目前构建AI智能体应用的框架已经发展到了一定程度并基本趋于成熟.这篇文章尝试总结其中使用较多的框架并总结这些应用中常遇到的问题和对已经解决方案.
对于开发者来说,目前的常用大模型应用开源框架有langchain,autogen,llama-index等等.对应语言的框架有Spring的Langchain4j,Spring AI等.
可以从RAG,状态记忆与上下文管理,工具调用,智能体协作多个维度和技术难点分析这类应用的问题.
聊天记忆/上下文
隔离聊天记忆
持久化 MongoDB 无结构 方便存储
外部工具/方法调用
进行自然语言的订单,添加Tools
RAG
RAG方式
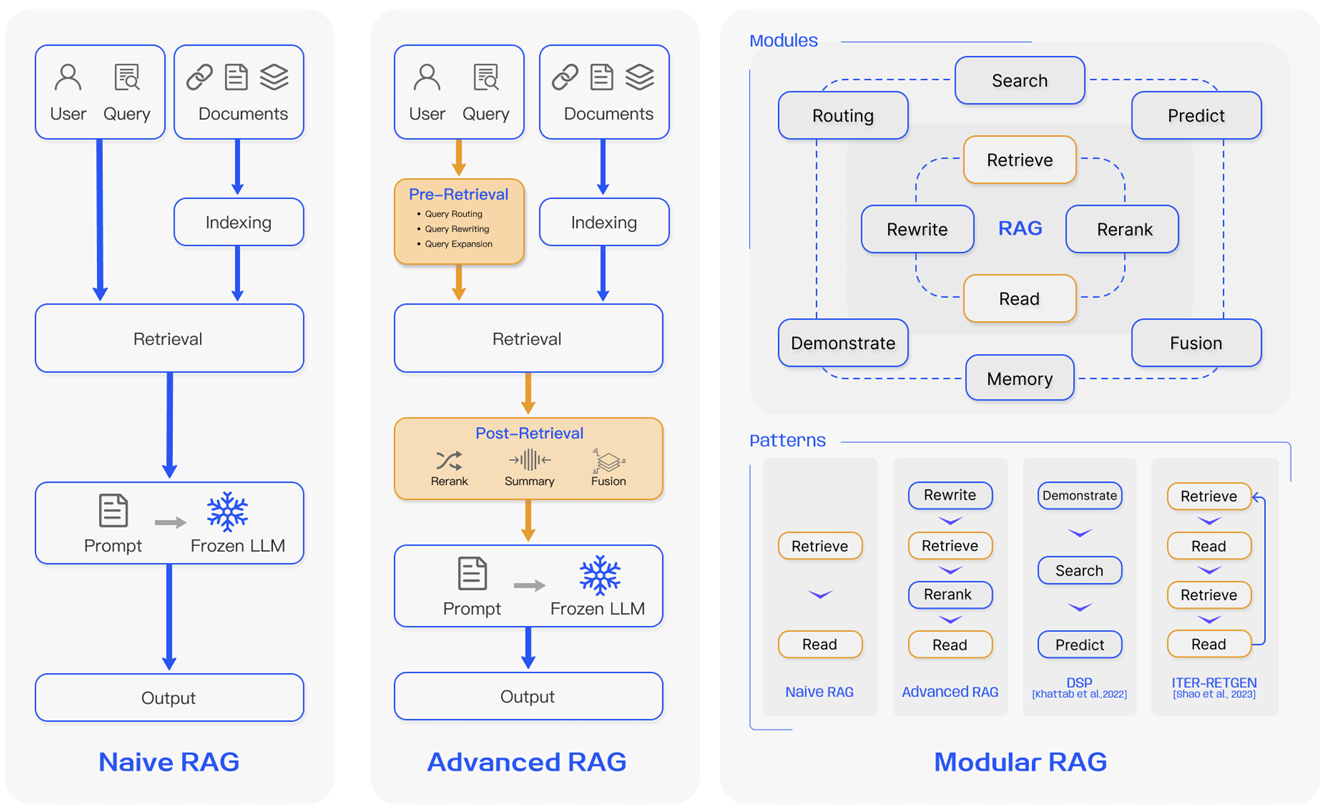
Naive RAG
遵循传统的索引、检索和生成过程。简而言之,用户输入被用来查询相关文档,这些文档随后与提示结合并传递给模型以生成最终响应。如果应用涉及多轮对话交互,可以将对话历史集成到提示中。
普通RAG存在一些限制,例如低精度(检索到的块不匹配)和低召回率(未能检索到所有相关块)。还有可能将过时的信息传递给LLM,这是RAG系统最初应该试图解决的问题之一。这导致幻觉问题和差劲且不准确的响应。
当应用增强时,也可能出现冗余和重复的问题。在使用多个检索到的段落时,排名和协调风格/语气也很关键。另一个挑战是确保生成任务不过度依赖增强信息,这可能导致模型只是重复检索到的内容。
缺点:
缺乏语义理解: 全文匹配依赖词汇匹配,无法捕获到query与文档之间的语义关联.
输出效果差: 缺乏对query、文档的高级预处理、后处理以及召回的文档容易包含过多或过少信息,导致生成的回答过于宽泛.
效果优化困难:过于依赖单一检索技术,未对query、文档进行增强,导致优化局限于检索技术.
Advanced RAG
高级RAG有助于解决普通RAG中存在的问题,例如提高检索质量,这可能涉及优化检索前、检索和检索后的过程。
检索前过程包括优化数据索引,旨在通过五个阶段提高索引数据的质量:增强数据粒度、优化索引结构、添加元数据、对齐优化和混合检索。
检索阶段可以通过优化嵌入模型本身来进一步改进,这直接影响构成上下文的块的质量。这可以通过微调嵌入以优化检索相关性或采用能够更好地捕捉上下文理解的动态嵌入(例如,OpenAI的embeddings-ada-02模型)来实现。
优化检索后过程主要关注避免上下文窗口限制和处理嘈杂或可能分散注意力的信息。解决这些问题的常见方法是通过重新排序,这可能涉及将相关上下文移至提示边缘或重新计算查询与相关文本块之间的语义相似度。提示压缩也可能有助于处理这些问题。
在检索前,增强文档质量,比如优化章节结构,增强标题,过滤低质量信息. 优化索引结构,优化chunk size,使得上下文粒度符合应用场景需求.对chunk进行提取增强. 对用户的query进行重写
在检索阶段,使用域内知识对embedding进行finetune,或者使用llm based-embedding模型,生成对上下文理解更准确的语义向量.
检索后阶段,增加rerank提交检索文档的相关性,增加context-compression使提供给模型的信息更加集中.
