目前LLM应用集中在开发所谓AI智能体,理想中的AI智能体能够自主感知环境并作出决策,与环境的变化不断反馈,同时具备记忆,反思和工具能力.而目前的AI应用中,效果最好,成本也低的还是RAG.
RAG应用场景
RAG全称是“Retrieval-Augmented Generation”,即“检索增强的生成”。当设计一个LLM问答应用,模型需要处理用户的领域问题时,尽管大模型通常表现出色,但有时提供的答案并不准确,甚至可能出现错误。当用户需要获取实时信息时,模型无法及时提供最新的答案。这种现象在LLM应用中较为常见。
这些模型仍然存在一些无法忽视的局限性。其中,领域知识缺乏是最明显的问题。大模型的知识来源于训练数据,这些数据主要来自公开的互联网和开源数据集,无法覆盖特定领域或高度专业化的内部知识。
信息过时则指模型难以处理实时信息,因为训练过程耗时且成本高昂,模型一旦训练完成,就难以获取和处理新信息。
此外,幻觉问题是另一个显著的局限,模型基于概率生成文本,有时会输出看似合理但实际错误的答案。最后,数据安全性在企业应用中尤为重要,如何在确保数据安全的前提下,使大模型有效利用私有数据进行推理和生成,是一个具有挑战性的问题。
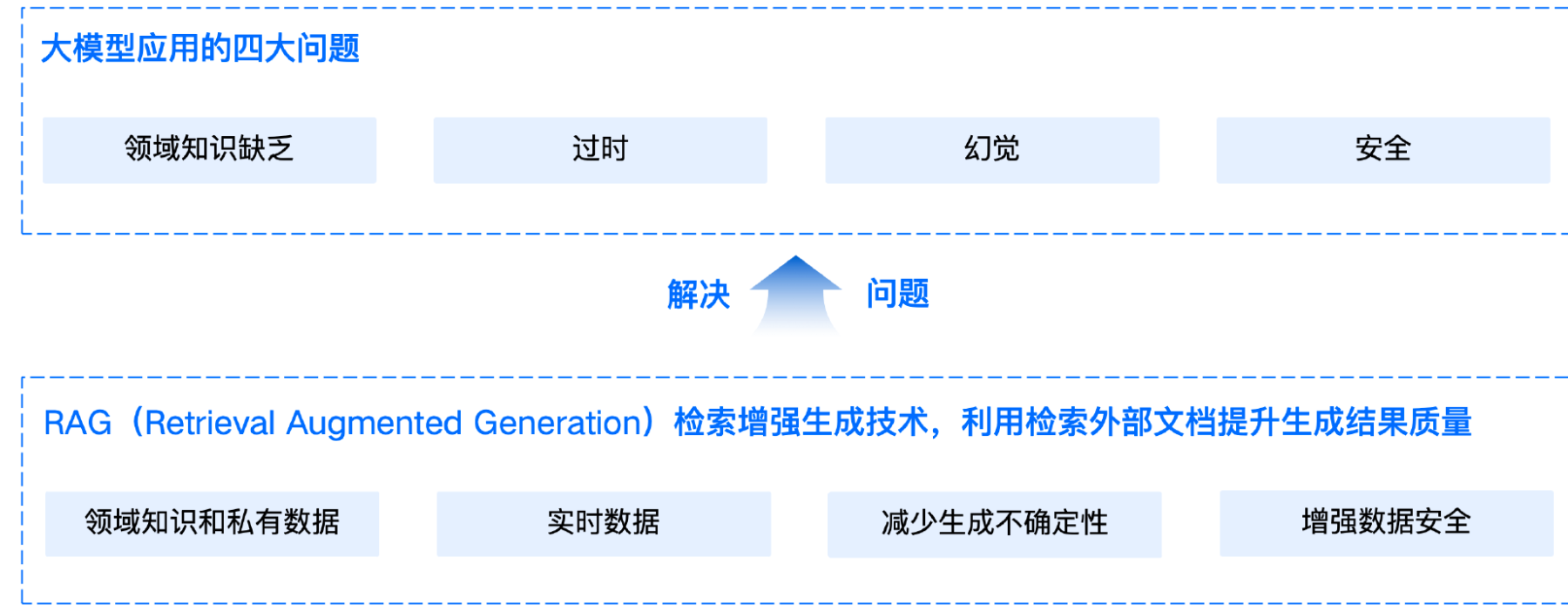
RAG系统的应用场景主要集中在专业领域和企业场景,
RAG的核心思想是利用外部知识库或数据集来辅助模型的生成过程。具体来说,RAG通常包含以下关键步骤。
- 检索阶段:首先,模型会根据输入的查询或问题,从预先构建的索引中检索出最相关的数据、文档或文本片段。
- 生成阶段:随后,模型会使用这个综合的表示来生成答案或输出文本。在问答任务中,这通常意味着生成一个对原始查询的直接回答。
选择RAG而不是直接将所有知识库数据交给大模型处理,主要是因为模型能够处理的token数有限,输入过多token会增加成本。更重要的是,提供少量相关的关键信息能够带来更优质的回答。
RAG模型的核心思想在于通过检索与生成的有机结合,弥补大模型在处理领域问题和实时任务时的不足。传统的生成模型在面对复杂问题时,往往由于知识储备不足,生成出错误或无关的回答。而RAG通过检索模块获取相关的背景信息,使生成模块能够参考这些信息,从而生成更具可信度和准确性的答案。这种方法不仅增强了生成内容的准确性,还提高了模型在应对特定领域知识和动态信息时的适应能力。
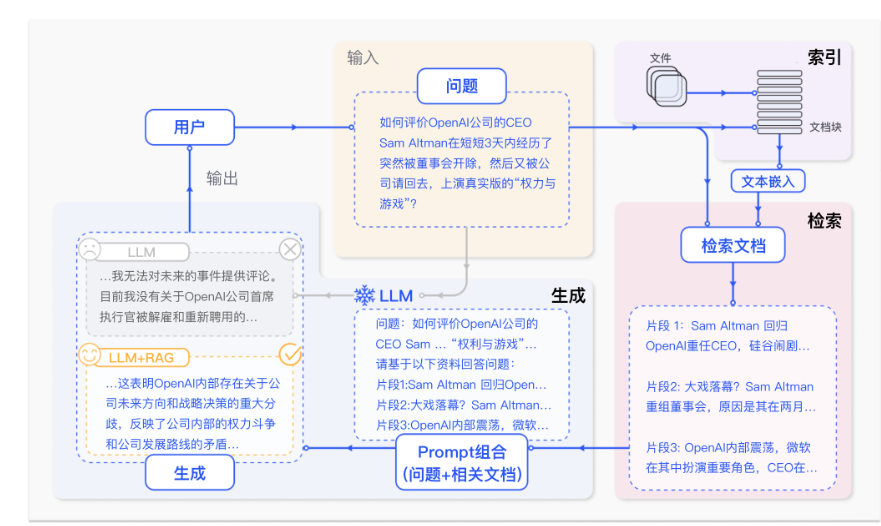
RAG标准流程由索引(Indexing)、检索(Retriever)和生成(Generation)三个核心阶段组成。
- 索引阶段,通过处理多种来源多种格式的文档提取其中文本,将其切分为标准长度的文本块(chunk),并进行嵌入向量化(embedding),向量存储在向量数据库(vector database)中。
- 检索阶段,用户输入的查询(query)被转化为向量表示,通过相似度匹配从向量数据库中检索出最相关的文本块。
- 最后生成阶段,检索到的相关文本与原始查询共同构成提示词(Prompt),输入大语言模型(LLM),生成精确且具备上下文关联的回答。
索引是RAG系统的基础环节,包含四个关键步骤。
- 首先,将各类数据源及其格式(如书籍、教材、领域数据、企业文档等,txt、markdown、doc、ppt、excel、pdf、html、json等格式)统一解析为纯文本格式。
- 接着,根据文本的语义或文档结构,将文档分割为小而语义完整的文本块(chunks),确保系统能够高效检索和利用这些块中包含的信息。
- 然后,使用文本嵌入模型(embedding model),将这些文本块向量化,生成高维稠密向量,转换为计算机可理解的语义表示。
- 最后,将这些向量存储在向量数据库(vector database)中,并构建索引,完成知识库的构建。这一流程成功将外部文档转化为可检索的向量,支撑后续的检索和生成环节。
检索是连接用户查询与知识库的核心环节。首先,用户输入的问题通过同样的文本嵌入模型转换为向量表示,将查询映射到与知识库内容相同的向量空间中。通过相似度度量方法,检索模块从向量数据库中筛选出与查询最相关的前K个文本块,这些文本块将作为生成阶段输入的一部分。通过相似性搜索,检索模块有效获取了与用户查询切实相关的外部知识,为生成阶段提供了精确且有意义的上下文支持。
生成是RAG流程中的最终环节,将检索到的相关文本块与用户的原始查询整合为增强提示词(Prompt),并输入到大语言模型(LLM)中。LLM基于这些输入生成最终的回答,确保生成内容既符合用户的查询意图,又充分利用了检索到的上下文信息,使得回答更加准确和相关,充分使用到知识库中的知识。通过这一过程,RAG实现了具备领域知识和私有信息的精确内容生成。
Fine-tuning vs RAG
