消息队列功能很强大,它能使业务降低耦合,异步调用无需等待,下游服务故障不影响上游业务,缓存消息起到流量削峰填谷的作用. 这里介绍其中的RabbitMQ,此外在说一下Elastic Search和MongoDB.
RabbitMQ

消息队列:分布式应用必定涉及到各个系统之间的通信问题,这个时候消息队列也应运而生了。可以说分布式的产生是消息队列的基础
为什么使用消息队列?异步、解耦、削峰
引入消息队列带来的问题: 消息顺序消息 重复消费消息 分布式事务问题等
RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、存储和转发消息。可以把消息传递的过程想象成:当你将一个包裹送到邮局,邮局会暂存并最终将邮件通过邮递员送到收件人的手上,RabbitMQ 就好比由邮局、邮箱和邮递员组成的一个系统。从计算机术语层面来说,RabbitMQ 模型更像是一种交换机模型。
可靠性: RabbitMQ 使用一些机制来保证可靠性, 如持久化、传输确认及发布确认等。
灵活的路由 : 在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能, RabbitMQ 己经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个交换器绑定在一起, 也可以通过插件机制来实现自己的交换器。
扩展性: 多个 RabbitMQ 节点可以组成一个集群,也可以根据实际业务情况动态地扩展 集群中节点。
高可用性 : 队列可以在集群中的机器上设置镜像,使得在部分节点出现问题的情况下队 列仍然可用。
多种协议: RabbitMQ 除了原生支持 AMQP 协议,还支持 STOMP, MQTT 等多种消息 中间件协议。
多语言客户端 :RabbitMQ 几乎支持所有常用语言,比如 Java、 Python、 Ruby、 PHP、 C#、 JavaScript 等。
管理界面 : RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息、集 群中的节点等。
插件机制 : RabbitMQ 提供了许多插件 , 以实现从多方面进行扩展,当然也可以编写自 己的插件。
安装
安装Erlang和Rabbit-mq,1
2rabbitmqctl.bat status
rabbitmq-plugins enable rabbitmq-management
然后访问15672端口可视化管理.
队列类型
RabbitMQ 提供了三种主要的队列类型,它们在数据存储、性能、特性和使用场景上有所不同:
经典队列
- 默认和最常见: 这是 RabbitMQ 最早支持的队列类型,也是如果你不显式指定队列类型时创建的默认类型。
- 灵活的持久性: 可以配置为持久化 (durable) 或非持久化 (transient)。
- 持久化队列: 队列的元数据(队列名称、配置等)和消息都会被写入磁盘。即使 RabbitMQ 服务重启,队列及其消息也不会丢失。
- 非持久化队列: 队列的元数据和消息只存在于内存中。RabbitMQ 服务重启后,队列及其消息会丢失。
- 支持镜像 (Mirrored Queues): 经典队列可以通过配置镜像模式来提高可用性。这意味着队列的主副本存在于一个节点,同时在其他节点上也有同步的副本。当主节点故障时,一个镜像副本可以被提升为新的主副本。
- 优点: 提高了高可用性。
- 缺点: 镜像队列在写入时需要进行同步复制,这会增加网络开销和延迟,影响吞吐量。消费者从主副本消费,如果主副本故障,需要选举新的主副本。
- 性能: 在单节点或非镜像模式下性能较高,但在高可用(镜像)模式下,由于同步复制开销,吞吐量可能会下降。
- 内部实现: 消息通常存储在内存中,并根据需要(如持久化消息或内存不足时)溢出到磁盘。
使用场景:
- 大多数通用消息传递场景。
- 对消息持久性和可靠性有要求,但对吞吐量要求不是极致的场景(特别是在镜像模式下)。
- 需要简单高可用的应用。
仲裁队列(Quorum Queue)
特点:
- Raft 共识算法: 仲裁队列是 RabbitMQ 3.8 版本引入的新队列类型,它基于 Raft 一致性算法实现。Raft 算法确保了分布式系统中的强一致性,比经典队列的镜像机制更健壮。
- 自动高可用: 仲裁队列天生就是分布式的,不需要像经典队列那样手动配置镜像。它会自动在集群中的大多数节点上复制消息。
- 多数派机制 (Quorum): 任何操作(如消息的发布、消费确认)都需要集群中大多数节点的确认才能被视为成功。例如,一个有 3 个节点的仲裁队列,需要 2 个节点的确认。这保证了即使有节点故障,只要多数派存活,数据就不会丢失,并且服务可以继续。
- 更好的数据安全性: Raft 算法确保了消息的强一致性,理论上比经典队列的镜像模式更能避免脑裂 (split-brain) 等问题,提供更高的数据安全性。
- 写入性能: 由于需要多数派确认,写入性能通常会比非镜像的经典队列低,但比镜像的经典队列在某些情况下可能更好,因为它优化了复制过程。
- 消费者行为: 消费者可以从任何副本消费消息,并且消费确认也会通过 Raft 算法进行同步,确保消费的顺序和一致性。
- 只支持持久化: 仲裁队列的消息总是持久化的。
使用场景:
- 对数据一致性和高可用性有极高要求的场景。
- 需要避免数据丢失和脑裂问题的关键业务消息。
- 替代经典队列的镜像模式,提供更健壮的集群行为。
流式队列(Stream Queue)
特点:
- 专为大数据流设计: 流式队列是 RabbitMQ 3.9 版本引入的最新队列类型,其设计目标是处理海量的、连续的、高吞吐量的消息流。
- 类似 Kafka 的特性: 它吸收了 Kafka 等流处理系统的概念,例如:
- 追加日志 (Append-only Log): 消息以追加的方式写入,像一个不可变的日志。
- 多消费者并行消费: 多个消费者可以独立地追踪自己的消费进度(偏移量),从流的不同位置并行消费。
- 消息保留策略: 消息可以被长期保留(例如,保留几天或直到达到某个大小限制),即使它们已经被消费者确认,也可以重新消费。这对于回溯、重放或处理慢速消费者非常有用。
- 高吞吐量: 通过优化内部存储和消费模型,流式队列可以提供比经典队列和仲裁队列更高的吞吐量,尤其是在大量消息的场景下。
- 磁盘友好: 消息主要存储在磁盘上,但通过优化读写性能,依然能保持高吞吐。
- 适用于历史数据回溯: 消费者可以从流的任意位置开始消费,或重新消费已处理过的消息。
- 高可用: 流式队列也有其自身的复制机制来保证高可用性,但其细节与仲裁队列和经典镜像队列有所不同。
使用场景:
- 日志收集和分析。
- IoT (物联网) 数据流处理。
- 事件溯源 (Event Sourcing)。
- 实时数据管道。
- 任何需要处理海量、连续、可回溯消息流的场景。
三种队列类型的比较总结
| 特性 | 经典队列 (Classic Queues) | 仲裁队列 (Quorum Queues) | 流式队列 (Stream Queues) |
|---|---|---|---|
| 设计目标 | 通用消息,灵活配置 | 强一致性,高可用 | 大数据流,高吞吐,可回溯 |
| 高可用 | 需手动配置镜像(同步复制) | 基于 Raft 算法,自动高可用(多数派) | 自身复制机制,高可用 |
| 一致性 | 最终一致性(镜像) | 强一致性 | 强一致性(内部实现) |
| 消息持久性 | 可选(持久化/非持久化) | 总是持久化 | 总是持久化,支持长期保留 |
| 吞吐量 | 单节点高,镜像模式有开销 | 比非镜像经典低,比镜像经典好(某些场景) | 极高,尤其适合大数据流 |
| 消费模型 | 传统消息队列模型,消息一旦消费即移除 | 传统模型,但消费确认更强一致 | 类似 Kafka,支持多消费者独立追踪偏移量,可回溯 |
| 内部实现 | 基于内存/磁盘混合,分段存储 | 基于 Raft 日志,强一致性日志 | 追加日志,磁盘优化 |
| 版本 | 早期版本支持,默认 | RabbitMQ 3.8+ | RabbitMQ 3.9+ |
队列设置
优先级队列
设置队列属性max-priority,发送消息时设置priority属性排序.
交换机类型
交换机 (Exchange) 是消息路由的核心组件。生产者发送消息到交换机,而不是直接发送到队列。交换机接收到消息后,根据其类型和绑定的路由规则,将消息转发到一个或多个队列。
可以把交换机想象成一个邮局的分拣中心。当一封信(消息)到达邮局时,分拣中心(交换机)不会直接把它投递到某个邮箱(队列),而是会根据信封上的地址信息(路由键)和分拣规则(交换机类型及绑定),决定把这封信投递到哪些信箱。
接收消息: 接收来自生产者的消息。
路由消息: 根据自身类型和消息的路由键 (Routing Key),以及与队列之间的绑定 (Binding) 规则,将消息转发到对应的队列。
不存储消息: 交换机本身不存储消息,它只是一个消息转发器。如果一条消息到达交换机,但没有匹配到任何队列,那么这条消息就会被丢弃(除非配置了备份交换机)。
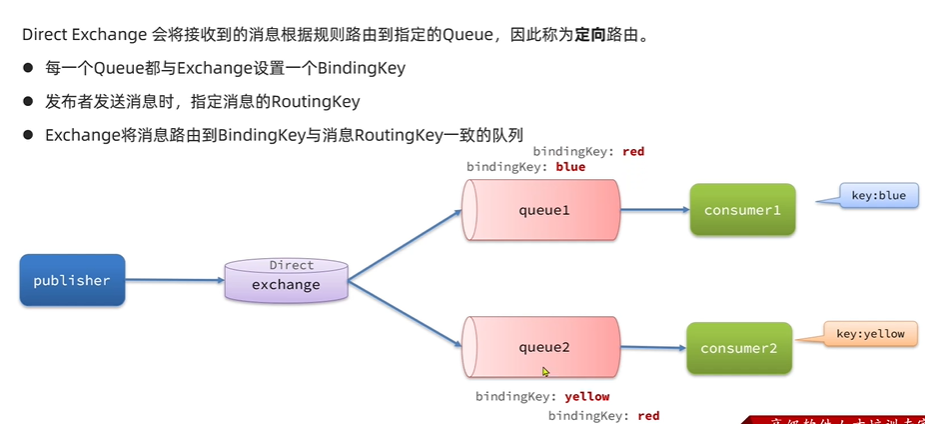
直连交换机 (Direct Exchange)
路由规则: 直连交换机根据消息的路由键(Routing Key)与队列和交换机之间的绑定键(Binding Key)进行精确匹配。
工作方式: 只有当消息的路由键与队列的绑定键完全一致时,消息才会被转发到该队列。
使用场景:
- 点对点消息传递: 当你需要将消息发送到特定队列时。
- 日志系统: 根据日志级别(如
info,warning,error)路由到不同的处理队列。
路由键和绑定键(Binding Key)\需要*精确匹配*。
如何工作: 当一个队列与直连交换机绑定时,它会提供一个绑定键。如果消息的路由键与这个绑定键完全相同,交换机就会将消息转发到这个队列。
示例:
- 队列 Q1 绑定到直连交换机 E1,绑定键是
error。 - 队列 Q2 绑定到直连交换机 E1,绑定键是
info。 - 生产者发送消息到 E1,路由键为
error。只有 Q1 会收到消息。 - 生产者发送消息到 E1,路由键为
warning。没有队列会收到消息(除非有备份交换机)。
1
2
3
4
5void directQueue() {
String exchangeName = "amq.direct";
rabbitTemplate.convertAndSend(exchangeName,"queue1", "hello,this is direct1 exhange");
rabbitTemplate.convertAndSend(exchangeName,"queue2", "hello,this is direct2 exhange");
}
主题交换机 (Topic Exchange)
路由规则: 主题交换机通过模式匹配的方式来路由消息,它也依赖于消息的路由键和绑定键。绑定键可以使用通配符:
*(星号):匹配一个单词。#(井号):匹配零个或多个单词。
示例:
- 队列 Q1 绑定到主题交换机 E2,绑定键是
*.critical。 - 队列 Q2 绑定到主题交换机 E2,绑定键是
audit.#。 - 生产者发送消息到 E2,路由键为
log.critical。Q1 会收到。 - 生产者发送消息到 E2,路由键为
audit.user.login。Q2 会收到。 - 生产者发送消息到 E2,路由键为
report.summary。都没有收到。
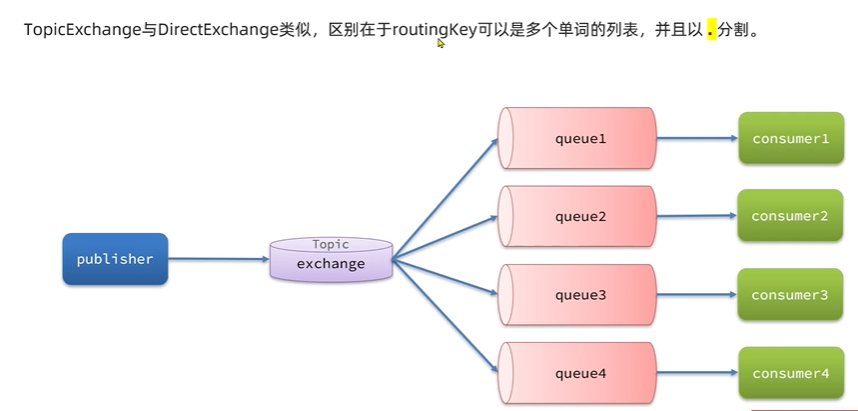
工作方式:
- 路由键和绑定键都是由句点
.分隔的字符串(例如stock.usd.ny)。 - 当消息的路由键与绑定键的模式匹配时,消息会被转发到对应的队列。
使用场景:
- 日志订阅: 灵活地订阅不同来源、不同级别的日志。
- 股票行情: 根据股票代码、货币类型等进行多维度的消息订阅。
- 复杂事件处理: 需要根据事件类型或来源的层级结构进行路由
1 | void topicQueue() { |
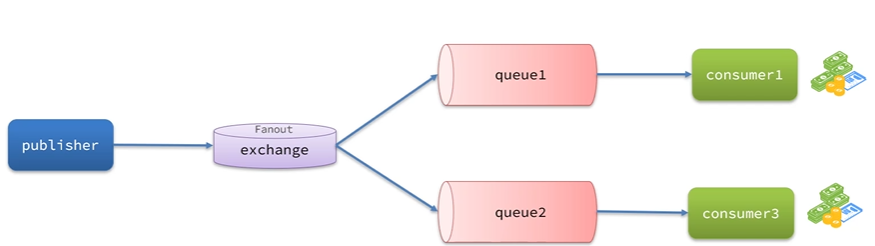
广播/扇形交换机 (Fanout Exchange)
将接收到的消息广播到每一个跟其绑定的队列
路由规则: 扇形交换机最简单,它会忽略消息的路由键。
工作方式: 它会将接收到的所有消息广播到所有与它绑定的队列。
关系: 扇形交换机完全忽略路由键, 无论消息的路由键是什么,扇形交换机都会将所有收到的消息广播到所有与它绑定的队列。路由键的存在只是为了符合协议要求,但其值没有任何路由意义。
示例:
- 队列 Q1、Q2、Q3 都绑定到扇形交换机 E3。
- 生产者发送消息到 E3,路由键为任何值(例如
my.key或whatever)。Q1、Q2、Q3 都会收到消息。
使用场景:
- 广播消息: 例如,通知所有在线用户某个系统维护消息。
- 多任务处理: 一个任务触发后,需要多个不同的服务并行处理该任务的不同方面。
- 缓存更新: 当数据更新时,通知所有需要更新缓存的服务。

1
2
3
4
void fanoutQueue() {
String exchangeName = "amq.fanout";
rabbitTemplate.convertAndSend(exchangeName,null, "hello,this is fanout exhange");}
头交换机 (Headers Exchange)
路由规则: 头交换机是最不常用的一种。它根据消息的头部属性(Headers)而不是路由键来路由消息。
工作方式: 绑定时,你可以指定一系列的键值对(x-match 参数决定匹配规则:any 匹配任一,all 匹配所有)。消息的头部如果包含匹配的键值对,则会被转发。
使用场景:
- 非常特殊的、基于复杂消息元数据的路由需求。
- 当路由键不足以表达所有路由逻辑时。
交换机的核心作用:
- 它是消息路由的第一站,解耦了生产者和队列。
- 不存储消息,只负责转发。
四种交换机类型及其路由规则:
- Direct (直连): 精确匹配路由键。
- Topic (主题): 模式匹配(
*,#通配符)。 - Fanout (扇形): 广播到所有绑定队列,忽略路由键。
- Headers (头): 根据消息头属性匹配(较少用)。
- 面试时,能够清晰地解释每种类型的路由机制和适用场景是关键。
路由键 (Routing Key) 和绑定键 (Binding Key) 的区别和联系:
- Routing Key: 生产者发送消息时附带的,描述消息的属性。
- Binding Key: 队列与交换机绑定时定义的,描述队列希望接收哪类消息。
- 关系: 交换机根据这两者进行匹配,将消息路由到队列。它们的匹配规则取决于交换机的类型。
交换机设置
持久化交换机
保证交换机本身的元数据不会因为 RabbitMQ 服务重启而丢失。
持久化交换机的作用和重要性
当你声明一个交换机时,你可以将其设置为持久化(durable = true)\或*非持久化(durable = false)*。
- 保证交换机定义不丢失:
- 作用: 当一个交换机被声明为持久化时,它的配置信息(名称、类型、是否是持久化等)会被 RabbitMQ 写入磁盘。
- 重要性: 这意味着即使 RabbitMQ 服务器崩溃或被意外关闭,当它重新启动时,这个持久化交换机依然会自动被创建并恢复,无需应用程序重新声明它。这对于系统的稳定性和自恢复能力至关重要。
- 配合持久化队列和持久化消息,实现端到端的可靠性:
- 作用: 持久化交换机本身并不能保证消息的持久性。它只是保证了“通道”的存在。要实现消息在 Broker 重启后不丢失,需要三者协同工作:
- 持久化交换机: 确保交换机定义不丢失。
- 持久化队列: 确保队列定义及其内部存储的消息不丢失。
- 持久化消息: 生产者发送消息时,将
delivery_mode设置为2(Persistent),这样消息内容本身才会被写入磁盘。
- 重要性: 只有这三者都配置为持久化,才能在 RabbitMQ 服务器重启后,确保消息从生产者到达消费者前的整个传递路径上的数据都不会丢失,从而实现端到端的消息可靠性。
- 作用: 持久化交换机本身并不能保证消息的持久性。它只是保证了“通道”的存在。要实现消息在 Broker 重启后不丢失,需要三者协同工作:
死信交换机
死信机制是 RabbitMQ 提供的一种处理无法被正常投递或消费的消息的机制,是消息可靠性设计的重要组成部分。
虽然 DLX/DLQ 不是交换机类型,但它是一个非常重要的概念,涉及到消息无法被消费时的处理。当消息出现以下情况时,会被转发到死信交换机:
- 消息被消费者拒收 (rejected),并且
requeue参数设置为false。 - 消息 TTL (Time-To-Live) 过期。
- 队列达到最大长度 (max-length)。
消息属性与投递属性
消息属性是生产者在发布消息时设置的元数据,随消息一起传递。它们通常用于描述消息的特性或提供额外的处理信息。 常见的消息属性包括:
content_type: 消息体的数据类型(例如application/json)。content_encoding: 消息体的编码方式(例如gzip)。headers: 一个自定义的键值对映射,可以包含应用程序定义的任意元数据。delivery_mode: 消息的持久性。1(Non-persistent): 消息不会写入磁盘,Broker 重启后会丢失。2(Persistent): 消息会写入磁盘,Broker 重启后会保留(但还需要队列是持久化的)。
priority: 消息的优先级(如果队列支持优先级)。correlation_id: 用于关联请求和响应消息,常用于 RPC 模式。reply_to: 用于指定响应消息应该发送到哪个队列,常用于 RPC 模式。expiration: 消息的过期时间(TTL),过期后消息会成为死信。message_id: 消息的唯一标识符,由生产者设置。timestamp: 消息发布时的时间戳。type: 消息类型(应用程序定义)。user_id: 发布消息的用户 ID。app_id: 发布消息的应用程序 ID。
投递属性是 RabbitMQ 在将消息投递给消费者时添加的元数据,它们不属于原始消息本身,而是描述了消息的投递状态。
requeue 和 redelivered 并不是消息本身的属性,而是与消息处理和确认机制相关的行为参数或状态标志。
requeue(行为参数)requeue是在消费者向 RabbitMQ 发送否定确认 (Negative Acknowledgment -basic.reject或basic.nack) 时使用的一个布尔参数。- 当
requeue设置为true时,表示消费者要求 RabbitMQ 将此消息重新放回队列。消息会通常被放回队列的头部或按优先级排序。 - 当
requeue设置为false时,表示消费者拒绝此消息,并且不希望它重新入队。此时,如果队列配置了死信交换机(DLX),消息就会被路由到 DLX;否则,消息会被直接丢弃。
redelivered(状态标志)redelivered是一个布尔型的投递属性。- 当 RabbitMQ 第一次将消息投递给某个消费者时,
redelivered标志为false。 - 如果消息被重新入队(例如,消费者
nack并requeue=true,或者连接断开导致消息自动重新入队),那么当这条消息再次被投递给任何消费者时,它的redelivered标志就会被设置为true。 - 作用: 这个标志告诉消费者:“这条消息不是第一次被投递了,你可能已经处理过它或者它之前未能成功处理。”消费者可以根据这个标志来识别重复投递的消息,并采取相应的处理策略(例如,幂等处理、记录警告、发送到死信队列等)。
消息可靠性
消息可靠性在分布式系统中是一个至关重要的概念,它指的是确保消息在从生产者到消费者的整个生命周期中不会丢失、不被重复处理,并且能够按照预期的顺序被处理。消息不丢失,消息不重复,消息有序性
生产者可靠性
生产者重连
由于网络波动,生产者可能出现连接mq失败的情况,可以设置连接超时和重试时间.1
2
3
4
5# 生产者超时重连
spring.rabbitmq.connection-timeout= 1s
spring.rabbitmq.template.retry.enabled=true
spring.rabbitmq.template.retry.initial-interval=1000ms
spring.rabbitmq.template.retry.max-attempts=3
生产者确认
如果路由失败,通过PublisherReturen返回路由异常原因,返回ACK.告知投递成功.
如果消息投递到了MQ并且入队成功,返回ACK,告知投递成功,其他情况发送nack.
RabbitMQ 提供了两种主要的生产者确认机制:
- 事务 (Transactions)
- 发布者确认 (Publisher Confirms)
RabbitMQ 的事务机制允许将一组消息的发送操作包装成一个原子单元。在事务中,要么所有消息都被 Broker 接收并处理,要么所有消息的操作都被回滚。
它涉及三个基本的 AMQP 命令:
Tx.Select: 声明当前通道进入事务模式。Tx.Commit: 提交事务。一旦提交,所有在事务期间发送的消息都被 Broker 确认接收。Tx.Rollback: 回滚事务。事务期间发送的所有消息都会被丢弃。
优点
- 强一致性保证: 提供了严格的原子性,确保事务内的所有消息要么都成功,要么都失败。
缺点
- 性能开销大: 每个
Tx.Commit命令都会阻塞生产者,直到 Broker 响应。这意味着 Broker 需要对每个事务进行磁盘同步(如果消息是持久化的),这会大大降低消息的吞吐量。 - 不适合高并发场景: 由于其阻塞特性,事务机制不适用于需要高吞吐量或低延迟的场景。
发布者确认是 RabbitMQ 推荐的、更高效的生产者确认机制。它允许生产者异步地接收 Broker 的确认,而无需阻塞发送线程。
启用发布者确认后,Broker 会在以下两种情况下向生产者发送确认:
basic.ack(肯定确认):- 表示消息已成功接收并持久化到磁盘(如果消息和队列都是持久化的),或者已成功路由到至少一个队列(如果消息是非持久化的)。
- 每个
basic.ack都带有一个deliveryTag(通道内递增的唯一标识符),可以确认单条消息或一批消息。
basic.nack(否定确认):- 表示消息已被 Broker 接收,但由于某种原因未能被处理(例如,Broker 内部错误)。
- 这并不意味着消息丢失,而是 Broker 告诉生产者消息可能需要重新发送或进行其他处理
1 | # 生产者确认机制 |
退回机制
当publisher-returns属性设置为 true 时,如果生产者发送的消息无法被路由到任何队列(例如,因为路由键不匹配任何绑定,或者队列不存在),RabbitMQ Broker 会将这条消息”退回”给生产者
需要为 RabbitTemplate 设置一个 ReturnsCallback。
当消息被退回时,ReturnsCallback 会被异步调用,并接收一个 ReturnedMessage 对象作为参数。
ReturnedMessage 对象包含了被退回的原始消息、退回的原因(replyCode 和 replyText,例如 312 NO_ROUTE 表示无路由)、发送时使用的交换机和路由键等信息。
退回回调是rabbitTemplate在初始化后设置的,因此可以在postConstrcut中,以及aware接口,BeanPostProcessor接口等实现.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public class CommonConfig implements ApplicationContextAware {
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
RabbitTemplate rabbitTemplate = applicationContext.getBean(RabbitTemplate.class);
rabbitTemplate.setReturnsCallback(new RabbitTemplate.ReturnsCallback() {
public void returnedMessage(ReturnedMessage returnedMessage) {
Message message = returnedMessage.getMessage();
String exchange = returnedMessage.getExchange();//发送的交换机
int replyCode = returnedMessage.getReplyCode();
String replyText = returnedMessage.getReplyText();
log.info("message:{},exchange:{},replyCode:{},replyText:{}",message,exchange,replyCode,replyText);
}
});
}
}
确认机制
当设置publisher-confirm-type为 CORRELATED 时,Spring AMQP 启用了发布者确认机制,并提供了更细粒度、更强大的确认方式。这是推荐用于生产环境的配置。
- 确认方式: 允许你为每条发送的消息提供一个唯一的
CorrelationData对象(通常包含一个消息 ID)。当 Broker 返回确认(basic.ack或basic.nack)时,这个CorrelationData对象会作为参数传递给RabbitTemplate的ConfirmCallback。 - 关联性: 这是核心优势。通过
CorrelationData,你可以精确地将 Broker 返回的确认与你发送的特定消息关联起来。这对于跟踪消息状态、实现重试逻辑、确保幂等性等非常关键。 - 回调: 你必须设置
RabbitTemplate的ConfirmCallback。当 Broker 返回确认时,该回调会被异步调用。ConfirmCallback会接收CorrelationData、ack(是否成功确认)和cause(如果ack为false,表示原因)作为参数。 - 异步性: 生产者可以持续发送消息,而无需等待 Broker 的确认。确认的回调是异步发生的,大大提高了吞吐量。
设置 RabbitTemplate 的 ConfirmCallback。当 Broker 返回确认时,该回调会被异步调用。ConfirmCallback 会接收 CorrelationData、ack(是否成功确认)和 cause(如果 ack 为 false,表示原因)作为参数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
void testPublisherConfirm() throws InterruptedException {
CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());
correlationData.getFuture().toCompletableFuture().thenAccept(new Consumer<CorrelationData.Confirm>() {
public void accept(CorrelationData.Confirm confirm) {
if (confirm.isAck()) {
// ack成功,接收到ack
log.info("消息成功,收到broker ack");
} else {
// 发送者确认机制,如果没有收到ack
log.info("消息失败,收到broker nack,发送者没有收到ack:{}",confirm.getReason());
}
}
}).exceptionally(new Function<Throwable, Void>() {
public Void apply(Throwable throwable) {
log.error(throwable.getMessage(),throwable);
return null;
}
});
String exchangeName = "amq.direct";
rabbitTemplate.convertAndSend(exchangeName,"queue1", "hello,this is topic exhange",correlationData);
}

消息队列可靠性
默认情况下,会将接收到的消息保存在内存中,但:
- 如果mq宕机,内存中的消息会丢失
- 内存空间有限,如果消费者故障或者处理过慢会导致消息堆积,引发mq阻塞
数据持久化
RabbitMQ实现数据持久化包括三个方面:
消息队列设置durable,发送消息设置delivery_mode为持久化(2)),交换机设置为持久.