Modular RAG
模块化RAG增强了功能模块,例如整合搜索模块以进行相似性检索以及在检索器中应用微调。普通RAG和高级RAG都是模块化RAG的特殊情况,由固定模块组成。
扩展RAG模块包括搜索、记忆、融合、路由、预测和任务适配器,解决不同的问题。这些模块可以根据具体问题情境重新排列。因此,模块化RAG在多样性方面具有更大的优势,并且具有灵活性,可以根据任务需求添加或替换模块,或调整模块之间的流程。
鉴于构建RAG系统时的灵活性增加,已经提出了其他重要的优化技术来优化RAG流程,包括:
混合搜索探索:这种方法利用了基于关键词的搜索和语义搜索等搜索技术的组合,以检索相关且信息丰富的内容;这在处理不同查询类型和信息需求时非常有用。
递归检索和查询引擎:涉及一个递归检索过程,可能从小的语义块开始,随后检索更大的块以丰富上下文;这有助于平衡效率和上下文丰富的信息。
StepBack-prompt:一种提示技术,它使LLM能够执行抽象,产生指导和推理的概念和原则;当应用于RAG框架时,这会导致更好的基于事实的响应,因为LLM远离了特定实例,如果需要,可以更广泛地进行推理。
子查询:有不同查询策略,如树查询或块顺序查询,可用于不同场景。LlamaIndex提供了一个子问题查询引擎,它允许将查询分解为几个使用不同相关数据源的查询。
假设文档嵌入:HyDE为查询生成一个假设答案,将其嵌入,并使用它来检索与假设答案相似的文档,而不是直接使用查询。
1
2
3
4
5
6
7
8
9
10
11
12
13Query
↓
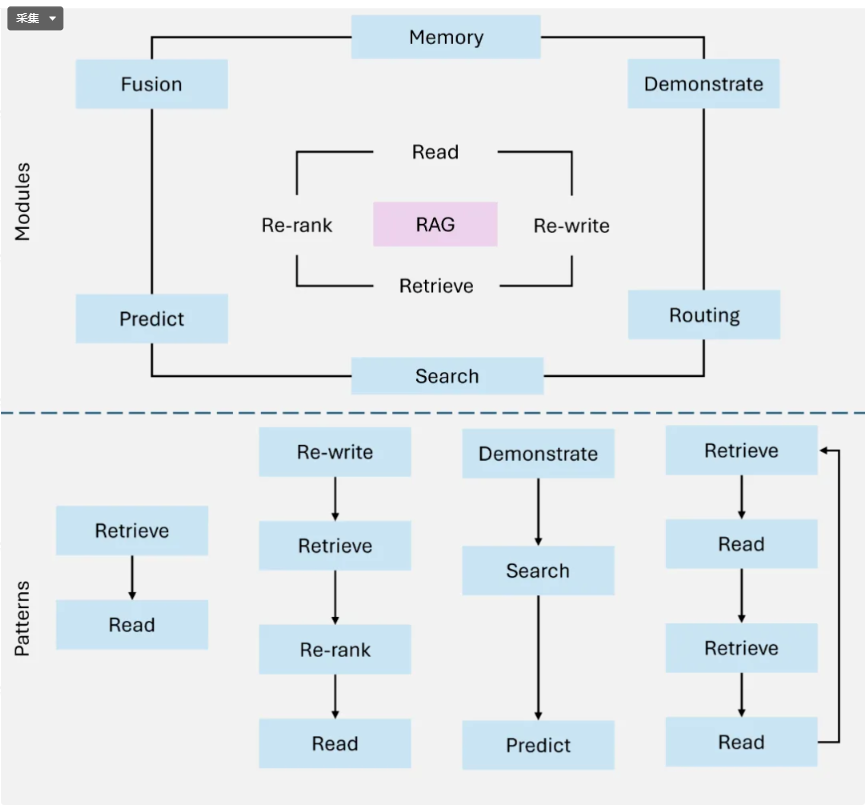
Routing → 决定检索策略 / 模型 /知识源
↓
Search → 初步检索候选文档
↓
Memory → 补充历史信息 / 相关上下文
↓
Fusion → 多源信息融合
↓
Predict → LLM生成答案 / 预测结果
↓
Task Adapter → 调整答案格式 / 输出符合任务要求
从 Naive RAG 到 Agentic RAG,技术演进的核心是 “从静态检索到动态决策”“从单一功能到多元适配”。选型时需结合业务需求、资源投入与技术储备综合判断:
若需快速验证概念,且知识规模小:优先选择 Naive RAG;
若需平衡精度与成本,处理中等复杂度问题:Advanced RAG 是性价比之选;
若需对接多源数据或频繁迭代模块:Modular RAG 的灵活性更适配;
若需处理高复杂度、多步推理任务,且资源充足:Agentic RAG 是长期方向。
未来,RAG 的发展将进一步向 “多模态融合”、“实时知识更新”、“轻量化部署” 方向演进,而模块化与 Agent 化的结合(如 Modular Agentic RAG)可能成为主流形态。掌握四大模式的核心差异,将为技术落地提供清晰的路径图
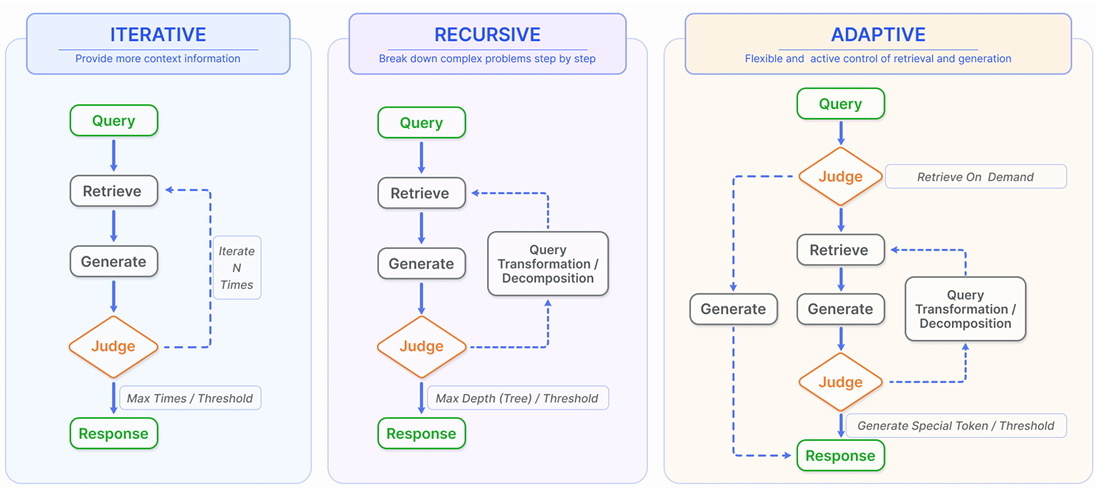
Graph RAG
使用图结构来扩展传统RAG系统,利用图关系和层级结构,增强multi-hop推理和context丰富度. Graph RAG生成的结果更丰富和更准确,特别是对于需要关系理解的任务
Graph RAG具备局限性:
高质量图数据依赖: 高质量的图数据对于Graph RAG非常关键,对于无结构的纯文本或者标注质量不高的数据
应用的复杂性:对于一个RAG系统,需要同时支持非结构化数据和图数据的混合检索,增加检索系统实现复杂性.