Fine-tuning 作为一种直接针对预训练语言模型进行额外训练的方法,能够让模型更好地适应特定领域或任务。这种方法的核心优势在于,能够显著提升模型在目标任务上的表现。通过使用领域特定的数据集,Fine-tuning 可以让模型学习到行业术语、专业知识结构和特定的表达方式。这使得Fine-tuned模型在处理专业领域的问题时,能够提供更加准确、相关的回答。例如,在极客时间,我们把作者的实战经验从文章中提取出来,然后基于开源模型进行微调,让 LLM 可以输出生产环境直接可用的技术方案,而不是一些通用解决方案。
微调更适合需求稳定、领域知识固定且不需要频繁更新知识库的场景。通过使用特定领域的数据对模型进行深度优化,微调可以提升模型在特定任务或领域中的推理能力,确保输出内容的专业性和一致性。因此,当任务侧重于某一特定领域,并且对实时信息的依赖较低时,微调更能满足这些需求
此外,Fine-tuning 后的模型响应速度快,无需在运行时检索外部知识库,这使得它特别适合需要实时响应的场景,比如在线客户服务或实时决策支持系统。举个例子,在我们的用户对话功能中,有时候人工客服可能不在线,用户提问如果能快速得到响应,及时解答用户问题,可以大大提高用户的信任感。
当然,使用 Fine-tuning 也要付出一些额外的成本。它需要大量的标注数据和较高的计算资源,这对许多企业来说可能是一个门槛。而且,一旦模型经过 Fine-tuning,要更新其知识就需要重新训练,如果是经常变化的知识,可能成本就非常高了。
相比之下,RAG 技术提供了一种更为灵活的解决方案,可以更好地处理 “经常变化” 的知识。RAG 通过将大语言模型与外部知识库结合,在生成回答时实时检索相关信息。这种方法非常灵活,由于是自己设计的知识库,可以做各种优化操作,保证把最准确的知识呈现给用户。企业可以随时更新知识库中的信息。
RAG 的另一个重要优势是其可解释性。由于每个回答都可以追溯到具体的知识来源,这大大增强了AI系统的可信度和透明度。在需要严格监管或高度问责的行业,如金融服务或政府部门,这一特性尤为重要。然而,RAG也有其局限性。由于需要实时检索知识库,RAG系统的响应速度可能不如 Fine-tuned 模型快。此外,RAG的效果高度依赖于知识库的质量和检索算法的效率,这要求我们投入大量资源来维护和优化知识库。
在实际应用中,我们可以将 Fine-tuning 和 RAG 结合使用,以充分发挥两种方法的优势。这种混合方法可以应对更复杂的场景和挑战。例如,要做一个极客时间客服系统,我们可以使用 Fine-tuned 模型来处理常见的、结构化的查询,比如一些通识或者固定不变的知识,保证快速、准确的响应。同时,对于涉及最新产品信息或政策变更的问题,系统可以切换到 RAG 模式,利用实时更新的知识库来提供最新、最相关的信息。在产品研发过程中,可以使用企业内固定的技术相关文档进行 Fine-tuning,让 LLM 回答的内容都是符合企业开发技术范围,再配合上 RAG 把一些外部的技术文档作为补充知识库,两者结合,在内部就可以很好地辅助产研人员工作。
未来方向
第一个方向是动态知识图谱的集成。传统的RAG系统通常使用静态的知识库,而动态知识图谱将为RAG带来更智能、更灵活的知识管理能力。这种系统不仅能够实时更新知识,还能自动建立知识之间的关联。
在前面课程中提到的 Mem0 记忆框架,最近更新了一个特性,就是 graph memory。它把用户的记忆拆分成记忆节点和关系,通过使用图数据库,保存下这些关系和节点,在使用记忆的时候,会通过图检索技术找到记忆之间的关联,从而找到关键的记忆点,然后结合当时的详细记忆,最终给出回答。这种技术可以让用户在海量记忆中去查询问题的答案,相比传统的 RAG,极大程度地提高了记忆的相关性和连续性。
还有就是最近大火的GraphRAG。GraphRAG 本身是一个理论,这个项目是由微软开源的,它包括从原始文本中提取知识图,构建社区层次结构,为这些社区生成摘要,然后在执行基于 RAG 的任务时利用这些结构等等功能。
第二个方向是个性化 RAG。未来的RAG系统将能够根据用户的背景、偏好和使用历史来动态调整其检索和生成策略。
例如,一个个性化的 RAG 系统可以根据用户的知识水平、学习风格和关注点来推荐内容和解答用户问题。这种个性化不仅限于内容的选择,还包括表达方式的调整,使得AI助手能够以最适合每个用户的方式进行交流,可以根据不同用户的喜好风格,调整 AI 小助手的说话方式。这将大大提高用户体验,使AI系统更加贴近人类的交互需求,带给用户更多的亲切感。
第三个方向是多模态 RAG。上述的讨论都建立在文本模型上,如果再加上视觉模型,让大模型能像人眼一样观察世界,再把看到的东西内化到知识库中,这将会大大拓宽 RAG 的应用范围,让更多的业务能够用上大模型技术。
比如,在医疗领域,使用多模态 RAG 系统可能会同时分析病人的症状描述(文本)、X光片(图像)、心电图(时序数据)和医生的口头诊断(音频)。系统不仅能够理解每种模态的信息,还能够在这些不同模态之间建立联系,提供更加全面和准确的诊断建议。相对于只有文本内容,这种方式能够得出更加准确和有深度的诊断,也更加符合医生的诊断习惯。通过与多模态结合,将会让大模型在更多领域发挥价值,甚至会产生新的产品形态或者服务方式。企业在这个方向上进行探索,会带来创新性的收获。
IM系统