持久化使得存储在磁盘避免崩溃数据丢失,同时当消息堆积过多时避免page out(也就是当 Broker 中的消息堆积过多,导致内存压力过大时,RabbitMQ 会将内存中一部分非活跃(未被消费者拉取)的消息暂时从内存中移除并写入到磁盘上,以释放内存资源)
注意在RabbitTemplate中(来自spring-boot-starter-amqp),消息的delivery_mode是21
2
3
4static {
DEFAULT_DELIVERY_MODE = MessageDeliveryMode.PERSISTENT;
DEFAULT_PRIORITY = 0;
}1
2
3public Queue(String name) {
this(name, true, false, false);
}1
2
3
4
5
6
7
8
9
10public abstract class BaseExchangeBuilder<B extends BaseExchangeBuilder<B>> extends AbstractBuilder {
protected final String name;
protected final String type;
protected boolean durable = true;
protected boolean autoDelete;
protected boolean internal;
private boolean delayed;
private boolean ignoreDeclarationExceptions;
private boolean declare = true;
private Object[] declaringAdmins;}
Lazy Queue
惰性队列收到消息后直接存入磁盘而非内存,内存只保留最近消息.
消费者要消费消息时才会从磁盘中读取并加载到内存,支持数百万跳的消息存储.
新版本都是惰性队列
标准队列(非惰性队列)在消息堆积时的行为:
- 内存优先: 默认情况下,标准队列会尽可能地将消息保留在内存中,以提高消息的投递速度。只有当 Broker 的内存达到高水位线时,才会将消息 Page-out (从内存交换到磁盘)。
- 内存峰值: 当消息生产者发送速度远超消费者,导致大量消息在队列中堆积时,这些消息会全部加载到内存中。这可能导致 Broker 内存急剧增长,甚至达到内存限制,触发流控或崩溃。
- 频繁 Page-out/Page-in: 如果消息持续堆积,Broker 会频繁地进行 Page-out 和 Page-in 操作,这会导致大量的磁盘 I/O,严重影响系统性能和消息延迟。
惰性队列的核心思想是“消息总是尽可能地写入磁盘,只有在需要投递时才加载到内存”。
它通过调整消息在队列中的存储策略来达到减少内存占用的目的:
- 主动写入磁盘: 与标准队列不同,惰性队列在接收到消息后,会立即或很快地将消息内容写入到磁盘,只在内存中保留少量消息元数据(如消息索引)。
- 延迟加载: 只有当消息即将被消费者拉取时(例如,消费者连接并准备接收消息),惰性队列才会将这些消息从磁盘读取到内存中进行投递。
- 内存占用低: 即使有大量消息堆积,内存中的实际消息内容非常少,从而大大降低了 Broker 的内存使用。

Lazy Queue 的工作方式是把消息写入磁盘,但这并不意味着消息本身就是持久化的。当 RabbitMQ 收到一个消息时,它首先会根据消息的 delivery_mode 属性来判断:
- 如果
delivery_mode=1(非持久化),RabbitMQ 会直接将消息写入 Lazy Queue 的磁盘存储中,但不会记录持久化日志。这意味着,如果 RabbitMQ 服务重启,这些消息是无法恢复的。 - 如果
delivery_mode=2(持久化),RabbitMQ 会将消息写入 Lazy Queue 的磁盘存储,并且会同步记录持久化日志。当服务重启时,RabbitMQ 会读取这些日志来恢复队列中的所有消息。
因此,Lazy Queue 只是改变了消息的“存放位置”(从内存到磁盘),而 delivery_mode=2 才是真正决定了消息在服务重启后是否能够“恢复”。
懒惰队列的策略是“能不用内存就不用”。
- 触发时机:消息到达时,懒惰队列会立即(或者在很短的时间内)将消息写入磁盘。消息在内存中只保留极少量的元数据。
- 内存使用:这个过程是主动的、即时的。无论队列中消息有多少,绝大多数消息都存储在磁盘上,因此 RabbitMQ 的内存占用非常稳定且低。
- 对性能的影响:虽然消息写入磁盘会产生 I/O 开销,但这个开销是分散在消息到达时进行的。它避免了在系统内存高压时突然进行大量的磁盘 I/O,从而保证了 RabbitMQ 进程的稳定性和响应能力。
消费者可靠性
如果没有确认机制,当消息被投递给消费者后,即使消费者未能成功处理(例如,程序崩溃、网络中断、业务逻辑出错),Broker 也会认为消息已经发送,并将其从队列中删除。这就会导致消息丢失。
消费者确认机制正是为了解决这个问题,它在消费者和 Broker 之间建立了一种“消息处理状态”的反馈机制
消费者确认机制
当消费者处理消息结束后,应该向RabbitMQ发送一个回执,告知MQ消息处理状态.
消费者处理结束后可以向MQ发送一个回执,告知自己消息的处理状态.
- ack:成功处理消息,MQ从队列中删除消息
- nack:消息处理失败,MQ需要再次投递消息
- reject:消息处理失败并拒绝该消息,从队列中删除.
SpringAMQP已经实现了消息确认功能,可以通过配置文件选择ACK处理方式.
none,manual,auto

1
2# 消费者确认机制
spring.rabbitmq.listener.simple.acknowledge-mode=auto
消息失败
当消费者出现异常后,消息会不断requeue到队列,再重新发送给消费者,然后再次异常,再次requeue,无限循环,导致mq消息处理飙升.
配置retry机制,设置最大尝试次数1
2
3
4
5
6spring.rabbitmq.listener.simple.acknowledge-mode=auto
spring.rabbitmq.listener.simple.retry.enabled=true
spring.rabbitmq.listener.simple.retry.initial-interval=1000ms
spring.rabbitmq.listener.simple.retry.max-attempts=3
spring.rabbitmq.listener.simple.retry.multiplier=2
spring.rabbitmq.listener.simple.retry.stateless=true
当重试次数达到后直接抛弃消息,可以通过MessageRecoverer接口来处理,包括三种实现,可以直接reject并丢弃消息,也可以返回nack,重新入队,也可以将失败消息投递到指定的交换机.
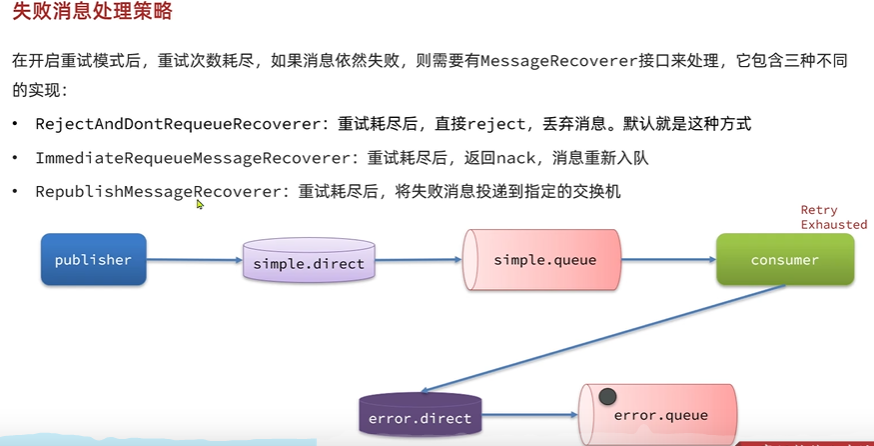

1
2
3
4
public MessageRecoverer messageRecoverer(RabbitTemplate rabbitTemplate) {
return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");
}
业务幂等性
同一个业务执行一次或多次对业务状态的影响是一致的.
设置唯一消息id,可以直接设置消息属性,然后在消费者处将处理后的消息保存到数据库,当新消息

或者基于业务判断,例如在支付后修改订单状态,可以在修改订单状态前先查询订单状态判断状态是否是未支付,未支付才需要修改.

延迟消息
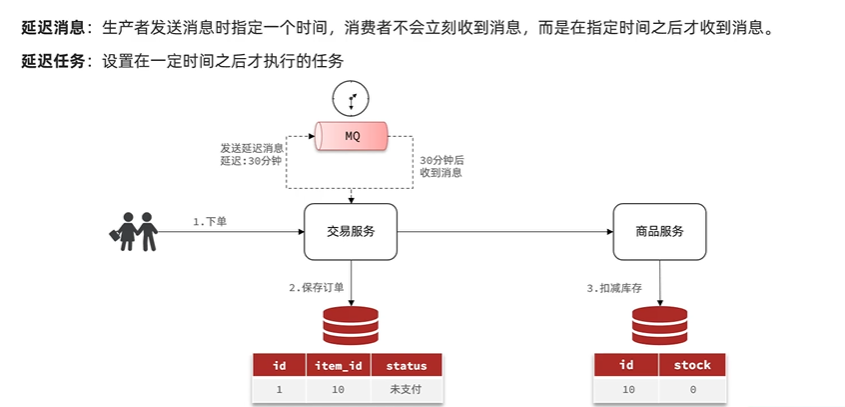
生产者发送消息时指定一个时间,消费者不会立刻收到消息,而是在指定时刻之后才收到消息.
假设在交易之后还未付费,需要发送一个延时消息,在指定时间之后收到检查用户是否已经付费,如果付费则修改订单状态,如果没有付费,商品数量和订单状态都修改.
死信交换机
当一个队列的消息满足以下情况之一时,就会成为死信:
- 消费者使用basic.reject或者basic.nack,并且消息requeue参数为false.
- 消息达到了设置的expiration或者队列的x-max-ttl过期时间但无人消费.
- 队列消息堆积满了,最早的消息成为死信
如果队列通过x-dead-letter-exchange指定交换了交换机,该队列中的死信就会投递到这个交换机.这个交换机就是DLX.
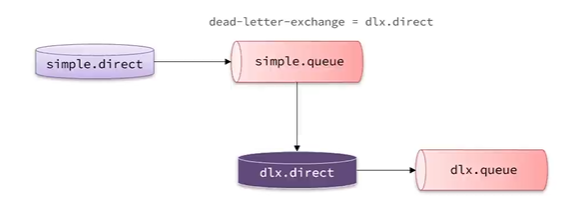
也就是给一个交换机发送消息,然后一个队列接受,给这个队列设置超时时间和死信队列,当超时后到指定的队列中,消费者监听这个队列并进行处理.
延迟消息插件
官方提供插件原生支持延迟消息功能. 插件的原理是设计一种支持延迟消息功能的交换机,当消息投递到交换机后可以延迟一段时间然后再投递到队列.
安装并启用插件,使用delayed交换机,同时设置消息头x-delay设置过期时间.1
2
3
4
5
6
7
8
9
void listenMessage15(Message msg) {
log.info("direct2, Spring接收到消费消息" + msg);
}1
2
3
4
5
6rabbitTemplate.convertAndSend(exchangeName,"queue1", "hihihi",(msg)->{
msg.getMessageProperties().setHeader("x-delay", 10000);
// msg.getMessageProperties().setDelayLong(1000L);
return msg;
});
实现原理是,有一个时钟,当达到超时时间进行任务,因此对cpu压力较大. 适合延时时间较短的场景.
应用:取消超时订单
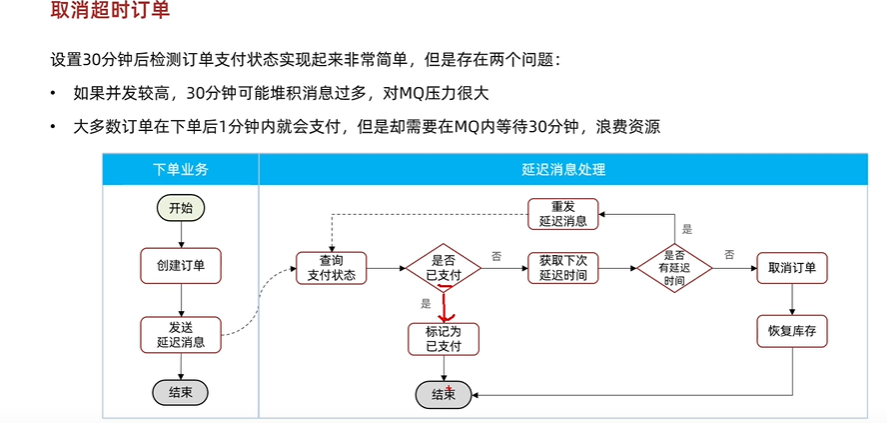
订单完成后,发送延迟消息,进行延迟消息处理,监听对应的延迟消息队列,接收到消息id,查看订单是否已支付,如果支付,则return. 否则继续向延迟交换机发送消息,延迟时间可以设置更长一点.当延迟时间达到最大时间后,取消该订单并恢复库存(事务).