Multi-hop
Multi-hop 指的是在回答一个问题或生成答案时,模型需要跨多个信息片段、文档或知识源逐步推理,才能得到最终结果。
简单说:
- Single-hop(单跳):答案可以从单个文档或单条检索结果直接得到。
例:问 “东京的平均气温是多少?” → 可以直接从单篇气象报告得到答案。 - Multi-hop(多跳):答案需要从多个文档/信息点组合推理。
例:问 “A市到B市最快路线经过哪些城市?” → 需要先查 A 到 C,再查 C 到 B,再整合路线。
- 跨文档依赖:答案不能从单个文档直接得到,需要聚合多个文档信息。
- 逻辑推理链:需要模型跟踪中间步骤,类似 Chain-of-Thought。
- 复杂 query:通常涉及条件、约束、因果关系等。
- 更高的检索要求:Retriever 必须提供多条相关文档,而不是只靠 top-1。
| 技术点 | 作用 |
|---|---|
| 多轮检索(Iterative Retrieval) | 每一步检索为下一步提供上下文 |
| 中间答案缓存 / Memory | 保存前一步信息,支持跨步推理 |
| 路径评分 / Reranker | 对多跳检索结果按可信度排序 |
| Fusion 模块 | 将多文档多跳信息融合为 LLM 上下文 |
| Router / Task Adapter | 决定何时继续跳,何时生成答案 |
Multi-hop = 多步跨文档推理
核心挑战:需要追踪中间步骤,保证信息融合和逻辑一致性。
在 RAG 系统中,多跳常通过 迭代检索、推理链、图结构 或 HyDE假设文档 来实现。
Agentic RAG
Agentic RAG使用能够动态决策和工具调用的LLM-based的agent,来解决更复杂、实时和多域的查询.
Agentic RAG使用更多更复杂的工具来辅助检索,比如搜索引擎,计算器等各类以API形式能够直接访问的工具,另外可以根据时机的检索场景动态决策,比如决定是否进行检索,决定使用什么工具检索,评估检索到的上下文决定是否需要继续检索.
如何实现动态决策
实现动态决策的机制
- 基于规则(Rule-based Agent)
- 最早的方法,按 query 特征或关键词选择策略
- 缺点:难适应多领域、多任务
1 | if "法律" in query: |
- 基于分类模型(Classifier Agent)
- 训练一个轻量模型预测 query 类型或策略
- 输出可能是:
- 选择的知识源
- 是否多跳
- 检索策略类型
- 优点:可扩展、可学习
- 缺点:需要标注数据
- 基于 LLM 的智能决策(LLM Agent / Planner)
- 使用大模型本身来做决策,输入 query + context,让模型输出行动计划
- 形式示例:
1 | Query: 2025年东京的平均气温是多少? |
- 在 LangChain 中,可以用 LLMRouterChain / MultiRetrievalQAChain / AgentExecutor 实现
- 优点:策略可动态生成、可解释
- 缺点:成本高,需要 LLM 推理
- 基于强化学习 / Policy Learning(RL Agent)
- 将决策看作策略优化问题:
- 状态 = 当前 query + 已检索文档 + 历史上下文
- 动作 = 选择知识源、检索策略、生成策略
- 奖励 = 生成答案的准确率或用户反馈
- 可通过 RL 或 RLHF 训练策略网络,实现端到端的动态决策
1 | Query |
Router/Planner 可以是 规则、分类器或 LLM
Multi-hop 和 Fusion 模块执行动态决策后的操作
Task Adapter 根据任务要求调整输出格式或策略
分块策略
按行文档分割器
按句子、按单词、按字符文档分割器
Chunking 的目标:在保证语义完整性的前提下,将长文档切分成若干可检索的文本单元(chunks)。
🔹 关键矛盾:
- 太短 → 语义残缺,召回不准
- 太长 → 嵌入模糊、检索成本高、上下文浪费
常见的分块策略分类
固定长度分块(Fixed-size Chunking)
最基础、最常见的做法。
| 特征 | 说明 |
|---|---|
| 策略 | 按字数/Token数固定长度切分,如每500 token 一块 |
| 优点 | 实现简单、速度快 |
| 缺点 | 可能破坏语义边界(句子或段落被截断) |
| 常用参数 | chunk_size=500~1000 tokens, overlap=100~200 tokens |
👉 常用于:新闻、论文等较规则文本。
滑动窗口分块(Sliding Window Chunking)
| 特征 | 说明 |
|---|---|
| 策略 | 每次移动窗口产生重叠块,例如窗口大小1000,滑动步长500 |
| 优点 | 保留上下文连续性,减少语义断裂 |
| 缺点 | 重复嵌入,存储量大约增加1.5~2倍 |
👉 常用于:长文本、问答型知识文档。
语义分块(Semantic / Sentence-aware Chunking)
| 特征 | 说明 |
|---|---|
| 策略 | 利用自然语言分句或语义相似度聚合,如句向量相似度阈值分组 |
| 优点 | 按语义边界切分,减少跨句割裂 |
| 缺点 | 需要额外计算(NLP或Embedding模型) |
| 常用方法 | spaCy句法切分、BERT句嵌入聚类、SimCSE相似度聚合 |
👉 适合:学术文档、法律条款、技术文档。
结构感知分块(Structure-aware Chunking)
| 特征 | 说明 |
|---|---|
| 策略 | 利用文档结构(如Markdown层级、HTML标签、PDF目录)分块 |
| 优点 | 保留逻辑层级(标题+段落)信息,检索更精准 |
| 缺点 | 不同文档结构需不同解析器 |
| 常用方法 | 按标题层级聚合段落(H1→H2→p);PDF 解析后按章节组织 |
👉 适合:报告、网页、企业知识文档。
动态语义合并(Adaptive Chunking)
| 特征 | 说明 |
|---|---|
| 策略 | 基于Embedding相似度或模型评分动态决定chunk大小 |
| 优点 | 自适应内容密度(密集部分小块,稀疏部分大块) |
| 缺点 | 实现复杂,计算成本高 |
| 典型方法 | Cohere / OpenAI Adaptive Chunking 实验功能;Sentence-BERT聚类分块 |
👉 适合:多主题长文档或知识图谱型内容。
层次化分块(Hierarchical Chunking)
| 特征 | 说明 |
|---|---|
| 策略 | 先按大章节分,再在章节内小块切分 |
| 优点 | 检索时可先 coarse-grained 检索章节,再 fine-grained 检索段落 |
| 缺点 | 检索逻辑复杂 |
| 常见方案 | multi-stage RAG / hierarchical RAG(如 LlamaIndex TreeIndex) |
👉 适合:书籍、长报告、代码库。
基于语篇或主题边界(Discourse / Topic Chunking)
| 特征 | 说明 |
|---|---|
| 策略 | 利用主题模型(LDA / BERTopic)或语篇分析确定边界 |
| 优点 | 语义连贯性强、召回更准 |
| 缺点 | 模型依赖强,主题分布可能不稳定 |
👉 用于:科研论文集合、政策文件、知识图谱构建。
三、业界成熟方案 / 工具支持
| 工具 / 框架 | 分块策略支持 | 特点 |
|---|---|---|
LangChain (RecursiveCharacterTextSplitter, MarkdownHeaderTextSplitter, SpacyTextSplitter) | 固定/递归/结构化分块 | 易用、生态成熟 |
LlamaIndex (SentenceSplitter, SemanticSplitterNodeParser, HierarchicalNodeParser) | 语义+层次化 | 可组合策略,支持自适应chunking |
Haystack (PreProcessor) | 固定+重叠分块 | 可配置参数:split_length, split_overlap, split_by |
| Unstructured.io | 结构化分块 | 支持PDF、Docx、HTML等解析 |
