED overlapped;
char buffer[1024];
} IO_CONTEXT;
DWORD WINAPI WorkerThread(LPVOID lpParam) {
HANDLE hCompletionPort = (HANDLE)lpParam;
DWORD bytesTransferred;
ULONG_PTR completionKey;
LPOVERLAPPED pOverlapped;
while (true) {
BOOL result = GetQueuedCompletionStatus(
hCompletionPort, &bytesTransferred, &completionKey, &pOverlapped, INFINITE);
if (!result || bytesTransferred == 0) {
printf("Operation failed or completed.\n");
break;
}
IO_CONTEXT *context = (IO_CONTEXT *)pOverlapped;
printf("Read %d bytes: %.*s\n", bytesTransferred, bytesTransferred, context->buffer);
}
return 0;
}
void AsyncFileReadWithIOCP() {
HANDLE hFile = CreateFile(
"example.txt",
GENERIC_READ,
0,
NULL,
OPEN_EXISTING,
FILE_FLAG_OVERLAPPED | FILE_FLAG_NO_BUFFERING,
NULL
);
if (hFile == INVALID_HANDLE_VALUE) {
printf("Failed to open file. Error: %d\n", GetLastError());
return;
}
HANDLE hCompletionPort = CreateIoCompletionPort(INVALID_HANDLE_VALUE, NULL, 0, 0);
if (!hCompletionPort) {
printf("Failed to create completion port. Error: %d\n", GetLastError());
CloseHandle(hFile);
return;
}
CreateIoCompletionPort(hFile, hCompletionPort, (ULONG_PTR)hFile, 0);
HANDLE hThread = CreateThread(NULL, 0, WorkerThread, hCompletionPort, 0, NULL);
if (!hThread) {
printf("Failed to create worker thread. Error: %d\n", GetLastError());
CloseHandle(hFile);
CloseHandle(hCompletionPort);
return;
}
IO_CONTEXT context = {0};
context.overlapped.Offset = 0;
if (!ReadFile(hFile, context.buffer, sizeof(context.buffer), NULL, &context.overlapped)) {
if (GetLastError() != ERROR_IO_PENDING) {
printf("ReadFile failed. Error: %d\n", GetLastError());
CloseHandle(hFile);
CloseHandle(hCompletionPort);
CloseHandle(hThread);
return;
}
}
WaitForSingleObject(hThread, INFINITE);
CloseHandle(hFile);
CloseHandle(hCompletionPort);
CloseHandle(hThread);
}
int main() {
AsyncFileReadWithIOCP();
return 0;
}
关键函数
CreateIoCompletionPort:创建一个新的完成端口或将其与现有句柄关联。PostQueuedCompletionStatus:手动向完成端口队列中添加状态信息。GetQueuedCompletionStatus:从完成端口队列中检索下一个已完成的操作的状态。
3. 对比 Overlapped I/O 和 IOCP
| 特性 | Overlapped I/O | IOCP |
|---|---|---|
| 适用场景 | 小规模异步操作 | 大规模并发 I/O 操作 |
| 性能 | 较低 | 更高 |
| 复杂度 | 较低 | 较高 |
| 线程管理 | 需要手动管理线程 | 自动管理线程池 |
| 扩展性 | 有限 | 非常强 |
4. 总结
- Overlapped I/O:适合小型应用或需要简单异步 I/O 的场景,易于实现但扩展性较差。
IOCP:适合高性能服务器程序,支持大规模并发连接,具有更高的效率和扩展性,但实现起来更复杂。
简单场景:如果您的应用只需要简单的异步 I/O 操作,Overlapped I/O 可能是最容易实现的选择。
- 高并发场景:如果您正在开发一个需要处理大量并发连接的应用程序(如 Web 服务器),那么 IOCP 是最佳选择,因为它提供了更好的性能和扩展性。
- 轻量级需求:如果希望避免复杂的线程管理并且对性能的要求不是极高,可以考虑使用回调函数的方式。