代码案例
最简单的消息发送,直接根据队列名字发送,不通过交换机1
2
3
4
5
void contextLoads() {
String queueName = "hello.queue1";
rabbitTemplate.convertAndSend(queueName, "hello");
}
在接受消息上,spring-amqp提供声明式的消息监听,通过注解在方法上声明要监听的队列名称1
2
3
4
5
6
7
8
public class MqListener {
void listenMessage(String msg) {
log.info("Spring接收到消费消息"+ msg);
}
}
多个消费者绑定到同一个队列时,同一个消息只能被一个消费者消费,默认情况下将消息一次轮询投递给绑定在队列上的每一个消费者,没有考虑消费者是否已经处理完消息(消费者处理能力),可能出现消息堆积.1
2# 每次只能获取一条消息,处理完后再取
spring.rabbitmq.listener.simple.prefetch=1

创建队列,交换机以及绑定关系1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
public class FanOutConfig {
public FanoutExchange exchange() {
return ExchangeBuilder.fanoutExchange("exchange").build();
// return new FanoutExchange("exchange");
}
public Queue fanoutQueue1() {
// return QueueBuilder.durable("queue").build();
return new Queue("queue");
}
public Queue fanoutQueue2() {
return new Queue("queue2");
}
public Binding binding(Queue fanoutQueue1, FanoutExchange fanoutExchange) {
return BindingBuilder.bind(fanoutQueue1).to(fanoutExchange);
}
public Binding bindingQueue2(Queue fanoutQueue2, FanoutExchange fanoutExchange) {
return BindingBuilder.bind(fanoutQueue2).to(fanoutExchange);
}
}
除了创建@Bean的方式,还可以通过注解方式.1
2
3
4
5
6
7
8
public void listenQueue1(String msg) {
log.info("msg");
}

| 元素 | 默认持久化属性 (durable) | 默认 delivery_mode | 行为解释 |
|---|---|---|---|
| 消息 | 否 (delivery_mode=1) | 1 (非持久化) | Broker 重启会丢失,即使队列持久化。 |
| 队列 | 是 (durable=true) | N/A | Broker 重启后队列元数据不会丢失。 |
| 交换机 | 是 (durable=true) | N/A | Broker 重启后交换机元数据不会丢失。 |
导出到 Google 表格
消息转换器
如果发送的不是提供的Message对象或者字符串等,而是直接的pojo或者map,会通过消息转换器进行转换. 对消息对象的处理默认实现是SimpleMessageConverter,基于JDK的ObjectOutputStream完成序列化. 存在问题:JDK序列化消息可读性差,消息太大,有安全风险.
采用json序列化替代默认的JDK序列化
面试重点
交换机(Exchange)的面试重点
交换机的核心作用:
- 它是消息路由的第一站,解耦了生产者和队列。
- 不存储消息,只负责转发。
四种交换机类型及其路由规则:
- Direct (直连): 精确匹配路由键。
- Topic (主题): 模式匹配(
*,#通配符)。 - Fanout (扇形): 广播到所有绑定队列,忽略路由键。
- Headers (头): 根据消息头属性匹配(较少用)。
- 面试时,能够清晰地解释每种类型的路由机制和适用场景是关键。
路由键 (Routing Key) 和绑定键 (Binding Key) 的区别和联系:
- Routing Key: 生产者发送消息时附带的,描述消息的属性。
- Binding Key: 队列与交换机绑定时定义的,描述队列希望接收哪类消息。
- 关系: 交换机根据这两者进行匹配,将消息路由到队列。它们的匹配规则取决于交换机的类型。
绑定 (Binding) 的概念:
- 它是交换机和队列之间的关联关系,定义了消息如何从交换机流向队列。
死信交换机 (Dead Letter Exchange, DLX) 和死信队列 (Dead Letter Queue, DLQ):
- 虽然 DLX/DLQ 不是交换机类型,但它是一个非常重要的概念,涉及到消息无法被消费时的处理。当消息出现以下情况时,会被转发到死信交换机:
- 消息被消费者拒收 (rejected),并且
requeue参数设置为false。 - 消息 TTL (Time-To-Live) 过期。
- 队列达到最大长度 (max-length)。
- 消息被消费者拒收 (rejected),并且
- 面试中常与消息可靠性、异常处理等话题结合考察。
- 虽然 DLX/DLQ 不是交换机类型,但它是一个非常重要的概念,涉及到消息无法被消费时的处理。当消息出现以下情况时,会被转发到死信交换机:
持久化 (Durable) 交换机:
- 和队列一样,交换机也可以被声明为持久化的。这意味着即使 RabbitMQ 服务重启,交换机本身(及其类型、名称、配置)也不会丢失。
- 注意: 持久化交换机只保证交换机的元数据不丢失,不保证消息本身。消息的持久化取决于消息的
delivery_mode和队列的持久化配置。
消息丢失场景:
- 消息到达交换机,但没有匹配到任何队列(除非有备份交换机)。
- 消息被发送到非持久化交换机,且 RabbitMQ 服务重启。
备份交换机 (Alternate Exchange, AE):
当消息无法被路由到任何队列时,交换机可以将这些消息发送到预先配置的备份交换机。这对于捕获和处理那些未能成功路由的消息非常有用,防止消息静默丢失。
如果交换机收到的消息路由键没有匹配到任何队列,消息默认会被丢弃。这会引出备份交换机 (Alternate Exchange) 的概念,它可以在消息无法被路由时捕获这些消息。
死信交换机 (Dead Letter Exchange, DLX) 和死信队列 (Dead Letter Queue, DLQ):
- 虽然 DLX/DLQ 不是交换机类型,但它是一个非常重要的概念,涉及到消息无法被消费时的处理。当消息出现以下情况时,会被转发到死信交换机:
- 消息被消费者拒收 (rejected),并且
requeue参数设置为false。 - 消息 TTL (Time-To-Live) 过期。
- 队列达到最大长度 (max-length)。
- 消息被消费者拒收 (rejected),并且
- 面试中常与消息可靠性、异常处理等话题结合考察。
遇到的问题
使用Jackson2json转化器报错
如果在使用convertAndSend发送消息时可以发现,如果传输的本身就是Message,会直接传输,不做特别处理.但如果在RabbitListener中参数设置为Message,会报conversion异常,这是为什么呢. 核心原因是,在接受消息时,MessagingMessageConverter会调用Jackson2jsonConverter的fromMessage方法,它会根据消息的属性和头部进行推断类型,如果是没有,则会默认将Message的body二进制数据json反序列化为Object,如果转化失败就报错(比如是string的二进制数据).
下面是具体分析:
使用jacksonmessageconverter消息序列化机制
如果是传入对象,首先是Message直接返回,否则进行转换,调用这个converter的toMessage1
2
3
4
5
6
7protected Message convertMessageIfNecessary(Object object) {
if (object instanceof Message msg) {
return msg;
} else {
return this.getRequiredMessageConverter().toMessage(object, new MessageProperties());
}
} // RabbitTemplate类中
然后会在AbstactMessageConverter中调用toMessage方法,jackson2json本身没有toMessage方法,1
2
3
4
5
6
7
8
9
10
11
12
13
14public final Message toMessage(Object object, MessageProperties messagePropertiesArg, Type genericType) throws MessageConversionException {
MessageProperties messageProperties = messagePropertiesArg;
if (messagePropertiesArg == null) {
messageProperties = new MessageProperties();
}
Message message = this.createMessage(object, messageProperties, genericType);
messageProperties = message.getMessageProperties();
if (this.createMessageIds && messageProperties.getMessageId() == null) {
messageProperties.setMessageId(UUID.randomUUID().toString());
}
return message;
}
注意new MessageProperties得到的消息content-type默认是application/octet-stream,然后通过AbstractJackson2MessageConverter的createMessage创建消息,这里就是关键了,这个converter的this.supportedContentType只有application/json,所以这里创建消息,并根据数据设置了长度的属性1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18messageProperties.setContentType(this.supportedContentType.toString());
if (this.supportedCTCharset == null) {
messageProperties.setContentEncoding(this.getDefaultCharset());
}
messageProperties.setContentLength((long)bytes.length);
if (this.getClassMapper() == null) {
JavaType type = this.objectMapper.constructType((Type)(genericType == null ? objectToConvert.getClass() : genericType));
if (genericType != null && !type.isContainerType() && Modifier.isAbstract(type.getRawClass().getModifiers())) {
type = this.objectMapper.constructType(objectToConvert.getClass());
}
this.getJavaTypeMapper().fromJavaType(type, messageProperties);
} else {
this.getClassMapper().fromClass(objectToConvert.getClass(), messageProperties);
}
return new Message(bytes, messageProperties);
到此,toMessage结束.
而在接受消息时,在AbstactMessageListenerContainer中,接收到消息后调用onMessage方法,它会调用messagingMessageListenerAdapter中的toMessage方法,在这个方法中又调用toMessagingMessage方法,然后在其中调用fromMessage方法,在这里就是MessagingMessageConverter的fromMessage方法,1
2
3protected Message<?> toMessagingMessage(org.springframework.amqp.core.Message amqpMessage) {
return (Message)this.getMessagingMessageConverter().fromMessage(amqpMessage);
}
其中有一个extractPayload调用了extractMessage方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15protected Object extractPayload(org.springframework.amqp.core.Message message) {
MessageProperties messageProperties = message.getMessageProperties();
if (this.bean != null) {
messageProperties.setTargetBean(this.bean);
}
if (this.method != null) {
messageProperties.setTargetMethod(this.method);
if (this.inferredArgumentType != null) {
messageProperties.setInferredArgumentType(this.inferredArgumentType);
}
}
return MessagingMessageListenerAdapter.this.extractMessage(message);
}
在extractMessage中获取了jackson2jsonMessageConverter,然后调用其fromMessage方法.1
2
3
4protected Object extractMessage(Message message) {
MessageConverter converter = this.getMessageConverter();
return converter != null ? converter.fromMessage(message) : message;
}
其中会进行判断,如果不是octet-stream或者application/json以及null等,会报不支持1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public Object fromMessage(Message message, Object conversionHint) throws MessageConversionException {
Object content = null;
MessageProperties properties = message.getMessageProperties();
if (properties != null) {
String contentType = properties.getContentType();
if ((!this.assumeSupportedContentType || contentType != null && !contentType.equals("application/octet-stream")) && (contentType == null || !contentType.contains(this.supportedContentType.getSubtype()))) {
if (this.log.isWarnEnabled()) {
this.log.warn("Could not convert incoming message with content-type [" + contentType + "], '" + this.supportedContentType.getSubtype() + "' keyword missing.");
}
} else {
String encoding = this.determineEncoding(properties, contentType);
content = this.doFromMessage(message, conversionHint, properties, encoding);
}
}
if (content == null) {
if (this.nullAsOptionalEmpty) {
content = Optional.empty();
} else {
content = message.getBody();
}
}
return content;
}
然后会在convertContent中进行转换得到目标对象1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36private Object doFromMessage(Message message, Object conversionHint, MessageProperties properties, String encoding) {
Object content = null;
try {
content = this.convertContent(message, conversionHint, properties, encoding);
return content;
} catch (IOException e) {
throw new MessageConversionException("Failed to convert Message content", e);
}
}
private Object convertContent(Message message, Object conversionHint, MessageProperties properties, String encoding) throws IOException {
Object content = null;
JavaType inferredType = this.javaTypeMapper.getInferredType(properties);
if (inferredType != null && this.useProjectionForInterfaces && inferredType.isInterface() && !inferredType.getRawClass().getPackage().getName().startsWith("java.util")) {
content = this.projectingConverter.convert(message, inferredType.getRawClass());
properties.setProjectionUsed(true);
} else if (inferredType != null && this.alwaysConvertToInferredType) {
content = this.tryConverType(message, encoding, inferredType);
}
if (content == null) {
if (conversionHint instanceof ParameterizedTypeReference) {
ParameterizedTypeReference<?> parameterizedTypeReference = (ParameterizedTypeReference)conversionHint;
content = this.convertBytesToObject(message.getBody(), encoding, this.objectMapper.getTypeFactory().constructType(parameterizedTypeReference.getType()));
} else if (this.getClassMapper() == null) {
JavaType targetJavaType = this.getJavaTypeMapper().toJavaType(message.getMessageProperties());
content = this.convertBytesToObject(message.getBody(), encoding, targetJavaType);
} else {
Class<?> targetClass = this.getClassMapper().toClass(message.getMessageProperties());
content = this.convertBytesToObject(message.getBody(), encoding, targetClass);
}
}
return content;
}
得到content,如果为null,则取message.body,然后将该对象包装为message1
2
3
4
5
6
7if (content == null) {
if (this.nullAsOptionalEmpty) {
content = Optional.empty();
} else {
content = message.getBody();
}
}1
2
3
4
5
6
7Object convertedObject = this.extractPayload(message);
if (convertedObject == null) {
throw new MessageConversionException("Message converter returned null");
} else {
MessageBuilder<Object> builder = convertedObject instanceof Message ? MessageBuilder.fromMessage((Message)convertedObject) : MessageBuilder.withPayload(convertedObject);
return builder.copyHeadersIfAbsent(mappedHeaders).build();
}
出现的问题是,如果send发送Message,在convertMessageIfNecessary会直接返回Message,1
2Message build = MessageBuilder.withBody("Helloaa aa ".getBytes(StandardCharsets.UTF_8)).build();
rabbitTemplate.convertAndSend(exchangeName,"queue1", build);
其content-type默认是octet-stream,其中的关键就是,这里根据消息属性判断targetJavaType是Object,1
2
3
4
5
6if (content == null) {
/// ....
} else if (this.getClassMapper() == null) {
JavaType targetJavaType = this.getJavaTypeMapper().toJavaType(message.getMessageProperties());
content = this.convertBytesToObject(message.getBody(), encoding, targetJavaType);
}
具体判断如下,首先根据属性判断,如果为空再根据”_TypeId_“头判断,如果还为空,就默认object了1
2
3
4
5
6
7
8
9
10
11
12
13public JavaType toJavaType(MessageProperties properties) {
JavaType inferredType = this.getInferredType(properties);
if (inferredType != null && this.canConvert(inferredType)) {
return inferredType;
} else {
String typeIdHeader = this.retrieveHeaderAsString(properties, this.getClassIdFieldName());
if (typeIdHeader != null) {
return this.fromTypeHeader(properties, typeIdHeader);
} else {
return this.hasInferredTypeHeader(properties) ? this.fromInferredTypeHeader(properties) : TypeFactory.defaultInstance().constructType(Object.class);
}
}
}
content在进行convertBytesToObject转化过程中报异常,因为byte[]内容是字符串,但转为了Object,而且是通过jackson反序列化转的1
2
3
4
5
6
7
8
9
10
11public <T> T readValue(String content, JavaType valueType) throws JsonProcessingException, JsonMappingException {
this._assertNotNull("content", content);
try {
return (T)this._readMapAndClose(this._jsonFactory.createParser(content), valueType);
} catch (JsonProcessingException e) {
throw e;
} catch (IOException e) {
throw JsonMappingException.fromUnexpectedIOE(e);
}
}
在return (T)this._readMapAndClose(this._jsonFactory.createParser(content), valueType);出错. 所以核心原因还是类型设置为octet-stream会被认为是可以json反序列化的对象.如果直接传字符串,jackon会帮我们序列化为字符串,并在消息属性的头部headers设置__TypeId__类型为String. 但我们自己 手动序列化的数据并填充到Message显然不会有这些机制.