| Cohere Embed API | 自适应语义分块(Adaptive Chunking) | 自动检测语义边界 |
| OpenAI text-embedding-utils | Token-aware分块 | 提供按模型上下文限制动态切割 |
四、不同策略的性能影响(对召回与生成)
| 策略类型 | 召回率 | 精确度 | 上下文完整性 | 成本 |
|---|---|---|---|---|
| 固定长度 | 中 | 中 | 低 | 低 |
| 滑动窗口 | 高 | 中 | 中 | 中 |
| 语义分块 | 高 | 高 | 高 | 中高 |
| 结构感知 | 高 | 高 | 高 | 中 |
| 动态分块 | 高 | 高 | 高 | 高 |
| 层次化分块 | 高 | 高 | 高 | 高 |
五、实践中的调优建议
| 场景 | 推荐分块策略 | 参数建议 |
|---|---|---|
| FAQ / 短文档 | 固定长度 | chunk=300~500, overlap=100 |
| 技术文档 / 法律条款 | 语义分块 + 结构感知 | 句级语义分组;按标题聚合 |
| 长论文 / 书籍 | 层次化分块 | Chapter→Section→Paragraph |
| 企业知识库(多主题) | 动态分块 / 语义聚类 | 相似度阈值0.75~0.85 |
| 高精检索任务 | 滑动窗口 + Reranker | chunk=800, overlap=200 |
六、额外技巧:Chunking + Reranking + Context Filtering
现代 RAG 系统常采用多阶段策略:1
2
3Chunking → Embedding → 初筛检索(top-20)
→ Cross-encoder reranking → 精筛(top-5)
→ 生成
或引入 Context Filtering / Contextual Compression:
- 对检索结果再压缩(如LlamaIndex的 Context Compressor)
- 仅保留与query最相关句子,提高上下文利用率
总结
| 方向 | 典型策略 | 代表框架 |
|---|---|---|
| 按长度 | 固定、滑动 | LangChain, Haystack |
| 按语义 | 语义/动态分块 | LlamaIndex, Cohere |
| 按结构 | Markdown/PDF层级 | Unstructured.io |
| 按层次 | Hierarchical RAG | LlamaIndex TreeIndex |
| 自适应智能化 | Adaptive/Topic-based | Cohere Adaptive, BERTopic |
RAG 分块的核心目的是让每个 chunk 信息完整又不过长,同时避免语义断裂。
目前常见的几类分块策略如下:
| 策略类型 | 特点 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 🧱 固定长度分块 (Fixed-size Chunk) | 固定 token 数(如512)分割 | 通用文本、快速实验 | 实现简单 | 容易切断语义 |
| 🪜 滑动窗口 (Sliding Window) | 每块之间有重叠 | 技术文档、代码 | 语义连续性强 | 存储开销大 |
| 🧠 语义分块 (Semantic Chunking) | 通过语义相似度或句法边界切分 | 非结构化长文 | 高质量语义单元 | 成本较高(需Embedding + 聚类) |
| 📚 主题/章节分块 (Topic-aware) | 按段落、标题或主题聚类 | 报告、论文、书籍 | 上下文一致 | 对格式依赖强 |
| 🗣 语篇/对话边界分块 (Discourse-aware) | 根据对话轮次或语义流切分 | 对话、会议摘要 | 保留语境 | 实现复杂 |
| 🧩 动态分块 (Dynamic Chunking) | 根据查询动态裁剪chunk | Query-sensitive RAG | 精准检索 | 实时计算成本高 |
第一阶段(MVP):固定长度 + 100 token overlap
第二阶段(优化):基于 semantic similarity 或 topic boundary 分块
高级阶段:引入动态分块,如 Dynamic Context Pruning 或 Query-aware Chunking(LangChain、LlamaIndex 都支持)
Embedding
分词器
分词器的任务是:把自然语言(文本)转成模型可处理的 token 序列(整数 ID)
| 算法类型 | 原理 | 优点 | 缺点 | 代表实现 |
|---|---|---|---|---|
| Word-level | 按单词分割 | 语义直观 | 词表太大(百万级) | 早期模型,如 word2vec |
| Subword-level | 按词根+子词分割 | 兼顾词表与语义 | 仍需人工训练词表 | BPE、SentencePiece |
| Character-level | 按字符分割 | 通用性强 | 序列太长 | 中文 NLP 常见 |
| Byte-level / Unigram | 按字节或概率最优子词 | 兼容多语言、表情符号 | 编码复杂 | GPT 系列、LLaMA 系列使用 |
| 分词器 | 主要算法 | 典型模型 | 特点 |
|---|---|---|---|
GPT Tokenizer (tiktoken) | Byte Pair Encoding (BPE) | GPT-3, GPT-4, GPT-4o | 高效、多语言支持、可数token |
| SentencePiece | Unigram / BPE | T5, Flan-T5, LLaMA, Mistral | 谷歌开发,跨语言标准方案 |
| BERT Tokenizer | WordPiece | BERT, RoBERTa | 英文任务最常见 |
| Claude Tokenizer | Custom BPE | Anthropic Claude 系列 | 类似GPT,优化多语言分词 |
| ChatGLM Tokenizer | SentencePiece (中英混合优化) | ChatGLM, ChatGLM2, GLM4 | 专为中英混合场景设计 |
| Baichuan Tokenizer | SentencePiece + 特殊token表 | Baichuan, Qwen | 兼容中英文及符号 |
| Jieba / HanLP | 中文词级分词 | 中文传统NLP | 不用于LLM,但适合前处理 |
大模型
开源大模型
| 模型 | 开发机构 | 参数规模 | 特点 | 常见用途 |
|---|---|---|---|---|
| LLaMA / LLaMA2 / LLaMA3 | Meta | 7B / 13B / 70B | 多语言强、生态成熟 | 通用对话、RAG |
| Mistral / Mixtral | Mistral AI | 7B / MoE (12x7B) | 高效、可商用 | 本地问答、RAG |
| Falcon | TII | 7B / 40B | 性能强,社区稳定 | 研究用 |
| Qwen / Qwen2 | 阿里 | 1.8B - 72B | 中文理解强 | 中文知识问答 |
| Baichuan2 | 百川智能 | 7B / 13B | 中文/中英混合 | RAG、知识库 |
| ChatGLM / GLM4 | 清华&智谱 | 6B / 9B | 中文最强之一 | 中文助手、RAG |
| Yi-1.5 / Yi-Large | 零一万物 | 6B / 34B | 中文生成优 | 企业知识问答 |
| Phi-3 | Microsoft | 3.8B / 14B | 小模型强性能 | 边缘端RAG |
| MPT / Dolly | Databricks | 7B / 12B | 可商业部署 | 企业内部问答 |
这些模型大多使用 SentencePiece 分词。
闭源商用模型
| 模型 | 公司 | 特点 | 是否RAG适配 |
|---|---|---|---|
| GPT-4 / GPT-4o / GPT-4-turbo | OpenAI | 最强通用能力、多模态 | ✅ |