基于 Netty ⾃定义 WebSocket 协议实现⾼性能即时通讯服务;利⽤ Redisson 缓存会话列表与⽤⼾路由以优 化加载性能同时维护集群环境下的⽤⼾状态。此外,通过设计离线消息增量拉取逻辑,确保⽤⼾重连后消息有 序不丢失。
是基于 Netty 搭建高性能 WebSocket 即时通讯服务,解决三个核心问题:
①单节点高性能通讯 ②集群下用户状态同步 ③用户重连后离线消息不丢失且加载高效。整体架构上,用 Netty 做底层通讯层,Redisson(Redis)做分布式缓存 / 消息广播层,再通过离线消息增量拉取的业务逻辑保证消息一致性。
Netty + 自定义 WebSocket 实现高性能即时通讯
Netty 是一个异步事件驱动的网络应用框架,用于快速开发高性能、高可靠性的网络服务器和客户端
异步非阻塞:基于 NIO,支持高并发
高性能:零拷贝、内存池、对象池
高可靠性:完善的异常处理、断连重连
高度可定制:灵活的线程模型、编解码
首先是底层通讯层的设计,选择 Netty 是因为它的 NIO 非阻塞 Reactor 模型天生适配高并发的长连接场景,比传统 BIO 的 Tomcat WebSocket 性能提升显著:
- 协议层处理:在 Netty 的 ChannelPipeline 中做了分层 Handler 设计:
- 先通过
HttpServerCodec+HttpObjectAggregator处理 HTTP 协议(因为 WebSocket 握手基于 HTTP),保证 HTTP 请求的完整性; - 再通过
WebSocketServerProtocolHandler将 HTTP 协议升级为 WebSocket,支持全双工长连接,同时配置帧大小、握手超时等参数避免异常连接; - 核心的心跳保活:加入
IdleStateHandler设置 60 秒读超时(用户端 60 秒没发心跳则判定连接失效),配合自定义的HandlerHeartBeat处理器,监听到读超时事件后主动关闭无效连接,避免资源泄漏;写超时暂时设为 0(心跳由客户端主动发,服务端仅被动检测),如果检测到写超时也会主动推送心跳包维持连接。
- 先通过
- 高性能优化:拆分 Boss/Worker 线程组(Boss 组仅处理连接建立,Worker 组处理消息读写),避免连接和消息处理互相阻塞;给业务 Handler 加
@Sharable注解复用实例,减少对象创建开销;容器销毁时通过@PreDestroy优雅关闭 EventLoopGroup,防止端口占用 / 线程泄漏。
Redisson 缓存会话 & 用户路由(解决集群状态同步)
单节点下可以用本地 ConcurrentMap 维护用户 ID 和 Netty Channel 的映射,但集群环境下节点间隔离,必须用分布式缓存 / 广播:
缓存设计:会话列表缓存:把用户的聊天会话(ChatSessionUser)缓存到 Redis,用户上线时直接从 Redis 拉取,比每次查数据库减少 80% 以上的加载耗时;
用户路由:用 Redis 维护「用户 ID - 节点标识 - Channel」的映射,同时基于 Redisson 的
RTopic实现集群消息广播 —— 比如 A 节点的用户给 B 节点的用户发消息,先通过 RTopic 把消息广播到所有节点,节点收到后查本地 ChannelMap,找到目标用户则推送消息,解决集群下消息路由问题;状态维护:用户上线 / 下线 / 心跳都会更新 Redis 中的状态(比如
saveUserHeartBeat记录心跳时间,removeUserHeartBeat清理离线状态),集群节点可通过 Redis 感知用户在线状态,避免给离线用户推送无效消息。选型思考:选 Redisson 而非原生 Redis 客户端,是因为它封装了分布式锁、ChannelGroup、Topic 等适配 Netty 的特性,且支持 Redis 集群模式,能直接对接生产环境的 Redis 集群。
离线消息增量拉取(保证消息有序不丢失)
用户重连后如果全量拉取所有消息,不仅性能差,还会导致用户体验下降,所以设计了增量拉取逻辑:
- 核心锚点:在用户表(UserInfo)中记录
lastOffTime(最后离线时间戳),用户重连时以此为基准拉取增量数据; - 增量范围控制:考虑到用户离线过久(比如超过 3 天)会产生大量消息,限制仅拉取最近 3 天的增量,平衡性能和用户体验;
- 增量维度:
- 会话列表:按
last_receive_time > lastOffTime筛选离线期间有新消息的会话,保证会话最新; - 聊天消息:按联系人维度(用户 / 群聊)筛选离线期间新增的消息,且按接收时间降序排序,确保消息有序;
- 好友申请:筛选离线期间新增的未处理申请,统计数量并推送给用户;
- 会话列表:按
- 实现细节:将这些增量数据封装成
WsInitData对象,在用户握手成功后一次性推送,既保证消息不丢失,又避免全量加载的性能问题。
IM系统保证消息的可靠(有序、不丢失、不重复)