这时什么时候设置的呢? 其实就是在AbstractJackson2MessageConverter的createMessage时,1
2
3
4
5
6
7
8
9
10if (this.getClassMapper() == null) {
JavaType type = this.objectMapper.constructType((Type)(genericType == null ? objectToConvert.getClass() : genericType));
if (genericType != null && !type.isContainerType() && Modifier.isAbstract(type.getRawClass().getModifiers())) {
type = this.objectMapper.constructType(objectToConvert.getClass());
}
this.getJavaTypeMapper().fromJavaType(type, messageProperties);
} else {
this.getClassMapper().fromClass(objectToConvert.getClass(), messageProperties);
}
将对应的类型写入头部1
2
3
4
5
6
7
8
9
10
11public void fromJavaType(JavaType javaType, MessageProperties properties) {
this.addHeader(properties, this.getClassIdFieldName(), javaType.getRawClass());
if (javaType.isContainerType() && !javaType.isArrayType()) {
this.addHeader(properties, this.getContentClassIdFieldName(), javaType.getContentType().getRawClass());
}
if (javaType.getKeyType() != null) {
this.addHeader(properties, this.getKeyClassIdFieldName(), javaType.getKeyType().getRawClass());
}
}
Netty
Netty 是一个高性能、事件驱动的异步网络应用框架,广泛用于构建可扩展的服务器和客户端程序.
基于 Java NIO(同步非阻塞IO),但对其进行了封装和增强,使其更易于使用和性能更优。
关键概念
NIO
NIO是Netty 的基石。传统的 I/O(BIO)是阻塞的,每个连接都需要一个线程处理。NIO 允许单个线程处理多个 I/O 操作,通过 Selector 机制监听多个 Channel 上的事件,从而实现高并发。Netty 在 NIO 之上进行了抽象和优化,使其使用起来更加简单和高效。
IO多路复用
| 特性 | select | poll | epoll |
|---|---|---|---|
| FD 数量限制 | 默认 1024/2048 (固定位图) | 无限制 (受限于内存) | 无限制 (受限于内存) |
| FD 传递 | 每次调用完整复制 (fd_set) | 每次调用完整复制 (pollfd[]) | 一次注册,之后只返回就绪 FD |
| 效率 | O(N) (遍历所有 FD) | O(N) (遍历所有 FD) | O(K) (只遍历就绪 FD, K << N) |
| 通知机制 | 遍历查找 | 遍历查找 | 回调机制,内核通知就绪 |
| 工作模式 | 水平触发 (LT) | 水平触发 (LT) | 水平触发 (LT) / 边缘触发 (ET) |
| “惊群”问题 | 存在 | 存在 | 已优化,通常避免 |
| API 使用 | 相对复杂 | 相对简单 (比 select) | 需要三个系统调用 (create, ctl, wait) |
| 出现时间 | 最早 | 较早 | Linux 2.5.44+ (最新) |
“惊群”问题:当一个事件发生时,所有等待该事件的进程或线程都被唤醒,但实际上只有其中一个能够处理该事件,导致其他被唤醒的进程/线程做了无用功,并产生不必要的上下文切换开销,从而降低了系统效率和性能。
FD传递指的是用户空间每次调用select或 poll 时,需要将 fd_set或pollfd 数组从用户空间完整地复制到内核空间, FD 就绪时,内核会修改对应 pollfd 结构体中的 revents 字段,并将其完整地复制回用户空间。
而在epoll中用户程序通过 epoll_create() 创建一个 epoll 实例。然后通过 epoll_ctl() 一次性地将所有要监控的 FD 注册到内核的 epoll 事件表中,并指定感兴趣的事件。这个过程只需要将 FD 及其事件类型从用户空间复制到内核空间一次.
epoll_wait() 调用时,内核只将就绪列表中的 FD 复制到用户空间。用户程序只需要遍历这些就绪的 FD 即可。
通知机制指的是内核修改了fd_set位图的值并完整返回,fd_set 仍然是一个位图 (bitmap)。它不像一个列表或数组那样直接给出就绪的 FD 列表。它只是在对应 FD 的位上设置为 1,而其他未就绪的 FD 的位仍为 0。为了知道具体是哪个文件描述符就绪了,用户程序必须遍历逐个检查,poll也是类似的,它返回一个pollfd数组,你需要遍历这个数组来检查每个元素的revents` 字段,找出就绪的 FD。
而 epoll 则不同,epoll_wait 会直接返回一个已就绪文件描述符的列表或数组,用户程序只需要遍历这个较小的就绪列表即可,因此效率更高,时间复杂度是 O(K)。
Netty相比NIO改进
Channel->NioSocketChannel/NioServerSocketChannel
Selector->EventLoop/EventLoppGroup
Buffer->ByteBuf
此外通过ChannelPipeline和ChannelHanlder来处理自定义事件.
相比于直接使用Websocke优点
Netty 是一个高性能、异步事件驱动的网络应用框架,用于快速开发可维护的高性能协议服务器和客户端。它封装了 Java NIO(非阻塞 I/O),提供了高级 API,让开发者可以专注于业务逻辑,而无需关心底层复杂的网络编程细节(如线程管理、I/O 多路复用、协议编解码等)
WebSocket 是一种在单个 TCP 连接上进行全双工通信的协议。它允许服务器和客户端之间进行持久性连接,双方可以随时发送消息,而无需像传统的 HTTP 请求-响应模式那样每次都建立新连接。
EventLoop & EventLoopGroup 事件循环与事件循环组
- EventLoop: Netty 的核心线程模型。每个
EventLoop是一个单线程,负责处理一个或多个 Channel 上的所有 I/O 事件(如连接建立、数据读写、断开连接),并执行关联的 ChannelHandler。它以事件驱动的方式运行,通过一个循环不断地从任务队列中获取事件并执行。 - EventLoopGroup: 包含一个或多个
EventLoop的组。通常有两个EventLoopGroup:- BossGroup (或 AcceptorGroup): 负责处理客户端的连接请求。一旦接受到连接,就会将连接注册到 WorkerGroup 中的某个
EventLoop上。通常只有一个EventLoop或少量EventLoop。 - WorkerGroup: 负责处理已建立连接的 I/O 读写事件和业务逻辑。包含多个
EventLoop,以实现并发处理。
- BossGroup (或 AcceptorGroup): 负责处理客户端的连接请求。一旦接受到连接,就会将连接注册到 WorkerGroup 中的某个
Channel 通道 Netty 对网络连接的抽象。可以看作是连接双方进行数据传输的“通道”。所有的 I/O 操作都在 Channel 上进行。不同类型的 Channel 对应不同的传输协议(如 NioSocketChannel 用于 TCP/IP,NioDatagramChannel 用于 UDP)。
ChannelHandler & ChannelPipeline 处理器与处理器链
- ChannelHandler: 消息处理的核心组件。它是一个接口,定义了处理入站 (Inbound) 或出站 (Outbound) 事件的方法。
- ChannelInboundHandler: 处理从网络读入的数据(入站事件),例如接收到连接、读取数据、处理异常等。
- ChannelOutboundHandler: 处理向网络写入的数据(出站事件),例如发送数据、连接断开等。
- 你可以自定义
ChannelHandler来实现协议编解码、业务逻辑处理、日志记录、流量控制等功能。
- ChannelPipeline:
ChannelHandler的链表。每个Channel都有一个ChannelPipeline。当 I/O 事件发生时,数据会沿着ChannelPipeline在不同的ChannelHandler之间流动,形成一个责任链模式。- 入站事件 (Inbound Event): 数据从网络流入,从
ChannelPipeline的头部(第一个ChannelHandler)开始,依次向后传递,直到链的尾部。 - 出站事件 (Outbound Event): 数据从应用程序流出到网络,从
ChannelPipeline的尾部(通常是触发写入操作的地方)开始,依次向前传递,直到链的头部。
- 入站事件 (Inbound Event): 数据从网络流入,从
ByteBuf 字节缓冲区
Netty 自己的高性能字节缓冲区,用于替换 Java NIO 的 ByteBuffer。ByteBuf 提供了许多优化和改进,使其更易于使用,例如:
- 读写指针分离: 独立的
readerIndex和writerIndex,避免了ByteBuffer复杂的flip()操作。 - 动态扩容: 当容量不足时,可以自动扩容。
- 零拷贝 (Zero-Copy): 通过复合缓冲区(CompositeByteBuf)和切片(Slice)等机制,尽量减少数据在内存中的拷贝,提高性能。
- 引用计数: 自动管理内存,防止内存泄漏。
Future & Promise 异步结果与承诺
- Future: Java 并发包中的
Future增强版。在 Netty 中,所有的 I/O 操作都是异步的,它们会立即返回一个ChannelFuture对象。你可以通过监听ChannelFuture来获取操作的最终结果(成功、失败或取消)。 - Promise:
Future的子接口,允许在某个点设置Future的结果,从而完成异步操作。
编解码器 (Encoders & Decoders)
ChannelHandler 的特殊形式,用于将原始字节数据转换为特定协议的消息对象,以及将消息对象转换回字节数据。
- Decoder (入站): 将字节流解码成 Java 对象。
- Encoder (出站): 将 Java 对象编码成字节流。
- Netty 提供了许多内置的编解码器(如
StringEncoder/StringDecoder、HTTP 编解码器),也支持自定义协议编解码。
关键问题
关于 Netty 的问题通常会围绕其高性能、异步特性和核心组件展开。
Netty 的优势和使用场景
- 为什么用 Netty? 高性能、高并发、异步非阻塞、易于开发、稳定可靠、社区活跃。
- 能用来做什么? RPC 框架(Dubbo、gRPC)、IM 系统、游戏服务器、大数据传输、消息中间件、HTTP 服务器、WebSocket 服务器、代理服务器等。
Netty 的线程模型
- EventLoopGroup (Boss/Worker) 的作用?
- BossGroup (或 AcceptorGroup):主要负责处理客户端的连接请求。当有新的客户端连接到来时,BossGroup 中的一个
EventLoop会接受这个连接,并将其注册到 WorkerGroup 中的一个EventLoop上。BossGroup 通常只需要一个或少数EventLoop。 - WorkerGroup:负责处理已建立连接的 I/O 读写事件和业务逻辑。WorkerGroup 包含多个
EventLoop,每个EventLoop都可以处理多个Channel(连接)上的事件。
Channel 分配机制: 当 BossGroup 接受一个新连接后,它会使用一个轮询(Round-Robin)或其他策略,将这个新连接(
Channel)注册到 WorkerGroup 中一个特定的 EventLoop 上。一旦一个Channel被分配给某个EventLoop,该Channel的所有后续 I/O 事件(读、写、关闭等)都将由这个EventLoop线程负责处理,从而保证了单个Channel的事件处理是线程安全的和有序的为什么是单线程 EventLoop?
避免了多线程并发访问
Channel带来的同步开销和复杂性,简化了并发编程模型。一个Channel上的所有事件都由同一个EventLoop线程顺序处理,保证了事件的顺序性。I/O 线程和业务线程分离: 业务逻辑如果在
ChannelHandler中耗时过长,会阻塞EventLoop线程,影响其他 Channel 的 I/O 处理。如何解决?(使用EventLoop.execute()提交任务到 EventLoop 线程,或使用EventLoopGroup的next().submit()提交到另一个线程池)。
如果
ChannelHandler中的业务逻辑执行时间过长,确实会阻塞EventLoop线程,导致该EventLoop负责的其他Channel的 I/O 事件无法及时处理,影响系统的响应性和吞吐量。解决这个问题通常有两种方法:- 提交任务到 EventLoop 线程: 对于一些轻量级但又不希望立即执行的任务,可以通过
EventLoop.execute(Runnable task)或EventLoop.submit(Callable<T> task)将任务提交到EventLoop自身维护的任务队列中。这些任务会在 I/O 操作空闲时被EventLoop线程顺序执行,但如果任务依然耗时,仍可能阻塞。 - 使用独立的业务线程池: 这是更常用的方法,适用于耗时长的业务逻辑。在
ChannelHandler中,当接收到消息并需要进行耗时操作时,不直接在EventLoop线程中执行,而是将该业务逻辑提交到一个独立的业务线程池(例如ThreadPoolExecutor)中执行。当业务逻辑处理完成后,再将结果通过ChannelHandlerContext写回Channel。
ChannelPipeline 和 ChannelHandler
- ChannelPipeline 是什么?
ChannelPipeline 是一个
ChannelHandler的有序链表。每个Channel都有且只有一个ChannelPipeline。它扮演着事件处理的责任链角色,负责协调和管理ChannelHandler的执行顺序。双向链表的设计是为了支持消息流的双向性:
- 入站事件 (Inbound Event):数据从网络流入应用程序(例如客户端发送数据到服务器),事件从
ChannelPipeline的头部(第一个ChannelHandler)开始,依次向后传递。 出站事件 (Outbound Event):数据从应用程序流出到网络(例如服务器向客户端发送响应),事件从
ChannelPipeline的尾部(通常是业务逻辑触发write操作)开始,依次向前传递ChannelInboundHandler和ChannelOutboundHandler的区别?