| Claude 3 系列 | Anthropic | 强推理与对话一致性 | ✅ |
| Gemini 1.5 系列 | 多模态、超长上下文(百万token) | ✅ | |
| Command R+ / R+ v2 | Cohere | 专为RAG优化的模型 | ✅ |
| Mistral Large | Mistral | 开源+商用混合策略 | ✅ |
| Moonshot / Kimi / 通义千问-API版 | 中国厂商 | 中文优化、企业集成强 | ✅ |
检索算法
检索算法有哪些
常见类别:
| 类型 | 原理 | 优点 | 缺点 | 框架支持 |
|---|---|---|---|---|
| 🎯 Sparse(稀疏)检索 | TF-IDF / BM25 | 传统、快 | 不捕捉语义 | Haystack, ElasticSearch |
| 🌌 Dense(稠密)检索 | 向量相似度(Embedding) | 语义检索强 | 需训练/Embedding计算 | FAISS, Milvus, Pinecone |
| 🧠 Hybrid(混合)检索 | BM25 + Dense融合 | 折中方案 | 需融合策略 | LangChain, Weaviate |
| 🔁 Cross-encoder Rerank | 二阶段 rerank 模型 | 高精度 | 延迟高 | Cohere Rerank, HuggingFace |
| 🌐 Multi-hop Retrieval | 连续多轮检索 | 支持推理链 | 复杂实现 | Self-RAG, GraphRAG |
| 🕸 Graph-based Retrieval | 知识图谱关联节点 | 强逻辑语义 | 构建成本高 | GraphRAG, Neo4j |
| 🧭 Router-based Retrieval | 根据查询类型选择检索器 | 灵活、智能 | 路由模型复杂 | Agentic RAG |
| 内容类型 | 推荐分块 | 推荐检索算法 | 说明 |
|---|---|---|---|
| FAQ / 短问答 | 固定长度 + overlap | Sparse + Dense Hybrid | 高速高召回 |
| 技术文档 / API | 语义分块 + 滑动窗口 | Dense + Rerank | 精准匹配上下文 |
| 学术论文 / 报告 | 主题分块 | Dense + GraphRAG | 结构化层次检索 |
| 聊天记录 / 对话 | 语篇分块 | Dense + Memory-based | 语境一致 |
| 复杂推理任务 | 动态分块 | Multi-hop Dense | 支持链式推理 |
| 企业知识库 | 主题 + 动态分块 | Hybrid + Router | 性能与成本平衡 |
评估指标 如何评价
通过 RAG 评估框架(如 RAGAS、DeepEval) 验证效果。
关键指标包括:
| 指标 | 说明 |
|---|---|
| Context Precision / Recall | 检索文档是否相关 |
| Faithfulness | 回答是否忠实于检索内容 |
| Answer Relevance | 回答与问题匹配度 |
| Latency / Cost | 实时性能 |
| Context Utilization | 模型实际引用多少检索信息 |
建议:先固定检索算法,调分块;再固定分块,调检索。
改进思路(实践经验)
- 检索前增强(Query Rewriting / HyDE):
优化查询,提高检索相关性。
👉 用 “hypothetical answer” 或 “semantic expansion” 技术。 - 检索后过滤(Rerank / Context Pruning):
对召回结果二次排序,保留最高质量的段落。 - 动态决策(Router / Agentic RAG):
不同问题用不同分块/检索器(例如技术问答 vs 概念定义)。 - 融合多模态检索:
对图片、表格、代码等特殊内容单独建索引。
| 阶段 | 推荐策略 |
|---|---|
| MVP 阶段 | 固定分块 + Dense 检索(FAISS) |
| 提升精度 | 语义分块 + Hybrid 检索 + Rerank |
| 智能化 | 动态分块 + Multi-hop 检索 + Router Agent |
| 企业级 | GraphRAG + Memory + Self-RAG(反思机制) |
Reranker
reranker(重排序模型) 是提升检索阶段质量的关键组件之一,它负责对“初步检索得到的候选文档”进行更精细的语义匹配评分,从而筛选出真正与查询最相关的内容。
根据输入形式与架构,常见 reranker 模型分为三类:
| 类型 | 典型架构 | 特点 |
|---|---|---|
| 1️⃣ 交叉编码器(Cross-Encoder) | [CLS] query [SEP] document 输入,整体编码 | 精度最高,直接学习语义匹配;但推理慢,计算量大(O(N)) |
| 2️⃣ 双塔模型(Bi-Encoder / Dual Encoder) | 分别编码 query 和 doc,再计算相似度 | 速度快,可提前向量化 doc,但匹配精度低于交叉模型 |
| 3️⃣ 混合模型(Hybrid / ColBERT类) | token 级交互,例如 ColBERT 用 token 向量最大相似度聚合 | 精度与效率折中,可高效索引且部分保留交互信息 |
一些在 RAG、搜索、问答场景中常用的 reranker 模型:
| 模型 | 类型 | 核心思想 / 特点 | 开源地址 |
|---|---|---|---|
| BM25 + Cross-Encoder | 经典组合 | 先用 BM25 粗检索,再用 Cross-Encoder 精排 | 传统 baseline |
| BERT-Reranker (MS MARCO) | Cross-Encoder | 在 MS MARCO 排序任务上 fine-tune 的 BERT 模型 | microsoft/MSMARCO-BERT |
| MiniLM-L-6-v2 / -L-12-v2 | Cross-Encoder | Hugging Face 提供的轻量高效版本,效果-速度平衡好 | sentence-transformers |
| MonoT5 / DuoT5 | Seq2Seq (T5系列) | 将排序任务表述为 “哪个文档更相关” 的生成问题 | castorini/monot5-base-msmarco |
| E5-Reranker / bge-reranker | Cross-Encoder | 针对中文/多语言优化的语义匹配 reranker | BAAI/bge-reranker-large |
| ColBERT / ColBERTv2 | Late Interaction | 每个 token 有 embedding,匹配时计算最大相似度后聚合 | stanfordnlp/ColBERT |
| RankT5 / RankGPT | LLM-based | 利用大语言模型生成文档相关性排序得分,适合 Agentic RAG | RankGPT论文 |
| Cohere Rerank API / OpenAI Rerank API | 商业API | 已 fine-tune 的大型 cross-encoder 模型,可直接集成 |
常用的评价指标与信息检索(IR)一致:
| 指标 | 含义 |
|---|---|
| MRR (Mean Reciprocal Rank) | 关注首个正确答案的位置 |
| NDCG@k (Normalized Discounted Cumulative Gain) | 按排名折减累积相关性,评估整体排序质量 |
| Recall@k / Precision@k | 衡量前 k 个候选中是否包含正确文档 |
| MAP (Mean Average Precision) | 平均精度,衡量多相关文档场景 |
| Latency / Throughput | 工程指标,尤其在大规模检索中很关键 |
通常有三种典型接入方式:
| 阶段 | 说明 | 代表实践 |
|---|---|---|