客户端 A 向 B 发送消息要实现绝对可靠(不丢、不重、有序、可达),需要覆盖「发送端→服务端→接收端」全链路的确认机制、异常兜底和存储保障。结合你现有 Netty+Redisson/Redis 的技术栈,以下是可落地的核心方案(补充现有离线增量拉取、集群广播之外的可靠性保障):
消息可靠的本质是「全链路确认 + 多层兜底」:
- 不丢:每一步操作都有「确认回执」+「持久化兜底」;
- 不重:全局唯一 ID + 幂等校验;
- 有序:基于时序 / 唯一 ID 的排序机制;
- 可达:离线兜底 + 重试机制。
发送端(A):避免「发出去就丢」
客户端本地缓存 + 重试机制
- 问题:A 发送消息时网络闪断 / 服务端暂不可达,消息直接丢失。
- 实现:A 发送消息前,先将消息(带全局唯一 msgId,雪花算法生成)缓存到本地(移动端用 SP/MMKV,PC 端用本地 DB),标记状态为「待发送」;
- 监听 Netty writeAndFlush的 Future 回调:
- 成功(收到服务端「接收 ACK」):更新本地状态为「已发送」;
- 失败 / 超时:触发指数退避重试(1s→3s→5s,最多 5 次),重试失败则标记「发送失败」,给用户弹窗提示手动重发。
- 监听 Netty writeAndFlush的 Future 回调:
服务端「接收确认」(第一层兜底)
问题:服务端收到 A 的消息但未处理就宕机,消息丢失。
只有DB 写入成功,才给 A 返回 ACK;否则告知 A 发送失败,触发客户端重试。
服务端转发阶段:避免「服务端收到但 B 收不到」
消息持久化 + 投递状态跟踪
- 问题:服务端已接收消息,但 B 离线 / Channel 断开,消息无法投递。
- 实现:消息落地到
chat_message表时,增加message_status字段(TO_DELIVER待投递 /DELIVERED已投递 /READ已读);
集群环境:可靠广播替代普通 Topic
- 问题:现有
RTopic是普通广播,若消费节点宕机,消息直接丢失。 - 实现:用 Redisson
ReliableTopic(可靠 Topic)替代普通RTopic
接收端(B):避免「收到但没确认」
(1)接收 / 已读确认机制(回执)
- 问题:B 收到消息但服务端不知情,A 误以为消息丢失,重复发送。
- 实现:
- B 收到消息后,立即给服务端返回「已接收 ACK」(携带 msgId);
- 服务端收到 ACK 后,更新 DB/Redis 中消息状态为「DELIVERED」,并推送给 A「B 已收到」的回执;
- B 进入聊天窗口阅读消息后,再返回「已读 ACK」,服务端更新状态为「READ」,同步给 A(已读回执)
(2)幂等去重:避免重复消息
- 问题:网络重试 / 集群广播导致 B 收到重复消息。
- 实现:全局唯一 msgId:所有消息用雪花算法生成唯一 ID(包含用户 ID、时间戳、序列号);
- 客户端 B:本地维护「已接收 msgId 列表」(内存 + 本地缓存),收到消息先校验 msgId 是否存在,存在则丢弃;
- 服务端:Redis 中维护
msg_delivered_set:{userId}(已投递 msgId 集合),推送前先校验,避免重复推送。
极端场景:兜底保障
(1)死信队列(DLQ):处理多次重试失败的消息
- 问题:B 长期离线 / 账号异常,消息重试 N 次仍无法投递,导致消息积压 / 丢失。
- 实现:
- 消息重试≥5 次仍失败,转入死信队列
DLQ_QUEUE; - 后台定时任务扫描死信队列,做兜底处理:
- 给 A 推送「消息投递失败」提示;
- 若 B 是离线状态,保留消息到 DB,待 B 上线后强制触发增量拉取;
- 死信消息保留 7 天,避免永久丢失。
- 消息重试≥5 次仍失败,转入死信队列
(2)分布式事务:保障「存储 + 投递」原子性
问题:服务端将消息存入 DB,但推送时失败,导致「存了但没发」。
实现:基于「本地消息表 + 定时任务」实现最终一致性:
服务端接收 A 的消息时,同时写入「本地消息表」(标记「待投递」);
定时任务扫描本地消息表,重推「待投递」且超过阈值(比如 10s)的消息;
推送成功后更新状态为「已投递」,避免重复扫描。
心跳机制为什么设 60 秒读超时?写超时为什么设 0?
答:读超时设 60 秒是结合业务场景(即时通讯不需要超高频心跳),平衡「连接保活」和「资源占用」—— 太短会增加客户端心跳开销,太长会导致无效连接占用端口 / 线程;写超时设 0 是因为我们设计的是「客户端主动发心跳,服务端被动检测」,如果服务端主动推心跳(写超时触发),会增加服务端开销,且客户端如果在线,自然会主动发心跳,无需服务端额外推送。
集群下怎么保证消息不推错、不重复?
方法一:首先通过 Redisson RTopic 广播消息时,会携带「目标用户 ID」,每个节点收到广播后,先查本地的 USER_CONTEXT_MAP(ConcurrentMap),只有本地有该用户的 Channel 才会推送,避免推错;其次消息推送前会结合 Redis 的用户在线状态做校验(比如用户已离线则不推送),且聊天消息入库时会加唯一 ID,客户端收到后去重,避免重复推送。
离线消息增量拉取怎么保证有序?