ChannelInboundHandler(入站处理器):- 职责: 主要处理从网络端流入到应用程序的事件,例如:连接激活 (
channelActive())、读取数据 (channelRead())、连接断开 (channelInactive())、处理异常 (exceptionCaught()) 等。 - 处理顺序: 在
ChannelPipeline中,入站事件从头部向尾部流动,依次经过每个ChannelInboundHandler。
ChannelOutboundHandler(出站处理器):- 职责: 主要处理从应用程序流出到网络端的事件,例如:写入数据 (
write())、连接 (connect())、绑定 (bind())、关闭 (close()) 等。 处理顺序: 在
ChannelPipeline中,出站事件从尾部向头部流动,依次经过每个ChannelOutboundHandler。如何自定义 Handler? 常见的
SimpleChannelInboundHandler和ChannelDuplexHandler。ChannelHandlerContext的作用? 用于与 Pipeline 中的其他 Handler 交互,以及触发事件。
ChannelHandlerContext 是
ChannelHandler与ChannelPipeline以及其他ChannelHandler之间交互的桥梁。每个ChannelHandler被添加到ChannelPipeline时,都会创建一个对应的ChannelHandlerContext实例。- 消息在 Pipeline 中传递的机制?
fireChannelRead()、write()等方法。
ByteBuf 内存管理
- 为什么不用
ByteBuffer而用ByteBuf? 读写指针分离、动态扩容、引用计数、零拷贝。 readerIndex和writerIndex? 如何操作数据?ByteBuf的引用计数? 为什么重要?如何避免内存泄漏?(retain()和release())- 堆内存 (Heap ByteBuf) 和直接内存 (Direct ByteBuf) 的区别? 优缺点?什么时候用哪个?(Direct ByteBuf 减少一次拷贝,适用于大文件传输;Heap ByteBuf 更易于 GC)。
- 为什么不用
零拷贝 (Zero-Copy)
- Netty 如何实现零拷贝? 概念、
FileRegion、CompositeByteBuf、ByteBuf.slice()。 - 零拷贝的优势? 减少 CPU 拷贝,提高 I/O 性能。
什么是 TCP 粘包/拆包?Netty 是如何解决的?
回答要点:
- 什么是粘包/拆包?
- TCP 是一个流式协议,它不保证每次
read()或write()系统调用对应一个完整的应用层消息。它会把应用层发送的数据看作一个字节流,可能会将小的消息合并(粘包)成一个大的 TCP 包发送,也可能将一个大的应用层消息拆分成多个小的 TCP 包(拆包)发送。 - 粘包: 发送方发送了两个独立的小消息 A 和 B,TCP 层可能将它们合并成一个数据包发送,接收方一次性收到 A+B。
- 拆包: 发送方发送一个大的消息 C,TCP 层可能将其拆分成多个数据包发送,接收方需要多次读取才能得到完整的 C。
- TCP 是一个流式协议,它不保证每次
- 为什么会发生?
- TCP 缓冲区机制。
- Nagle 算法(小数据包合并)。
- 发送方每次发送的数据量与接收方每次读取的数据量不一致。
- Netty 如何解决?
- Netty 不直接在 TCP 层解决,而是在应用层通过编解码器(Decoder)来解决。它提供了多种开箱即用的
ChannelInboundHandler(解码器),用于根据特定的应用层协议规则来解析字节流,将原始字节数据正确地分割成完整的、逻辑上的消息帧:FixedLengthFrameDecoder: 固定长度帧解码器,按照预设的固定长度切分消息。LineBasedFrameDecoder: 行解码器,根据换行符(\n或\r\n)切分消息。DelimiterBasedFrameDecoder: 分隔符解码器,根据用户指定的特殊分隔符切分消息。LengthFieldBasedFrameDecoder: 基于长度字段的帧解码器(最常用和推荐),在消息的头部包含一个表示消息体长度的字段。解码器会先读取这个长度字段,然后等待足够的数据到达,再截取对应长度的消息体。
- Netty 不直接在 TCP 层解决,而是在应用层通过编解码器(Decoder)来解决。它提供了多种开箱即用的
- Netty 如何实现零拷贝? 概念、
编解码器 (Encoders/Decoders)
- 编解码器的作用? 为什么需要它们?
- 与
ChannelHandler的关系?
Netty 的异步特性
- I/O 操作都是异步的,如何获取结果?
ChannelFuture和ChannelFutureListener。 Promise和Future的区别?
- I/O 操作都是异步的,如何获取结果?
与 Java NIO 的关系和区别
- Netty 是对 Java NIO 的封装和增强,解决了哪些 NIO 的痛点? (API 复杂、Selector Bug、缓冲区管理困难、多线程处理等)。
Netty 的连接管理和心跳机制
- IdleStateHandler: 如何检测连接空闲?
- 心跳消息: 如何实现客户端和服务端的心跳?
IdleStateHandler是 Netty 提供的一个ChannelHandler,用于检测连接的空闲状态(即在指定时间内没有读或写操作发生)。- 原理:
IdleStateHandler会在ChannelPipeline中维护一个定时任务。当连接在指定的readerIdleTime(读空闲时间)、writerIdleTime(写空闲时间)或allIdleTime(总空闲时间)内没有相应的 I/O 操作时,它会触发一个IdleStateEvent事件,并将其传递到ChannelPipeline的下一个ChannelInboundHandler。 - 使用方式: 通常,你需要在
IdleStateHandler之后再添加一个自定义的ChannelInboundHandler(例如继承ChannelInboundHandlerAdapter),并重写其userEventTriggered(ChannelHandlerContext ctx, Object evt)方法来捕获并处理IdleStateEvent。
心跳消息是利用
IdleStateHandler检测到的空闲状态,在客户端或服务端发送的周期性短消息,用于维持连接的活性、检测连接的可用性以及防止因长时间空闲而被防火墙或路由器关闭。实现步骤:
- 添加
IdleStateHandler: 在客户端和服务器端的ChannelPipeline中都添加IdleStateHandler,配置合适的读/写/总空闲时间。 - 自定义
HeartbeatHandler: 在IdleStateHandler之后添加一个自定义的ChannelInboundHandler。 - 处理
IdleStateEvent:- 客户端: 当检测到写空闲(
IdleState.WRITER_IDLE)时,客户端发送一个心跳请求消息给服务器。 - 服务端: 当检测到读空闲(
IdleState.READER_IDLE)时,表示客户端可能已经断开或处于异常状态。此时,服务器可以发送一个心跳响应消息,或直接关闭连接。如果服务器也发送了心跳请求,它会期望客户端在指定时间内返回响应。
- 客户端: 当检测到写空闲(
- 心跳消息的响应:
- 服务端收到心跳请求后,应该立即回复一个心跳响应消息。
- 客户端收到心跳响应后,确认连接正常。
- 超时处理:
- 如果在发送心跳请求后,在规定时间内没有收到心跳响应,则认为连接已断开,可以主动关闭连接。这通常在
HeartbeatHandler中通过计数器实现。
- 如果在发送心跳请求后,在规定时间内没有收到心跳响应,则认为连接已断开,可以主动关闭连接。这通常在
1 | public class MyServer { |
MongoDB
MongoDB 是一款流行的NoSQL 文档型数据库,以其灵活的数据模型、可伸缩性和高性能而闻名。它广泛应用于需要处理大量非结构化或半结构化数据、以及需要快速迭代的应用场景。在面试中,MongoDB 经常作为后端数据存储、大数据或微服务架构中的组件被提及。
关键概念
Document (文档)
- 核心单位: 文档是 MongoDB 中数据的基本单位,类似于关系型数据库中的行 (row)。
- JSON-like 格式: 文档以类似 JSON 的 BSON (Binary JSON) 格式存储。BSON 支持更多的数据类型(如日期、二进制数据)并且是二进制编码,这使得存储和传输更高效。
- 无模式 (Schemaless/Schema-less): 这是 MongoDB 最重要的特性之一。同一个集合中的文档可以拥有不同的字段,字段的类型也可以不同。这提供了极大的灵活性,方便快速迭代和适应变化的需求。
- 面试点: 理解文档是 MongoDB 的核心,其无模式特性提供了灵活性
Collection (集合)
- 逻辑分组: 集合是文档的逻辑分组,类似于关系型数据库中的表 (table)。
- 无固定结构: 集合不强制文档的结构,但通常同一集合中的文档会包含类似或相关的数据。
- 面试点: 知道集合是文档的容器,其无模式特性与集合的关系。
Database (数据库)
- 容器: 数据库是集合的物理容器,类似于关系型数据库中的数据库 (database)。
- 多数据库: 一个 MongoDB 实例可以承载多个数据库。
- 面试点: 数据库是组织集合的单元。
_id 字段
- 主键: 每个文档在创建时都会自动生成一个唯一的
_id字段作为其主键,除非你手动指定。 - ObjectID: 默认情况下,
_id的类型是ObjectID,它是一个 12 字节的 BSON 类型,结合了时间戳、机器标识符、进程 ID 和计数器,以确保全局唯一性。 - 面试点: 了解
_id的作用和ObjectID的组成。
Index (索引)
- 提高查询效率: 索引是 MongoDB 提高查询性能的关键。它允许数据库快速定位数据,而无需扫描整个集合。
- 种类: 支持单字段索引、复合索引、多键索引(用于数组字段)、文本索引(用于全文搜索)、地理空间索引等。
- 面试点: 索引的重要性,以及不同类型索引的适用场景。复合索引和多键索引是常考点。
Aggregation (聚合)
- 数据处理: 聚合操作允许你对数据进行复杂的处理,如分组、筛选、转换、计算等,以生成汇总报告或分析结果。
- 聚合管道 (Aggregation Pipeline): 这是 MongoDB 最强大的聚合工具。它由一系列阶段 (stages) 组成,数据在这些阶段中依次处理,每个阶段的输出作为下一个阶段的输入。
- 面试点: 理解聚合管道的工作原理,常用阶段(
$match,$group,$project,$sort,$limit,$unwind)及其用途。
Replication (副本集)
- 高可用性与数据冗余: 副本集是 MongoDB 提供高可用性和数据冗余的机制。它是一组维护相同数据集的 MongoDB 实例。
- Primary-Secondary 架构: 副本集中有一个主节点 (Primary),负责处理所有写入操作和读操作。其他是从节点 (Secondary),它们复制主节点的数据,并可以处理读操作(如果配置允许)。
- 自动故障转移: 当主节点发生故障时,副本集会自动选举一个从节点成为新的主节点,从而保证服务持续可用。
- 面试点: 高频考点。 理解副本集的工作原理,主从节点的作用,以及自动故障转移过程。
Sharding (分片)
- 水平扩展: 分片是 MongoDB 提供水平扩展的方式,用于处理大量数据和高吞吐量操作。它将数据分布在多个独立的服务器(称为分片或 Shard)上。
- 组成:
- Shard (分片): 存储部分数据的独立副本集。
- Config Server (配置服务器): 存储集群的元数据(分片信息、数据分布规则)。
- Mongos (路由进程): 负责处理客户端请求,将请求路由到正确的分片,并聚合结果。
- 面试点: 高频考点。 理解分片解决的问题(海量数据存储和高并发),以及分片集群的各个组件及其职责。
CRUD 操作 (Create, Read, Update, Delete)
- MongoDB 提供了丰富的操作来对文档进行增删改查。
insertOne(),insertMany(): 插入文档。find(),findOne(): 查询文档(支持强大的查询语言,包括嵌套文档查询、数组查询、聚合查询等)。updateOne(),updateMany(),replaceOne(): 更新文档。deleteOne(),deleteMany(): 删除文档。- 面试点: 熟悉基本的 CRUD 操作语法和常用查询方法。
关键问题
什么是 NoSQL 数据库?MongoDB 属于哪种 NoSQL 类型?
NoSQL 定义: Not Only SQL。它是一类不使用传统关系型数据库的表格模型存储数据的数据存储系统。NoSQL 数据库通常为了特定的数据模型和访问模式而优化,牺牲了部分关系型数据库的特性(如强 ACID 事务和 JOIN 操作)来换取更高的可伸缩性、灵活性和性能。
MongoDB 类型: 文档型数据库。数据以类似 JSON 的 BSON(Binary JSON)格式的文档形式存储
MongoDB 的核心特点是什么?
- 文档模型: 数据以 BSON 格式的文档存储,结构灵活,无模式 (Schema-less),易于开发迭代。
- 高可用性: 通过副本集(Replica Set)实现自动故障转移和数据冗余。
- 水平扩展: 通过分片(Sharding)技术将数据分布到多个服务器,处理海量数据和高并发。
- 高性能: 文档模型、索引、内存映射文件等优化手段提供了出色的读写性能。
- 丰富的查询语言: 支持强大的查询语言,包括嵌套文档查询、聚合框架等。
MongoDB 的 _id 字段有什么特殊之处?
- 主键: 每个 MongoDB 文档都必须包含一个
_id字段,作为其在集合中的唯一主键。 - 自动生成: 如果插入文档时未指定
_id,MongoDB 会自动生成一个ObjectID作为其值。 - ObjectID 组成:
ObjectID是一个 12 字节的 BSON 类型,它包含时间戳、机器标识符、进程 ID 和一个计数器,确保了全局唯一性。 - 不可变性:
_id字段的值一旦创建就不可更改。
什么是副本集(Replica Set)?它有什么作用?
- 定义: 副本集是一组维护相同数据集的 MongoDB 实例。它由一个主节点 (Primary) 和一个或多个从节点 (Secondary) 组成。
- 作用:
- 高可用性: 当主节点发生故障时,副本集会自动选举一个健康的从节点成为新的主节点,确保服务持续可用,避免单点故障。
- 数据冗余: 从节点复制主节点的数据,提供数据的多份副本,防止数据丢失。
- 读扩展: 可以配置从节点处理读请求(但要注意读的最终一致性),从而分散主节点的读负载。
- 工作原理简述: 所有写入操作都在主节点上进行,然后通过操作日志 (Oplog) 异步复制到所有从节点。
什么是分片(Sharding)?为什么要使用分片?