| 1️⃣ 检索后重排(Post-Retrieval Reranking) | 对初检索(BM25/向量)结果进行重排序 | LangChain rerank_documents 或 LlamaIndex Reranker Node |
| 2️⃣ 联合检索(Hybrid Retrieval + Rerank) | 融合语义检索和关键字检索后再 rerank | BM25 + dense + rerank |
| 3️⃣ 动态上下文过滤(Adaptive Reranking) | 利用 reranker 判断“信息是否足够”来决定是否检索更多 | 在 Advanced RAG / Agentic RAG 中常见(如 HyDE + Rerank + LLM verify) |
上下文压缩
在 RAG 中,通常流程是:1
Query → 检索器(Retriever) → 得到若干候选文档 → 输入给LLM
问题在于:
- 检索出的文档往往很多;
- 每个文档可能很长;
- 直接传入LLM容易超出上下文窗口,或成本太高。
于是,Context Compressor 就是在 “Retriever” 和 “LLM” 之间的一层“过滤/精简模块”,用于:
“在不丢失重要信息的前提下,压缩传给模型的上下文内容。
LlamaIndex 提供了多种压缩策略,核心思想是:
让模型或算法根据 query 语义重要性,挑选/总结/截取文档内容。
常见的几种方式:
| 类型 | 说明 | 示例 |
|---|---|---|
| LLM-based summarization compressor | 用语言模型生成摘要或提取与 query 相关的部分。 | LLMContextCompressor |
| Re-ranking compressor | 用向量相似度或 cross-encoder 打分,仅保留最相关的若干段。 | EmbeddingsFilter |
| Token-level truncation | 简单地按 token 数裁剪到一定长度。 | TokenTextSplitter |
| Hybrid compressor | 先 re-rank,再 LLM 摘要。 | HybridContextCompressor |
以 LlamaIndex 的 ContextualCompressionRetriever 为例,调用链大致如下:1
2
3
4
5
6
7
8
9
10
11
12
13User Query
↓
BaseRetriever.retrieve(query)
↓
返回多个文档节点 NodeList
↓
ContextCompressor.compress_nodes(nodes, query)
↓
(筛选、摘要、裁剪等操作)
↓
返回压缩后的 nodes
↓
传给 LLM 进行最终生成
| Compressor 类 | 功能 | 使用场景 |
|---|---|---|
LLMTextCompressor | 让模型总结文档,只保留与 query 相关部分 | 上下文长、内容冗余 |
EmbeddingsFilter | 用向量距离过滤低相关节点 | 文档块较多、结构化内容 |
LLMRerank | 用 LLM 对检索结果重新排序 | 对召回结果精度要求高 |
ContextualCompressionRetriever | 将上面几个组合在一起,形成可直接替换的 Retriever | 实际部署推荐使用 |
| 难题 | Context Compressor 解决方式 |
|---|---|
| Token 超长,LLM输入溢出 | 过滤/摘要内容减少token数量 |
| 检索召回过多,质量不均 | 重新排序或过滤低相关内容 |
| 语义漂移(无关文档干扰) | 让LLM只保留与query紧密相关的部分 |
| 成本高、响应慢 | 通过压缩显著降低输入token成本 |
Context Compressor 是 RAG 的“智能上下文裁剪器”,让系统既保持信息完整性,又降低 LLM 的上下文负担。
它既可基于向量过滤,也可调用 LLM 自动摘要,是 LlamaIndex 构建高效 RAG 系统的核心模块之一
RAG路由
有了 Routing 之后,RAG 不再“一刀切”,而是:
- 对不同类型的查询选择不同的 知识源(Knowledge Source);
- 对不同任务选择不同的 检索算法或提示模板;
- 对简单问题甚至选择“跳过检索”,直接由LLM回答
Hyde 假设文档嵌入
不直接用原始 query 去检索,而是先让 LLM 根据 query 生成一个“假设文档(hypothetical document)”,然后再用这个文档的 embedding 去检索
传统的 RAG 检索是这样的:1
用户 query → 编码成 embedding → 检索向量库 → 返回相似文档
问题是:
- 用户的 query 很短、模糊、不包含关键信息;
- 直接编码成向量,语义空间离相关文档很远;
- 导致检索召回的文档不够相关(Recall低)
让 LLM 先根据 query “想象”出一篇可能存在的理想答案文档(假设文档),
然后把这篇“假设文档”的 embedding 当成检索向量。
这样就能更好地捕捉语义空间中与真实答案文档相近的区域。
| 步骤 | 普通 RAG | HyDE |
|---|---|---|
| 输入 | 用户 query | 用户 query |
| 编码 | 直接 embedding | 先生成“假设文档”再 embedding |
| 检索 | 基于 query embedding | 基于 hypothetical doc embedding |
| 结果 | 相关性有限 | 更接近语义空间中“答案文档” |
HyDE 的逻辑是这样的:
- 用户 query 通常是一个问题(Q-space);
- 真实文档 embedding 是在答案空间(A-space);
- LLM 生成的假设文档能将 query 从 Q-space 映射到 A-space;
- 从而弥合“问题语义”和“答案语义”的分布差异。
简单来说:
它把检索过程从 “query → 文档”
变成了 “query → 假设答案 → 相似真实文档”。
改进与变体
1️⃣ 多样化 HyDE
- 生成多个假设文档(multi-HyDE),聚合embedding。
- 适合复杂/模糊 query。
2️⃣ 基于摘要的 HyDE
- 生成简短摘要而非完整段落,减少噪声。
3️⃣ 自适应 HyDE (Adaptive HyDE)
- 当 query 较短或明确时直接用 query;
- 当 query 模糊时才生成 hypothetical 文档。
4️⃣ Rerank + HyDE 结合
- 用 HyDE 提升召回,再用 Cross-Encoder 精排
任务分解
Agent类RAG 和 LLM应用编排系统(如LangChain、LlamaIndex、Semantic Kernel) 的关键设计点之一:用户任务(query / request)的分解(decomposition)。
在Agent系统中,用户的问题往往不是“单步可解”的。例如:
“帮我写一篇关于RAG系统评估方法的技术博客,并附上代码示例。”
这个任务涉及:
- 检索知识(RAG评估方法)
- 总结内容(技术博客结构)
- 生成示例代码(代码生成)
- 格式化输出(markdown
任务分解的常见方式
- 基于提示
- 基于结构化规划
- 基于思维链CoT
- 基于图结构任务分解
- 基于自反思
动态路由到Agent
任务分解完后,如何动态路由(route)或分配(dispatch)子任务到合适的 Agent 执行。1
2
3
4
5用户输入 → Planner(任务分解) → 多个子任务
↓
Router / Coordinator
↓
按语义/类型选择合适Agent执行
- 基于规则的路由
根据 step 描述 / 工具类型 / 关键词匹配 来选 Agent。
- 基于LLM的路由
语义选择(semantic routing):用LLM本身作为路由控制器,根据语义决定执行者。
3.self-reflective Agent执行中实时判断是否需要切换任务或调用其他Agent。
Agent选择工具
1 | ┌────────────────────────────┐ |
Router:负责任务分配给合适的Agent。
Agent:负责如何完成任务。
Tools:是Agent内部的执行手段(数据库查询、API调用、代码执行等)。