数据库层面给chat_message表的last_receive_time字段加了索引,查询时按last_receive_time desc排序,拉取后推送给客户端时也是按这个顺序;另外会话列表也按最后接收消息时间降序排列,保证用户重连后看到的消息 / 会话和离线前的顺序一致,符合用户的使用习惯。
文件分片上传、断点续传
可靠性、有序性、不重复
RAG检索流水线
按 “数据侧 + 查询侧” 梳理
核心流程分两大环节:
- 离线数据预处理(语料入库): - 垂直领域语料清洗(去重/降噪/结构化)→ 拆分chunk(按语义/固定长度,比如512token); - 双路编码:① 用领域微调的Bi-Encoder(如BERT-base)将chunk转为768维向量;② 对chunk做中文分词(IK分词器),提取关键词/实体; - ES索引构建:创建混合索引(text类型存文本+dense_vector类型存向量),同时优化BM25参数、向量索引类型。 2. 在线检索(问答推理):
- 用户问题输入 → 同样做Bi-Encoder向量化+关键词提取; - 多路召回:① KNN向量检索(top100)+ ② BM25关键词检索(top100); - 结果去重/合并(保留top100)→ Cross-Encoder重排(对“问题+候选chunk”打分)→ 取top10作为检索结果; - 把top10 chunk拼接为prompt,送入大模型生成回答 → 返回最终结果。
文件解析与切片、向量入库
文档预处理(统一格式 + 噪声清洗)
先将不同格式(PDF/Word/Markdown/TXT)的文档标准化,同时过滤无意义内容,避免干扰分片逻辑:
多格式文本提取
| 文档格式 | 提取方式(核心工具 / 逻辑) |
|---|---|
| Word(DOCX/DOC) | 解析 XML 结构,提取「样式层级(标题 1/2/3)、正文段落、文本块」(工具:POI); |
| 文本型 PDF:Apache PDFBox/IText 提取文本块,按字体大小 / 行距 / 缩进识别标题;图片型 PDF:先 OCR(Tesseract)转文本,再按文本块拆分; | |
| Markdown | 解析#/##/###标题标识、空行、列表符,识别章节 / 段落边界; |
| TXT | 按换行符、特殊分隔符(如====/----)识别章节,保留原始文本结构; |
实现基于⽂档层级树的分层索引⽅案,通过“章-段-句”组织结构并以句⼦为最小向量单元,解决常规硬切⽚ 导致的语义链断裂问题。同时集成⽗⼦索引策略实现“细粒度检索、宽粒度召回”,以解决⻓⽂档问答中的信 息碎⽚化问题。
2. 噪声清洗
- 正则过滤:移除页眉页脚(如 “XX 白皮书 第 X 页”)、水印、重复空行、无意义符号(如
★/■); - 特殊文本处理:表格 / 公式 / 代码块标记为 “特殊单元”,暂不拆分(后续单独处理)。
层级树构建核心步骤(从顶层到叶子节点)
步骤 1:章节级分片(树的「分支节点」)
目标:识别 “章 / 节” 边界,构建层级树顶层,核心是 “标题规则 + 主题连续性”。
1. 章节边界判定规则(优先级从高到低)
| 规则类型 | 具体逻辑 |
|---|---|
| 格式规则 | - 一级标题:Word “标题 1”、Markdown#、PDF 字体≥16 号且加粗、TXT “第 X 章”;- 二级 / 三级节:Word“标题 2/3”、Markdown##/###、PDF 字体≥14 号; |
| 主题规则 | 无格式标题时,用 NLP 主题模型(如 LDA)分析文本主题,主题突变处判定为新章节; |
| 兜底规则 | 超长无标题文档:按 “每 5000 字(可配置)” 拆分虚拟章节(标记为 “未命名章节 X”); |
. 章节节点生成
遍历预处理后的文本,生成章节节点,结构示例:
java
运行1
2
3
4
5
6
7
8
9// 章节节点核心结构
class ChapterNode {
private String chapterId; // 唯一ID(如doc_1_chapter_1)
private String parentChapterId; // 父章节ID(顶级章为null)
private String title; // 章节标题(如“1.1 人工智能发展历程”)
private Long startPos; // 文本起始位置(用于溯源)
private Long endPos; // 文本结束位置
private List<String> paragraphIds; // 子段落ID列表(初始为空)
}
- 关联逻辑:将 “标题后→下一个标题前” 的所有正文,绑定为该章节的 “待分片段落内容”。
步骤 2:段落级分片(树的「中间节点」)
目标:拆分章节下的正文为段落,核心是 “格式边界 + 语义边界” 双判定。
1. 段落边界判定规则
表格
| 规则类型 | 具体逻辑 |
|---|---|
| 格式边界(优先) | Word 段落标记、PDF 文本块分隔、Markdown/TXT 空行(连续≥1 个换行); |
| 语义边界(补充) | 无格式分隔时,按 “连续文本 + 换行 + 非缩进文本” 判定段落结束;用 HanLP/LTP 的「分词 + 依存句法分析」,确保段落语义完整; |
2. 段落节点生成
遍历章节下的正文,拆分段落并关联到父章节,结构示例:1
2
3
4
5
6
7
8
9// 段落节点核心结构
class ParagraphNode {
private String paragraphId; // 唯一ID(如doc_1_chapter_1_para_1)
private String chapterId; // 父章节ID(关联顶层)
private String text; // 段落文本
private List<String> sentenceIds; // 子句子ID列表(初始为空)
private String prevParaId; // 前一段落ID(上下文回溯)
private String nextParaId; // 后一段落ID
}
步骤 3:句子级分片(树的「叶子节点」,最小向量单元)
目标:拆分段落为句子(最小语义单元),核心是 “句终结符 + 语义完整性校正”。
1. 句子边界判定规则(避免语义割裂)
| 基础规则 | 具体逻辑 |
|---|---|
| 句终结符 | 中文:。!?;;英文:. ! ?;特殊处理:省略号……、引号内句子不拆分; |
| 语义校正规则 | - 用 HanLP 的「句法分析」检查:如 “因为 A,所以 B。” 不能拆分为 “因为 A,” 和 “所以 B。”;- 过滤无意义短句(如仅 “注:”“补充:”);- 对话拆分:“小明:你好!小红:再见!”→拆为 2 个句子; |