- 定义: 分片是一种水平扩展(Horizontal Scaling)\的技术。它将大型数据集分布存储到多个独立的数据库实例(即*分片/Shard*)上。
- 为什么要用:
- 处理海量数据: 单个服务器的存储容量和内存有限,分片可以突破这些限制。
- 高并发和吞吐量: 将查询和写入负载分散到多个分片上,提高系统的整体吞吐量。
- 降低成本: 可以使用更多的廉价服务器替代少数昂贵的高配服务器。
- 分片集群的组成:
- Shards (分片): 存储部分数据的独立副本集。
- Config Servers (配置服务器): 存储集群的元数据(分片信息、数据分布规则)。
- Mongos (路由进程): 处理客户端请求,将请求路由到正确的分片,并聚合结果。
解释 MongoDB 的数据模型设计:嵌入式文档(Embedded Documents)与引用(References)的区别和选择。
- 嵌入式文档: 将相关数据直接嵌套存储在同一个文档中。
- 优点: 单次查询即可获取所有数据,读性能好;原子性操作(对单个文档的更新)。
- 缺点: 单文档大小限制(16MB);数据冗余(如果子文档被多处引用);更新复杂性(大文档更新或增长)。
- 适用场景: 一对一、一对多关系(子文档数量有限且不常变),数据紧密耦合且经常一起查询。
- 引用: 通过存储另一个文档的
_id来建立文档间的关联,类似关系型数据库的外键。需要使用$lookup或在应用层进行多次查询来获取关联数据。- 优点: 减少数据冗余;突破文档大小限制;灵活处理多对多关系。
- 缺点: 需要多次查询或使用
$lookup,性能可能不如嵌入式文档;查询逻辑可能更复杂。 - 适用场景: 多对多关系;一对多关系(子文档数量多且动态增长);数据独立性强,不总是与父文档一起查询。
- 选择策略: 核心原则是“应用程序如何使用数据”。优先考虑将那些原子性高、总是被一起查询的数据嵌入到文档中。对于那些独立存在、会被大量引用或可能变得很大的数据,使用引用。
什么是 MongoDB 的索引?有哪些常用的索引类型?
- 作用: 索引是提高查询性能的关键。它允许数据库快速定位到匹配查询条件的文档,而无需扫描整个集合。
- 常用类型:
- 单字段索引: 在单个字段上创建。
- 复合索引 (Compound Index): 在多个字段上创建,字段顺序很重要(最左前缀原则),支持多字段查询和排序。
- 多键索引 (Multikey Index): 自动为包含数组的字段创建,为数组中每个元素创建索引条目,支持对数组内容的查询。
- 文本索引 (Text Index): 支持对字符串内容进行全文搜索。
- 地理空间索引 (Geospatial Index): 支持地理位置数据(如点、线、多边形)的查询。
- TTL 索引 (Time-to-Live Index): 自动删除特定时间后过期的文档。
什么是聚合框架(Aggregation Framework)?常用的聚合阶段有哪些?
- 定义: 聚合框架是 MongoDB 中进行数据处理和分析的强大工具。它允许你通过一系列的管道阶段 (Pipeline Stages) 来转换和组合文档,生成聚合结果。
- 常用阶段:
$match: 过滤文档,只将符合条件的文档传递到下一个阶段。$group: 按指定字段对文档进行分组,并对每个组执行聚合操作(如$sum,$avg,$count)。$project: 重构文档的形状,可以选择、排除或添加新字段。$sort: 对文档进行排序。$limit: 限制通过管道的文档数量。$skip: 跳过指定数量的文档。$unwind: 将文档中的数组字段“解构”,为数组中的每个元素生成一个单独的文档。$lookup: 执行左外连接,从另一个集合中获取关联文档。
MongoDB 如何保证数据一致性(特别是事务)?
- 原子性: MongoDB 的写入操作(如
insertOne(),updateOne())在单个文档级别是原子性的。 - 事务(MongoDB 4.0+): 从 MongoDB 4.0 开始,引入了多文档事务(Multi-Document Transactions)。这意味着你可以在多个文档、多个集合乃至多个分片上执行符合 ACID 的事务。
- 隔离级别: 通常提供快照隔离,确保事务期间的数据一致性。
- 限制: 相较于关系型数据库的事务,仍有一些限制(如性能开销、超时)。
- 副本集的一致性: 副本集通过 Oplog 复制实现最终一致性。你可以通过读偏好(Read Preference)和写关注(Write Concern)来调整一致性级别。
- 读偏好: 决定从主节点还是从节点读取数据(如
primary,primaryPreferred,secondary,secondaryPreferred,nearest)。 - 写关注: 决定写入操作成功需要多少个节点的确认(如
w:1写入主节点,w:majority写入多数节点)。
- 读偏好: 决定从主节点还是从节点读取数据(如
MongoDB 的缺点或局限性是什么?
- Join 操作: 虽然有
$lookup,但其功能和性能不如关系型数据库的 JOIN 强大和灵活。复杂的跨集合查询可能需要多次$lookup或在应用层处理。 - 事务复杂性: 4.0+ 虽引入了多文档事务,但相较于关系型数据库,仍有学习成本和性能考量。
- 模式缺失: 虽然是优势,但有时也可能导致数据混乱,需要应用层严格管理数据结构。
- 数据冗余: 为了查询性能,可能需要牺牲范式化,导致数据冗余。
- 内存使用: 有些操作(如排序、聚合)可能需要大量内存。
什么时候会选择 MongoDB 而不是关系型数据库?什么时候不选择?
- 选择 MongoDB 的场景:
- 数据结构不固定,需要灵活的模式(Schema-less)。
- 高并发写入和大数据量存储。
- 需要水平扩展来应对业务增长。
- 对读性能要求高,且数据关联性不复杂。
- 需要存储非结构化或半结构化数据(如日志、用户画像、IoT 数据)。
- 不选择 MongoDB 的场景:
- 需要复杂的、跨多表的 JOIN 查询。
- 需要强事务一致性,尤其是有复杂的、跨多文档的 ACID 事务。
- 严格的范式化数据结构。
- 传统的 OLTP 业务,数据模型稳定且关联复杂。
如何进行 MongoDB 的性能优化?
- 创建合适的索引: 根据查询模式创建单字段、复合、多键、文本等索引。
- 优化查询: 避免全表扫描,使用
$explain分析查询性能。 - 数据模型设计: 合理选择嵌入式文档或引用,避免深层嵌套。
- 读写分离: 利用副本集实现读写分离。
- 分片: 针对大规模数据和高并发场景。
- 硬件优化: 足够的内存(MongoDB 尽可能将数据放在内存中)、SSD 硬盘。
- 聚合管道优化: 将
$match放在管道前面尽可能过滤数据。
嵌入式文档与lookup操作
嵌入式文档是指一个文档内部包含另一个文档(或多个文档)。这意味着相关的子数据直接存储在父文档中,而不是作为单独的文档存储在另一个集合中并通过引用关联。
$lookup 是 MongoDB 聚合管道(Aggregation Pipeline)中的一个阶段,它允许你执行左外连接(Left Outer Join),从一个集合中的文档获取相关数据,并将其合并到另一个集合的文档中。
面试时,面试官通常会考察你如何根据业务场景和数据访问模式来选择嵌入式文档或引用加 $lookup。
- 数据的关联性/紧密性:
- 如果数据是强关联且总是被一起访问(例如,用户的地址和用户一起读取),优先考虑嵌入式文档。
- 如果数据是弱关联,或者不总是被一起访问(例如,订单中的商品详情,用户可能只看订单列表不看详情),考虑引用 +
$lookup。
- 读写模式:
- 读多写少,且一起读: 嵌入式文档通常性能更优。
- 写入频繁,且子文档会被重复引用: 引用 +
$lookup可以减少数据冗余和更新复杂性。
- 数据大小和增长:
- 如果嵌入的子文档会变得非常大或者数量无限增长(接近 16MB 限制),使用引用 +
$lookup。 - 如果子文档相对较小且数量有限,可以考虑嵌入式文档。
- 如果嵌入的子文档会变得非常大或者数量无限增长(接近 16MB 限制),使用引用 +
- 一致性和原子性要求:
- 对强一致性要求高且需要原子操作的内部数据,嵌入式文档更安全。
- 涉及到多个集合的关联数据,通常需要应用层或 MongoDB 4.0+ 的多文档事务来保证一致性(如果使用引用)。
- 业务逻辑复杂性:
- 简单的聚合或联接,
$lookup也可以接受。 - 非常复杂的联接或需要跨集合的多次查询,可能需要重新评估数据模型或考虑将部分处理逻辑放到应用层。
- 简单的聚合或联接,
Elastic Search
Elasticsearch 是一个基于 Apache Lucene 的分布式、RESTful 风格的搜索和分析引擎。它以其速度快、可伸缩性强以及能够处理海量数据而闻名。在面试中,Elasticsearch 经常作为大数据、搜索或微服务架构中的关键组件被问到。
ELK Stack (Elasticsearch, Logstash, Kibana) 技术栈核心
关键概念

节点
一个 Elasticsearch 实例就是一个节点。每个节点都有一个名称。
主要节点类型:
- Master Node (主节点):负责集群的管理任务,如创建/删除索引、跟踪节点状态、分片分配等。一个集群中只能有一个主节点,但可以有多个符合主节点条件的节点(master-eligible node)。
- Data Node (数据节点):存储数据(分片)并执行数据相关操作(CRUD、搜索、聚合)。
- Ingest Node (摄入节点):执行预处理管道,转换文档。
- Coordinating Node (协调节点):默认所有节点都是协调节点,负责接收客户端请求,将请求路由到正确的数据节点,并汇集各数据节点的结果返回给客户端。
Cluster (集群)
- 一个集群由一个或多个节点 (Node) 组成,它们共同存储数据并提供索引和搜索能力。
- 目的: 提供高可用性、可伸缩性和容错性。
- 面试点: 知道集群如何协同工作,以及其分布式特性。
Document (文档)
- 类似关系数据库中的行 (row)。它是可被索引的最小单位。
- JSON 格式: 文档以 JSON (JavaScript Object Notation) 格式表示。
- 唯一 ID: 每个文档在它所属的索引中都有一个唯一的 ID。
- 面试点: 理解文档是 Elasticsearch 存储和搜索的原子单元。
Index (索引)
- 类似关系数据库中的数据库 (database)。它是拥有相似特性的文档的集合。
- 逻辑概念: 一个索引实际上在物理上分布在多个分片 (Shard) 上。
- 面试点: 理解索引是逻辑上的分组,是可搜索的最高层级。
Type (类型) - 在 Elasticsearch 7.x 及更高版本中已废弃!
- 在 6.x 及以前版本中,一个索引可以包含多个类型,类似关系数据库中的表 (table)。
- 面试点: 强调它已被废弃,并解释原因(Mapping 冲突、性能问题)。对于 7.x+ 版本,一个索引通常只对应一个类型或根本没有显式类型。
Field (字段)
- 类似关系数据库中的列 (column)。文档由多个字段组成。
- 面试点: 字段是文档中的基本数据单元
Mapping (映射)
- 类似关系数据库中的表结构 (schema)。它定义了文档及其字段的类型、如何存储以及如何被索引。
- 动态映射: Elasticsearch 默认支持动态映射,即当你索引一个新文档时,如果其中包含新的字段,Elasticsearch 会尝试猜测其数据类型并自动创建映射。
- 显式映射: 最佳实践是显式定义映射,特别是对于文本字段,以控制它们的分析方式。
- 面试点: 理解 Mapping 的作用,以及动态映射和显式映射的区别。
keyword和text类型字段的区别是高频考点。text类型: 用于全文本字段,会被分词器处理(例如,”Hello World” 可能被分成 “hello” 和 “world”)。可用于全文搜索。keyword类型: 用于结构化数据(如 ID、标签、国家代码),不会被分词。适用于过滤、聚合、排序。
Shard (分片)
- 物理存储单元: 一个索引的数据被分成多个分片。每个分片都是一个独立的 Lucene 索引。
- 目的:
- 横向扩展: 允许你水平扩展存储容量和吞吐量。
- 并行处理: 允许在多个节点上并行执行搜索和聚合操作,提高性能。
- 主分片 (Primary Shard): 存储原始数据。
- 副本分片 (Replica Shard): 主分片的副本,用于提供高可用性(当主分片失效时可以提升为新主分片)和提升搜索吞吐量。
- 面试点: 高频考点。理解分片是 Elasticsearch 可伸缩和高可用的基石。区分主分片和副本分片的作用,以及它们如何分布在集群中
Replicas (副本)
- 作用: 副本分片是主分片的精确拷贝。
- 目的:
- 高可用性: 当某个节点上的主分片失败时,副本可以立即提升为新的主分片,确保数据不丢失和服务的连续性。
- 提高查询性能: 搜索请求可以同时在主分片和其副本分片上执行,分散负载,提高吞吐量。
- 面试点: 理解副本如何保障高可用和提升查询性能,以及副本数量的设置对存储和查询性能的影响。
Analysers (分析器)
- 作用: 在索引文本数据时,将原始文本转换为可搜索的词项 (terms) 的过程。
- 组成: 由一个字符过滤器 (character filters)、一个分词器 (tokenizer) 和零个或多个词项过滤器 (token filters) 组成。
- 面试点: 理解分析器在全文搜索中的重要性。常见的分析器如
standard分析器。能解释分词(tokenization)和词项过滤(如小写转换、停用词移除、同义词处理)的概念。
Query DSL (查询领域特定语言)
- Elasticsearch 强大的查询语言,基于 JSON。
- 面试点: 知道如何使用 Query DSL 进行各种复杂的搜索,如全文搜索、词语匹配、范围查询、布尔组合查询等。
Aggregations (聚合)
- Elasticsearch 强大的统计分析功能。允许你从数据中提取和计算出复杂的统计信息,例如分组、求和、平均值、最大/最小值等。
- 面试点: 了解聚合的用途,例如用于仪表盘、统计报表等。
关键问题
什么是 Elasticsearch?它的核心特点是什么?