每个Agent内部通常包含三个核心组件:
| 组件 | 作用 |
|---|---|
| Planner(子任务规划) | 将当前任务拆解成一步步子操作 |
| Executor / Controller | 决定使用哪个工具执行 |
| Toolset(工具集) | 具体实现执行逻辑,比如SQL查询、API请求等 |
重写query
重写query的目的
桥接语义差距:用户 query 往往短、含糊或问法与知识库文本表述差异大,直接 embedding/检索召回差。
提升召回(Recall):把 query 扩展到更接近答案空间(answer space),能检出更多相关文档。
减少误检/噪声:通过澄清或规范化避免检索到不相关语境。
支持多跳/复杂检索:将复杂问题拆解或扩展成多个更易检索的子查询。
控制检索方向:加入领域/时间/格式等约束(如“只检索2023以后”)。
降低下游幻觉:更精确的上下文,减少 LLM “凭空想象”答案的概率
- 规则与模板式重写(Rule-based)
- 思路:关键词替换、同义词扩展、实体规范化(“NYC”→“New York City”)、时间标准化等。
- 优点:可控、延迟低;缺点:覆盖面窄、维护成本高。
- 伪相关反馈(PRF, Pseudo-Relevance Feedback)
- 流程:初次检索 top-N → 从结果中抽取高频词/短语(或用 TF-IDF/Keyphrase) → 将这些词加回原 query → 再检索。
- 优点:简单高效,提升 recall;缺点:若初检结果噪声多,会放大错误。
- HyDE(Hypothetical Document Embedding)
- 思路:先用 LLM 根据 query 生成一个“假设答案文档”(hypothetical doc),对该文档做 embedding 并检索。
- 优点:把 query 从问题空间映射到答案空间,零样本效果好;缺点:增加一次 LLM 调用成本。
- LLM-based Query Reformulation(Prompt-driven)
- 思路:用 LLM 将短 query 扩写成更明确、检索友好的句子或多个候选 query(multi-query)。
- 可做:澄清问题、添加上下文(用户角色/意图)、生成多种问法。
- 优点:灵活,可控制风格;缺点:需设计好 prompt、成本较高。
- Supervised Seq2Seq Rewriter(学习式)
- 思路:用训练数据(query → gold_rewrite)微调 seq2seq 模型(T5/BART/Flan)做自动重写。
- 优点:效果稳、可离线部署;缺点:需要标注数据或用弱监督生成标签。
- Reinforcement / RLHF 优化(策略式)
- 把重写当作策略,用下游检索/生成的奖励信号训练策略模型(例如 RL/HF)。
- 更高级但复杂,适合对性能要求非常高的生产场景。
- Multi-query / Decomposition(分解式)
- 对复杂 query 产生多个子 query(或 step-by-step 中间问题),分别检索并聚合。
- 用于 multi-hop 场景。
- Hybrid(组合)
- 常见做法:先用 LLM 做 step-back(抽象),再做 PRF 或 HyDE,再用 reranker 精排
LangChain:
- 用
LLMChain+ 自定义 prompt 做重写(同步或异步)。 - 用
RouterChain将 query 先路由到 “rewriter chain” 再到retriever。 - HyDE 实现:先用 LLMChain 生成 hypothetical doc,再 embed & search(见上面代码)。
LlamaIndex:
- 提供
QueryTransform/QueryEngine,可以插入重写器(例如LLMQueryTransform)。 ContextualCompressionRetriever+LLMTextCompressor可以结合 HyDE/summary。
工程注意:
- 把重写器作为“检索前的中间链路(pre-retrieval hook)”,可配置采样率(例如只对 30% 的 query 做 LLM 重写以节省成本)。
- 对重写结果做日志(原 query, rewrite, retrieved docs)用于离线评估与模型改进。
评估重写query效果
直接检索层面指标(首选):
- Recall@k(重要)
- MRR, nDCG@k
- Precision@k(当需要高精度时)
下游生成层面指标(更能反映最终效果):
- Answer accuracy / F1(基于 gold answers)
- Human evaluation(可读性、是否改变意图)
- Faithfulness / Hallucination rate(是否降低幻觉)
效率与成本:
- Latency 增加(尤其 LLM 重写 / HyDE)
- LLM 调用次数 / token 成本
实验设计建议:
- A/B 比较:baseline(无改写) vs 各种改写策略
- 分析 fail cases:哪些 query 改写后反而降召回或改变意图?
工程实践建议与调优要点
- 先做低成本 PRF + 规则,再逐步引入 HyDE/LLM(按成本阶梯上线)。
- 针对 query 类型做分层策略:短查询/疑问句 → LLM 重写;明确事实查询 → 直接检索。
- 多候选合并策略:对多个 rewrite 分别检索并合并,使用 reranker 精排。
- 采样策略:生产环境可只对难题或抽样 query 使用昂贵重写方法。
- 日志埋点:记录原 query、rewrite、检索结果、最终回答与用户反馈用于迭代。
- 保留语义一致性:重写必须不改变用户意图;用 LLM 或规则做一致性校验(e.g., ask LLM 判断 rewrite 是否保留原意)。
- 延迟/成本控制:HyDE + multi-rewrite 提升效果明显但成本高,需权衡。
- 安全与过滤:重写可能把敏感文本扩写,注意对 PII、敏感内容做过滤。
常见陷阱(注意避免)
- 初次检索全是噪声 → PRF 效果会更差(需先保证 base retriever 有一定质量)。
- 重写改变原意(要有一致性检测或人类校验通道)。
- 过度扩展导致精度下降(precision-recall 权衡)。
- LLM 生成的假设文档带入错误事实(HyDE 生成风格需控制,不要加入虚构细节)。
- 成本不可控:LLM 重写 + 多次检索会增加延迟与费用,需限流/采样
1 | # 1. HyDE generate |
self-rag 反省
普通RAG的问题,
- 检索到的文档可能无关或质量不高;
- 模型在生成时不能动态判断“是否需要检索更多”、“是否需要反思回答是否正确”;
- 一旦生成开始,流程单向、缺乏自我校正。
Self-RAG(由 Meta AI 在 2024 年提出)通过让模型在生成前、生成中、生成后都进行自我反思,从而提升答案的准确性与可信度。
它让 LLM 在内部学会:
- 何时需要检索(是否已有足够信息);
- 检索什么(自适应地重写查询);
- 生成后如何反思并改进回答。
1 | ┌────────────────┐ |
Self-RAG 将反思嵌入在三个阶段:
1️⃣ Pre-generation Reflection(生成前反思)
- 模型先判断是否需要检索外部知识。
- 如果内部知识足够,则直接回答;
- 否则构造一个检索意图(检索查询),去外部知识库找文档。
实现方式:
模型输出一个标签或控制信号,如:1
<retrieve> climate change impacts on agriculture </retrieve>
再由检索器调用外部数据库。
In-generation Reflection(生成中反思)
- 模型在回答中可以多次调用检索(multi-hop retrieval);
- 比如生成到一半时发现信息不足,可插入“中途反思”:
1 | I realize I need more information about X... |
Retriever 再次介入,模型更新上下文继续生成。
Post-generation Reflection(生成后反思)
- 模型生成后再评估自己的回答是否:
- 覆盖了问题?