2. 句子节点生成(最小向量单元)
遍历段落文本,拆分句子并关联到父段落,结构示例:1
2
3
4
5
6
7
8
9
10// 句子节点核心结构(最小向量单元)
class SentenceNode {
private String sentenceId; // 唯一ID(如doc_1_chapter_1_para_1_sent_1)
private String paragraphId; // 父段落ID(关联中间层)
private String chapterId; // 父章节ID(跨层关联)
private String text; // 句子文本(完整语义)
private float[] vector; // 句子向量(后续嵌入生成)
private String prevSentId; // 前一句子ID(上下文回溯)
private String nextSentId; // 后一句子ID
}
难点 1:常规硬切片导致的语义链断裂
- 核心痛点:传统硬切片(按固定字符数 / 行数切分)会割裂完整语义单元,比如一个因果句 “因为 A 技术高并发,所以 B 场景选 A” 被拆成两段,检索 “B 场景选 A 的原因” 时,仅能匹配到后半段,丢失 “高并发” 核心语义,导致问答结果缺失关键信息。
- 解决方案:
- 层级化语义拆分:放弃无意义硬切片,基于文档原生结构(章标题、段分隔符、句终结符「。!?」)构建 “章 - 段 - 句” 层级树,确保每个层级都贴合自然语义边界;
- 最小语义单元锁定:以 “句子” 为最小向量单元生成嵌入向量,保证单个向量承载完整语义(如上述因果句作为一个向量单元),从底层避免语义链断裂;
- 上下文关联存储:每个句子向量额外存储「父节点(段落 ID / 章节 ID)+ 前后句 ID」元数据,即使检索到单个句子,也能快速回溯到所属段落 / 章节,补充完整语义链。
长文档问答的信息碎片化
核心痛点:长文档按句子级细粒度检索时,能精准匹配到相关句子,但结果是孤立的 “信息碎片”,无法整合出有逻辑的完整答案;若按章节级粗粒度检索,召回范围过宽,精准度极低。
解决方案(父子索引策略):
索引分层设计:
- 子索引(细粒度):存储句子级向量 + 语义元数据,负责 “细粒度检索”—— 精准定位用户问题对应的核心句子;
- 父索引(宽粒度):对段落 / 章节内所有句子向量做均值 / 加权聚合,生成段落 / 章节级聚合向量,负责 “宽粒度召回”—— 召回核心句子所属的完整段落 / 章节;
检索协作流程
:① 用户提问→子索引检索 Top-N 相似句子→获取句子所属段落 / 章节 ID;
② 基于章节 ID 在父索引中召回完整段落 / 章节内容(宽粒度);
③ 以宽粒度内容为上下文,整合细粒度句子,生成完整问答答案,解决信息碎片化;
权重调优:父索引召回时,基于子索引匹配句子的相似度权重对父节点排序,优先召回核心句子所属的父节点,保证宽粒度内容与问题强相关。
多格式文档的层级树构建精准性
核心痛点:PDF(无显性段落标记)、Word(样式层级)、Markdown(# 标识)等不同格式文档的 “章 - 段 - 句” 边界差异大,导致层级拆分不精准;长文档层级树节点过多,索引构建 / 检索效率低。
解决方案
多格式结构化解析
:PDF:通过文本块 + 行距分析识别段落,结合 OCR 处理图片文本后再拆分句子;
- Word:解析样式层级(标题 1→章、标题 2→节、正文→段),按样式拆分层级;
- Markdown:通过 #/##/### 识别章节,按换行符拆分段落;
- 引入 NLP 工具(HanLP/Jieba)做句法分析,校正拆分错误(如省略号误判为句终结符);
层级树轻量化
:过滤页眉页脚、免责声明等无意义节点,对超长章节(万字以上)在 “段” 层级做二次语义拆分(保证段落语义完整),减少节点数量;
增量索引更新
:记录各层级节点的修改时间戳,仅对更新的章 / 段 / 句重新生成向量并更新索引,而非全量重建。
细粒度检索 + 宽粒度召回的效率平衡
核心痛点:句子级检索需遍历大量向量,章节级召回需关联父节点,双重检索导致延迟升高;向量数据库性能随数据量增长下降。
解决方案:
预关联映射表:
提前构建「句子 ID→段落 ID→章节 ID」映射表,存储在向量数据库元数据中,检索时无需额外查询,直接关联父节点;
向量数据库分层优化:
- 选型:用 Milvus(支持分区)按章节分区存储父 / 子索引;
- 索引类型:子索引用 IVF_FLAT(保证精度),父索引用 HNSW(提升速度);
结果截断与缓存
:细粒度检索仅返回 Top-10 相似句子,减少关联父节点的开销;对高频查询的章节向量做缓存,降低重复检索成本。
知识库检索
构建基于 Elasticsearch 的 RAG 检索流⽔线,通过集成 KNN 向量检索与 BM25 关键词匹配实现多路召回, 并引⼊ Cross-Encoder 重排模型以优化语义对⻬精度,在平衡系统响应性能的同时将垂直领域问答准确率提 升25% 以上。
什么选择 KNN+BM25 多路召回,而非单一检索方式?
回答思路(对比单一方式的痛点,突出互补性):
垂直领域(比如金融/医疗)的问答有两个核心诉求:精准匹配专业术语 + 语义理解上下文,单一方式无法兼顾:
- 仅用BM25:依赖关键词匹配,容易出现“词不达意”(比如用户问“糖尿病血糖控制”,BM25可能漏检含“降糖”但无“血糖控制”的语料),语义召回率低;
- 仅用KNN向量检索:对专业术语的精准匹配弱(比如“重疾险”和“重大疾病保险”向量相似但关键词完全不同时,可能漏检),且向量检索性能成本更高;
- 多路召回:BM25保证“关键词精准性”,KNN保证“语义相关性”,两者互补覆盖更多候选结果,为后续重排提供足够的优质样本。
Cross-Encoder 重排的作用是什么?和 Bi-Encoder 的区别?为什么选它?
作用:解决多路召回结果中“语义匹配精度低”的问题——召回阶段为了兼顾召回率会返回较多候选,但部分候选和问题的语义匹配度低,Cross-Encoder通过“问题+候选文本”的成对打分,精准排序出最相关的结果。
与Bi-Encoder的区别: - Bi-Encoder:单文本编码(问题/候选分别编码),速度快但精度低(编码时无交互),适合召回阶段; - Cross-Encoder:成对编码(问题和候选拼接后编码),精度高但速度慢(无法预编码),适合重排阶段; 3. 选择原因:垂直领域对问答准确率要求高,且召回后候选集已压缩到100条内,Cross-Encoder的性能损耗可控,能显著提升语义对齐精度。
在 ES 中是如何实现 KNN 向量检索的?用到了哪些 ES 特性?