- 定义: Elasticsearch 是一个基于 Apache Lucene 的分布式、RESTful 风格的搜索和分析引擎。
- 核心特点:
- 分布式: 能够横向扩展,处理海量数据。
- 近实时(Near Real-time): 数据从索引到可搜索只有毫秒级的延迟。
- 高可用和可伸缩: 通过集群、分片和副本机制提供。
- RESTful API: 通过 HTTP 和 JSON 进行交互,易于使用。
- 全文搜索: 强大的全文搜索能力,支持复杂查询。
- 聚合分析: 强大的聚合功能,用于数据分析和报表。
请解释 Elasticsearch 中的集群(Cluster)、节点(Node)、索引(Index)、类型(Type - 已废弃)、文档(Document)和字段(Field)之间的关系和作用。
- 集群 (Cluster): 一个或多个节点的集合,共同存储数据并提供搜索和分析功能。是 Elasticsearch 的最高逻辑单位。
- 节点 (Node): 一个 Elasticsearch 实例。每个节点在集群中扮演不同角色(如 Master 节点、Data 节点、Ingest 节点、Coordinating 节点)。
- 索引 (Index): 逻辑上相关文档的集合,类似关系型数据库的数据库。物理上,一个索引由一个或多个分片 (Shard) 组成。
- 类型 (Type): 在 Elasticsearch 7.x 及更高版本中已废弃! 在 6.x 及以前版本中,类型是索引下的逻辑分组,类似关系型数据库的表。面试时务必强调其已废弃。
- 文档 (Document): 可被索引的最小数据单元,以 JSON 格式表示,类似关系型数据库的行。每个文档都有一个唯一的 ID。
- 字段 (Field): 文档中的数据单元,类似关系型数据库的列。
Elasticsearch 中的分片(Shard)和副本(Replica)有什么作用?它们如何实现高可用和可伸缩?
- 分片 (Shard):
- 作用: 是一个索引的物理存储单元,一个 Lucene 索引。一个索引被分成多个分片,这些分片可以分布在集群的不同节点上。
- 目的: 实现横向扩展(存储容量和吞吐量),并支持并行处理查询。
- 副本 (Replica):
- 作用: 是主分片的一个完整副本。
- 目的: 实现高可用性(当主分片所在的节点故障时,副本可以提升为新的主分片,防止数据丢失和中断服务)和提高查询吞吐量(搜索请求可以在主分片和副本上并行执行,分摊负载)。
- 高可用和可伸缩:
- 高可用: 通过副本机制,即使部分节点或分片失效,数据仍然可用,服务不会中断。
- 可伸缩性: 通过增加分片数量和节点数量,可以将数据和查询负载分布到更多机器上,实现线性扩展。
什么是倒排索引(Inverted Index)?Elasticsearch 为什么用它?
- 定义: 倒排索引是 Elasticsearch 实现快速全文搜索的核心数据结构。
- 传统数据库的“正向索引”是从文档(行)到关键词(列)。
- 倒排索引则是从关键词 (Term) 到包含该关键词的文档 ID 列表。
- 示例:
- 文档1: “The quick brown fox”
- 文档2: “Quick foxes are quick”
- 倒排索引:
the: [文档1]quick: [文档1, 文档2]brown: [文档1]fox: [文档1]foxes: [文档2]are: [文档2]
- 为什么用它:
- 极快的全文搜索: 当你搜索一个或多个关键词时,可以直接在倒排索引中找到包含这些关键词的所有文档 ID,而无需扫描所有文档。
- 高效过滤和聚合: 也是实现高效过滤和聚合的基础。
Elasticsearch 中的 Mapping(映射)是什么?text 类型和 keyword 类型有什么区别?
- Mapping 定义: Mapping 类似于关系型数据库中的表结构(Schema)。它定义了文档及其字段的数据类型、如何存储以及如何被索引和查询。
- 作用: 控制字段如何被分析(分词)、如何被索引以及是否可以被搜索、聚合和排序。
text类型 vskeyword类型: 这是最常考的区别!text类型:- 用于全文文本字段,例如文章内容、产品描述。
- 在索引时会被分词器 (Analyzer) 处理,将文本分解为独立的词项 (Terms)。
- 适用于全文搜索(例如,搜索 “quick brown fox”,即使只搜 “quick” 也能找到)。
- 不适用于精确匹配、排序或聚合(因为已经被分词)。
keyword类型:- 用于精确值的字段,例如 ID、邮箱地址、标签、国家代码。
- 不会被分词器处理,整个值被视为一个单一的词项。
- 适用于精确匹配、过滤、排序和聚合。
- 不适用于全文搜索。
- 面试重点: 能够清晰解释这两种类型的区别和适用场景。例如,一个商品标题字段,可能同时需要
text类型用于搜索,keyword类型用于精确过滤或聚合。
什么是分析器(Analyzer)?它由哪些部分组成?
- 定义: 分析器是 Elasticsearch 在索引和搜索文本数据时,将原始文本转换为可搜索的词项 (Terms) 的过程。
- 组成: 一个分析器由以下三部分组成:
- 字符过滤器 (Character Filters): 在文本被分词前,进行预处理,例如移除 HTML 标签、替换特殊字符。
- 分词器 (Tokenizer): 将文本分解为独立的词项(tokens)。例如,
standard分词器按空格和标点符号分词。 - 词项过滤器 (Token Filters): 对分词器生成的词项进行进一步处理,例如转换为小写、移除停用词 (stop words)、添加同义词、词干提取等。
- 面试重点: 理解分析器在全文搜索中的核心作用,以及其三部分的职能。例如,搜索“Running Shoes”,分析器可能将其处理成“run”、“shoe”,这样搜索“run”也能找到。
Elasticsearch 的写入(索引)流程是怎样的?
- 客户端发送写入请求(
PUT或POST文档)到集群中的任一节点(通常是协调节点)。 - 协调节点根据文档的 ID 和索引的路由规则计算出该文档应属于的主分片。
- 协调节点将请求转发到主分片所在的 Data 节点。
- 主分片所在节点将文档写入主分片,并将其写入事务日志 (Translog)。
- 主分片将请求并行转发到所有副本分片所在的 Data 节点。
- 副本分片所在节点将文档写入副本分片,并写入其自己的 Translog。
- 所有副本分片成功写入后,向主分片返回确认。
- 主分片收到所有副本确认后,向协调节点返回确认。
- 协调节点向客户端返回成功响应。
面试重点: 强调写入操作首先在主分片上进行,然后同步到副本分片,并涉及 Translog 的持久化来保证数据安全性。
Elasticsearch 的查询(搜索)流程是怎样的?
- 客户端发送搜索请求到集群中的任一节点(协调节点)。
- 协调节点将请求广播到索引的所有主分片和副本分片(协调节点会随机选择一个分片来处理请求,通常是主分片或其一个副本)。
- 每个分片执行搜索请求的两个阶段:
- Query Phase (查询阶段 / Scatter): 每个分片执行查询,找到匹配的文档,并返回文档 ID 和得分(Score)到协调节点。
- Fetch Phase (取回阶段 / Gather): 协调节点将所有分片返回的文档 ID 和得分进行合并、排序,选出最终需要的文档 ID。然后,协调节点再次向相应分片请求这些完整文档的内容。
- 协调节点收集所有完整文档,并根据排序要求返回给客户端。
面试重点: 强调查询是“分而治之”的思想,分为查询和取回两个阶段,涉及协调节点的分发和结果聚合。
如何保证 Elasticsearch 的数据一致性?
- 写关注 (Write Consistency): 在写入操作时,可以通过
replication参数设置写关注:quorum(默认):需要主分片和大多数副本分片写入成功才返回。one:只需主分片写入成功。all:所有分片(主分片和所有副本分片)写入成功。- 面试重点: 了解不同的写关注级别对写入性能和数据安全性的影响。
- Translog (事务日志): 每个分片都有一个 Translog,所有操作在被 Lucene 写入磁盘前都会先写入 Translog,确保即使发生宕机,也能从 Translog 恢复未持久化的操作。
- 刷新 (Refresh) 和提交 (Commit):
- Refresh (刷新): Translog 中的数据会定期刷新到 Lucene 的文件系统缓存中,此时数据变得可搜索(默认 1 秒刷新一次)。
- Commit (提交): Lucene 会定期进行 fsync 操作,将数据持久化到磁盘。
- 最终一致性: Elasticsearch 追求的是最终一致性。这意味着写入数据后,可能在极短的时间内(通常是 Refresh 间隔)无法立即被搜索到,但最终会达到一致状态。
常见的 Elasticsearch 性能优化策略有哪些?
- 索引优化:
- 合理设计 Mapping: 选择正确的数据类型(尤其是
textvskeyword),避免不必要的字段索引("index": false)。 - 分片数量: 合理设置主分片数量,通常建议一个分片大小在 20GB-50GB 左右。过多的分片会增加管理开销,过少则限制扩展性。
- 副本数量: 增加副本可以提高读吞吐量和高可用性,但会增加写入开销和存储成本。
- 合理设计 Mapping: 选择正确的数据类型(尤其是
- 查询优化:
- 使用合适的查询类型: 优先使用
term、match等简单查询,避免复杂的正则或通配符查询。 - 避免深分页: 使用
search_after或scrollAPI 代替from/size进行深分页。 - 缓存: 利用 Elasticsearch 的查询缓存和字段数据缓存。
- 聚合优化: 将
_source字段设置为false(如果不需要返回原始文档),只返回聚合结果。
- 使用合适的查询类型: 优先使用
- 硬件优化:
- 内存: 分配足够的 JVM 堆内存(通常是物理内存的一半,不超过 32GB)。
- SSD 硬盘: 对于 I/O 密集型操作至关重要。
- CPU: 足够的核数来处理查询和索引操作。
- JVM 优化: 合理配置 JVM 堆内存大小和垃圾回收器。
- 慢查询日志: 开启并分析慢查询日志,找出性能瓶颈。
Elasticsearch 集群可能遇到哪些问题?如何解决?
- 脑裂 (Split-Brain): 当网络分区时,集群可能分裂成多个子集群,每个子集群都选举出自己的 Master 节点,导致数据不一致。
- 解决方案: 配置
discovery.zen.minimum_master_nodes参数(投票节点数的一半加一),确保只有多数节点存活的子集群才能选举出 Master。
- 解决方案: 配置
- 集群健康状态 (Cluster Health):
- Red (红色): 至少一个主分片不可用,数据丢失或部分索引不可用,集群处于危险状态。
- Yellow (黄色): 所有主分片可用,但至少一个副本分片不可用。数据仍然完整,但冗余性降低,高可用性受损。
- Green (绿色): 所有主分片和副本分片都可用,集群健康。
- 面试重点: 能够解释不同颜色的含义和应对措施。
- 磁盘空间不足: 索引拒绝写入,集群可能变红。
- 解决方案: 增加磁盘空间、删除旧数据、使用索引生命周期管理 (ILM)。
- 内存溢出 / JVM 垃圾回收频繁: 导致节点无响应或重启。
- 解决方案: 合理配置 JVM 堆内存,优化查询和索引操作。
PostgreSql
PostgreSQL 是一款功能强大、高度稳定且遵循 SQL 标准的开源对象关系型数据库管理系统 (ORDBMS)。它以其高级特性、严格的 ACID 兼容性和出色的可扩展性而闻名,常被认为是比 MySQL 更适合处理复杂业务逻辑和数据一致性要求高的场景。
关键概念
以下是 PostgreSQL 的一些核心概念,理解它们是掌握 PostgreSQL 的基础:
对象关系型数据库 (ORDBMS)
- 定义: PostgreSQL 不仅仅是一个传统的关系型数据库 (RDBMS),它还是一个对象关系型数据库 (ORDBMS)。这意味着它融合了关系型数据库的优点和面向对象数据库的一些特性。
- 特点:
- 支持对象概念: 允许定义复杂的数据类型、函数重载和继承。
- 丰富的内置数据类型: 除了标准的关系型数据类型(如整数、字符串、日期)外,PostgreSQL 还原生支持许多高级数据类型,如 JSONB (二进制 JSON)、数组 (Arrays)、XML、几何数据类型、范围类型、网络地址等。
- 用户自定义类型: 你可以定义自己的数据类型和操作符,极大地扩展了数据库的功能。
- 重要性: 这是 PostgreSQL 与 MySQL 等纯 RDBMS 的一个显著区别,使其在处理半结构化数据、复杂业务逻辑和需要高度自定义的场景中更具优势。
索引 (Index)
- 作用: 索引是提高数据检索效率的数据库对象。通过创建索引,数据库可以快速定位到满足查询条件的行,而无需扫描整个表。
- 类型丰富: PostgreSQL 支持多种索引类型,包括:
- B-tree: 最常用,适用于各种等值查询和范围查询。
- Hash: 适用于等值查询(较少用,因为不能保证 Crash-safe)。
- GIN (Generalized Inverted Index): 适用于处理多值数据类型(如数组、JSONB)的包含查询。
- GiST (Generalized Search Tree): 适用于复杂数据类型(如几何数据、全文搜索)和范围查询。
- BRIN (Block Range Index): 适用于大型表,数据自然排序的场景,非常紧凑。
- 重要性: 合理地设计和使用索引是优化 PostgreSQL 查询性能的关键。
事务 (Transaction) 和 ACID
- 事务: 事务是一组逻辑上相关的数据库操作,它们被视为一个单一的、不可分割的工作单元。
- ACID 特性: PostgreSQL 严格遵守 ACID (Atomicity, Consistency, Isolation, Durability) 原则。
- 原子性 (Atomicity): 事务中的所有操作要么全部成功,要么全部失败回滚。
- 一致性 (Consistency): 事务完成后,数据库必须从一个一致状态转换到另一个一致状态。
- 隔离性 (Isolation): 并发执行的事务彼此独立,互不影响。
- 持久性 (Durability): 一旦事务提交,其所做的修改是永久性的,即使系统崩溃也不会丢失。
- 重要性: 严格的 ACID 兼容性是 PostgreSQL 可靠性和数据完整性的基石,尤其适用于金融、电商等对数据一致性要求极高的应用。
多版本并发控制 (MVCC)
- 定义: PostgreSQL 实现并发控制的关键机制是 MVCC (Multi-Version Concurrency Control)。
- 工作原理: 当一个事务修改数据时,PostgreSQL 不会直接覆盖旧数据,而是创建一个新的数据版本。读操作总是读取数据的旧版本,写操作则创建新版本。
- 优势:
- 读写不阻塞: 读操作和写操作通常不会相互阻塞,大大提高了并发性能。
- 快照隔离: 每个事务都有一个“快照”,看到的是事务开始时的数据状态,避免了脏读、不可重复读和幻读(取决于隔离级别)。
- 重要性: MVCC 是 PostgreSQL 在高并发读写场景下表现出色的核心原因之一,也是其与 MySQL 等数据库在并发处理上差异较大的地方。