- 是否有幻觉?
- 是否逻辑一致?
实现方式:
模型在输出末尾生成一段 meta-analysis,如:1
2
3
4<critique>
The answer might miss recent research after 2023.
Confidence: 0.75
</critique>
若信心低,则可触发再检索、再生成的循环。
Self-RAG 可以通过以下组件实现:
- Retriever:支持动态调用(如FAISS、ElasticSearch、LlamaIndex Retriever等);
- Reflection Controller:负责监控生成过程、解析
<retrieve>、<critique>等控制标志; - Critic Model(可选):可以是独立LLM,用来做“回答质量评估”;
- Memory机制:保存每次反思的结果(用于改进下轮生成或学习)。
LangChain / LlamaIndex 等框架都能实现类似流程(例如用 AgentExecutor + CriticChain)
评估应用
评价指标
| 评估维度 | 核心指标 | 检测方法 |
|---|---|---|
| 会话质量 | 相关性(Relevancy) | LLM评分器(0-1分) |
| 完整性(Completeness) | 用户目标达成率分析 | |
| 状态管理 | 知识保留(Retention) | 关键信息回溯验证 |
| 可靠性(Reliability) | 错误自我修正频次统计 | |
| 安全合规 | 幻觉率(Hallucination) | 声明拆解+事实核查 |
| 毒性/偏见(Toxicity) | 专用分类模型检测 |
评估数据集
MMLU
简介:MMLU是一个涵盖57个不同学科的多任务测试基准,包括数学、历史、法律、计算机科学等领域,旨在评估模型的多学科知识和推理能力。模型通常在零样本(zero-shot)和少样本(few-shot)设置下进行评估。
数据来源:由Dan Hendrycks等人于2020年开发,数据来源于各种学术测试、专业资格考试和标准化测试
GPQA
GPQA是一个研究生物理水平的问答数据集,涵盖经典力学、量子力学、热力学、电磁学等领域的高级问题。
数据来源:由物理学家和研究生物理教育专家创建,基于研究生课程和资格考试。
评估库
Ragas
Ragas(Retrieval Augmented Generation Assessment)是一个专门评估 RAG pipeline 效果 的框架,目标是不依赖人工标注,而是自动衡量 RAG 系统中各个阶段(检索+生成)的性能。
| 类别 | 指标 | 含义 | 计算方式简述 |
|---|---|---|---|
| 🧭 检索质量 | Context Precision | 检索出的文档中,有多少是真正与答案相关的 | 计算每个检索段落与参考答案的语义相似度(通过 LLM 或 embedding) |
| Context Recall | 所需的关键信息中,有多少被检索出来 | 比较参考答案所需知识与检索内容的重叠度 | |
| Context Relevance | 检索内容是否真正回答了问题 | 用 LLM 判断 query 与 context 的相关性 | |
| 💬 生成质量 | Faithfulness | 生成内容是否忠实于检索内容(无幻觉) | 用 LLM 比较生成回答与 context 是否一致 |
| Answer Relevance | 生成回答是否与 query 对齐 | 用 LLM 判断生成回答与问题的语义相关度 | |
| Answer Correctness | 生成回答是否正确(基于参考答案) | 比较生成回答与 ground truth 的语义一致性 | |
| ⚙️ 综合 | Context Utilization | 生成内容是否真正利用了检索信息 | 检查回答中是否引用了 context 中的信息 |
Ragas 评估的实现思路(技术层面)
语义嵌入(Embedding)对齐
使用句向量模型(如sentence-transformers)计算:- 查询与文档相似度(评估检索)
- 答案与文档/参考答案相似度(评估生成)
LLM 语义打分(LLM-as-a-judge)
调用大模型,通过 Prompt 让其判断:“是否回答了问题?是否忠实于上下文?”
多维聚合评分
将多个维度(Faithfulness, Relevance 等)进行加权,得到整体质量评分
DeepEval
包括生产监控的功能.1
2
3
4
5
6
7
8
9用户请求 → RAG/Agent → 模型生成输出
↓
DeepEval Collector(采集层)
↓
Metrics Engine(指标计算:Faithfulness、Relevance 等)
↓
Storage(结果存储:Postgres、BigQuery、Prometheus)
↓
Dashboard & Alerts(Grafana / Confident Cloud / 自建可视化)
- 在线采样 在生产环境中,你不需要评估每个请求(代价太高)
- 每次 LLM 响应后,DeepEval 自动计算核心指标:
- DeepEval 提供非阻塞的日志机制:
- 可视化与趋势分析(Visualization & Drift Detection)
- 集成 CI/CD 与回归测试
DeepEval 支持与 CI/CD 集成(如 GitHub Actions):
- 每次 Prompt 或模型更新时自动运行测试;
- 如果指标下降超过阈值则阻止部署
- 异常报警机制(Alerting)
通过配置阈值和报警策略,当:
- Faithfulness < 0.7
- 或 Relevance 波动超过 20%
- 或 幻觉率 > 10%
时,自动触发:
- 邮件或 Slack 报警
- HTTP webhook 推送到告警系统
MLFlow
- 初创验证阶段 → RAGAS(快速定位检索瓶颈)
- 生产环境部署 → DeepEval(定制指标+持续监控)
- 混合架构场景 → MLFlow(统一实验跟踪)
开源RAG框架
RAGFlow
RAGFlow 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用
QAnything
网易 致力于支持任意格式文件或数据库的本地知识库问答系统,可断网安装使用。
MaxKB
MaxKB 是一款企业级知识库平台,其设计目标是为企业提供稳定、高效、易用的知识管理和 RAG 解决方案。MaxKB 强调开箱即用,提供了完善的功能和企业级特性,帮助企业快速构建和部署知识库应用,并提升知识管理的效率
Dify
Dify 作为一款 LLM 应用开发平台,其 RAG 能力同样不容忽视。Dify 的优势在于其平台化的设计理念,将 RAG 引擎作为核心组件,并集成了模型管理、工作流编排、可观测性等企业级特性,使得开发者可以更专注于业务逻辑的实现。
Haystack
Haystack 是一个强大而灵活的框架,用于构建端到端问题解答和搜索系统。它采用模块化架构,允许开发人员轻松创建各种 NLP 任务的管道,包括文档检索、问题解答和摘要:
支持多种文档存储(Elasticsearch、FAISS、SQL 等)
与流行的语言模型(BERT、RoBERTa、DPR 等)集成
处理大量文件的可扩展架构
参考资料
- AutoGen — AutoGen
- Overview - Docs by LangChain
- Choosing Your Agent Toolkit: LangChain, LangGraph, LlamaIndex & AutoGen Explained | by Ridhi Tamirasa | Medium
- Welcome to LlamaIndex 🦙 ! | LlamaIndex Python Documentation
- Agentic RAG
- Prompt Engineering Guide | Prompt Engineering Guide
- Vector Database Stories
- openai/openai-cookbook: Examples and guides for using the OpenAI API