回答思路(结合 ES 版本 / 索引类型 / 参数,体现实操):
我们用的是ES 8.x版本(原生支持dense_vector和KNN),核心实现细节:
- 向量字段定义:创建索引时指定dense_vector类型,参数设置:
“vector”: {
“type”: “dense_vector”,
“dims”: 768, // 与Bi-Encoder输出维度一致
“index”: true,
“similarity”: “cosine” // 垂直领域语义匹配用余弦相似度更合适
} - 向量索引类型:选择HNSW(Hierarchical Navigable Small Worlds),相比brute-force暴力检索,HNSW在召回率(>95%)和性能(QPS提升3倍)间更平衡,关键参数调优:
- m: 16(邻接节点数,平衡召回率/内存);
- ef_construction: 100(构建索引时的探索深度);
- ef_search: 50(检索时的探索深度);
- 检索语法:用ES的knn查询子句,指定字段、查询向量、k值(top100),和BM25查询通过bool should子句实现多路召回。
多路召回的结果是如何合并 / 去重的?有没有做权重调整?
合并逻辑分三步: 1. 去重:基于chunk的唯一ID去重(离线处理时为每个chunk生成唯一ID),避免同一语料被BM25和KNN同时召回; 2. 初步排序:给两路召回结果赋初始权重(BM25得分0.4 + KNN相似度0.6),先做一次粗排(垂直领域语义更重要,所以KNN权重更高); 3. 截断:保留top100候选(既保证召回率,又控制后续Cross-Encoder的计算成本); 补充:权重比例是通过离线实验调优的——测试了0.3:0.7、0.4:0.6、0.5:0.5三组比例,最终0.4:0.6在召回率(>90%)和准确率上最优。
Cross-Encoder 重排是如何集成到流程中的?如何平衡性能?
集成方式(微服务架构): - 检索层(ES)返回top100候选后,调用“重排服务”(基于FastAPI封装Cross-Encoder); - 重排服务输入:用户问题 + 100条候选chunk;输出:按Cross-Encoder打分降序的top10 chunk; - 重排服务做了模型量化(INT8),部署在GPU上(batch推理),单条推理耗时从20ms降到5ms;
2性能平衡的关键优化: - 候选集截断:仅对召回的top100做重排,而非全量; - 模型轻量化:选用轻量版Cross-Encoder(如cross-encoder/ms-marco-MiniLM-L-6-v2),而非大模型; - 缓存:对高频问题(比如Top1000常见问题)的检索+重排结果做缓存(Redis),命中率约30%,整体响应时间从500ms降到200ms内。
准确率提升 25%” 是如何量化的?对比的基线是什么?
1.评测数据集:构建了垂直领域(比如医疗)的评测集,包含1000个真实用户问题 + 人工标注的“标准答案chunk”(每个问题对应3-5个核心chunk);
- 核心指标: - 检索准确率(Recall@10):检索结果中包含至少1个标准答案chunk的比例(核心指标,因为RAG的关键是召回正确语料); - 问答准确率:人工评估大模型生成回答与标准答案的匹配度(分为精准/部分/错误三档);
- 对比基线:仅用BM25检索的RAG流程; 4. 结果: - 基线:检索Recall@10=60%,问答准确率=65%; - 优化后:检索Recall@10=82%,问答准确率=81%(提升24.6%,约25%); - 同时,通过缓存/模型量化,系统响应时间控制在200ms内(满足线上要求的300ms阈值)。
KNN 向量检索的性能瓶颈是什么?你是如何优化的?
落地初期的瓶颈: 1. 向量索引构建耗时久(百万级chunk构建需数小时);
在线检索QPS低(单节点QPS仅50),延迟高(平均300ms); 优化手段: 1. 索引层面: - 向量维度优化:从1024维降到768维(通过领域微调验证,召回率仅下降1%,检索速度提升20%);
ES集群调优:增加分片数(按数据量设8分片),副本数1(兼顾高可用和检索性能),关闭刷新间隔(离线构建索引时);
工程层面: - 批量编码:离线语料向量化时用batch_size=64批量处理,提升编码效率; - 预热:上线前预热ES索引(提前查询),避免冷启动时的磁盘IO瓶颈; 最终:索引构建时间降到1小时内,在线检索QPS提升到200+,延迟降到80ms内。
落地过程中最大的挑战是什么?如何解决的?
最大挑战:Cross-Encoder重排后准确率提升,但系统响应时间从150ms涨到500ms,超出线上300ms的阈值。 分析过程:
拆解耗时:ES检索80ms + Cross-Encoder重排350ms + 大模型推理70ms → 重排是核心瓶颈; - 根因:用了全量Cross-Encoder(bert-base),单条推理20ms,100条候选就是2000ms(批量后仍350ms);
解决措施: 1. 模型轻量化:替换为MiniLM-L6版Cross-Encoder,推理耗时从20ms/条降到5ms/条;
- 候选集再压缩:基于“BM25+KNN”的粗排得分,将候选集从100条降到50条(验证召回率仅下降2%);
- 缓存高频问题:对Top1000高频问题的检索+重排结果缓存,命中率30%; 最终结果:重排耗时降到80ms,整体响应时间控制在200ms内,同时问答准确率仍保持提升25%的效果。
向量检索和 BM25 的结果冲突时(比如 KNN 认为相关,BM25 认为不相关),如何处理?
做了“场景化权重调整+人工规则兜底”:
- 基础规则:对含专业术语的问题(通过实体识别判断),提升BM25权重(比如0.5:0.5),保证术语精准匹配;对泛语义问题(比如“如何缓解高血压头晕”),提升KNN权重(0.3:0.7);
- 冲突过滤:如果某条候选在KNN中排前20,但BM25得分是0(完全无关键词匹配),或反之,会标记为“冲突候选”,仅保留前50%的冲突候选,避免低质量结果进入重排;
- 离线验证:定期分析冲突案例,迭代调整权重和规则(比如新增“实体匹配加分”规则),逐步降低冲突率(从15%降到5%)。
聊天助手Agent
构建基于 Elasticsearch 的 RAG 检索流⽔线,通过集成 KNN 向量检索与 BM25 关键词匹配实现多路召回, 并引⼊ Cross-Encoder 重排模型以优化语义对⻬精度,在平衡系统响应性能的同时将垂直领域问答准确率提 升25% 以上。
设计基于 LLM 的⾃适应检索模块,通过指代消解与语义扩展优化⾸轮意图识别;针对重排分数低于阈值的场 景,触发查询重写与回退机制,提升检索召回质量。同时集成⻆⾊与组织标签实现精细化权限管控,确保数据 隔离安全。
你设计的基于 LLM 的自适应检索模块整体架构是怎样的?核心流程是什么?
核心回答:
整体架构采用「意图理解层→检索召回层→重排过滤层→自适应优化层→权限管控层」的分层设计,核心流程如下:
- 首轮输入处理:用户查询进入后,先通过 LLM 完成「指代消解 + 语义扩展」,解决 “他 / 这个功能 / 上周的报表” 等指代模糊问题,同时扩展核心语义(如 “查销售数据” 扩展为 “查询 2024 年 Q2 华东区销售业绩报表 + 销售额 + 环比数据”);
- 基础检索:将优化后的查询送入向量库 + 关键词检索引擎,获取初始召回结果;
- 重排评分:通过 Cross-BERT 等模型对召回结果重排,输出重排分数;
- 自适应决策:若重排分数≥阈值,直接返回结果 + 权限过滤;若<阈值,触发「LLM 查询重写」生成 2~3 个改写查询,并行召回后再重排,若仍不达标则触发回退机制(降级为基础关键词检索 + 人工标注结果兜底);
- 权限管控:全流程嵌入角色 / 组织标签过滤,检索前过滤用户无权限的数据源,检索后过滤结果中敏感数据,最终返回符合权限的结果。
补充细节:模块采用 “LLM + 传统检索” 混合架构,既利用 LLM 的语义理解能力,又保留传统检索的高效性,同时通过「规则 + LLM」双校验保证意图识别的稳定性。
问题 2:指代消解和语义扩展具体是怎么做的?如何落地到首轮意图识别中?
核心回答:
(1)指代消解(解决首轮查询的模糊指代问题)
技术方案:采用「规则兜底 + LLM 精准消解」的混合策略:
规则层:基于依存句法分析(如 HanLP/LTP)识别代词(他 / 它 / 该 / 此)、省略成分,匹配上下文 / 领域词典(如 “报表” 关联 “销售报表 / 财务报表”);
LLM 层:设计专属 prompt,输入 “用户查询 + 对话上下文(若有)+ 领域实体库”,指令 LLM 输出 “消解后的完整查询 + 指代映射关系”,示例 prompt:
1
2
3任务:消解查询中的指代成分,输出完整无歧义的查询。
输入:用户查询=“把它发给我”,上下文=“用户此前询问2024年Q2销售报表”,领域实体库=[销售报表、财务报表、华东区业绩]
输出要求:完整查询+指代映射(如:完整查询=把2024年Q2销售报表发给我;指代映射=它→2024年Q2销售报表)
落地:首轮查询先过规则消解,若消解置信度<0.8,触发 LLM 消解,确保意图无歧义。
(2)语义扩展(解决首轮查询语义单薄问题)
技术方案:「静态扩展 + LLM 动态扩展」结合:
静态扩展:基于行业词库(如同义词林、上下位词库)扩展核心词(如 “查数据”→“查询 / 统计 / 导出 数据 / 报表 / 明细”);
LLM 动态扩展:输入消解后的查询,指令 LLM 生成 “用户可能想表达的 3 个相关查询”(避免过度扩展),示例:
1
2
3
4
5输入:查询=“查询2024年Q2华东区销售数据”
输出:
1. 查询2024年Q2华东区销售额及环比增长率
2. 导出2024年Q2华东区各省份销售明细报表
3. 统计2024年Q2华东区销售数据与Q1的对比
- 落地:将扩展后的语义融入检索查询向量,提升首轮召回的覆盖率。
问题 3:重排分数低于阈值时的查询重写和回退机制具体如何设计?
核心回答:
(1)查询重写机制(核心是 “精准改写 + 多策略备选”)
触发条件:重排分数<预设阈值(如 0.7,基于业务场景离线标定);
改写策略:
① 历史对话融合:LLM 结合多轮对话上下文,补充查询中缺失的上下文信息(如用户仅说 “再查一次”,改写为 “查询 2024 年 Q2 华东区销售数据并导出 Excel”);
② 关键词强化:提取原查询核心词,LLM 补充领域限定词(如 “查报表”→“查询 2024 年 Q2 华东区销售业绩报表”);
③ 句式转换:将口语化查询转为检索友好型(如 “为啥销售数据低”→“查询 2024 年 Q2 华东区销售数据偏低的原因”);
执行逻辑:LLM 生成 2~3 个改写查询,并行送入检索引擎,取各改写查询召回结果的并集,再统一重排。
(2)回退机制(保证服务兜底能力)
触发条件:查询重写后的重排分数仍<阈值;
回退策略:
① 降级为 “关键词精准检索”:仅保留原查询核心词(去除扩展词),避免过度泛化;
② 兜底到人工标注结果:调取该类查询的人工标注高频结果,补充到召回列表;
③ 反馈提示:返回结果时附带 “是否想查询 XXX?” 的引导式提示,引导用户明确意图。
问题 4:LLM 改写引入的耗时增加,你是怎么优化的?
核心回答:
针对 LLM 改写带来的耗时(单轮 LLM 调用约 200~500ms),从「链路优化、资源优化、策略优化」三个维度解决:
链路优化:异步 + 缓存 + 并行
- 异步处理:将 LLM 改写与基础检索并行执行(基础检索约 50ms),若基础检索重排分数达标,直接终止 LLM 改写流程;
- 缓存策略:对高频查询 / 改写结果做两级缓存(本地缓存 + Redis),缓存 Key 为 “用户查询 + 角色标签”,缓存有效期 1 小时(按业务更新频率调整),命中率可达 60%+,直接跳过 LLM 改写;
- 批量改写:将多个低分数查询打包,一次性发送给 LLM,减少调用次数(如每 100ms 批量一次,耗时摊薄至单查询 50ms 内)。
资源优化:LLM 轻量化 + 部署优化
- 模型选型:首轮意图识别 / 指代消解用轻量开源模型(如 ChatGLM-6B、Qwen-7B),部署为量化版(4bit/8bit),推理耗时从 500ms 降至 150ms;
- 部署架构:LLM 服务采用 “主从架构”,主模型处理复杂改写,从模型处理简单指代消解,负载均衡分流。
策略优化:动态阈值 + 分级改写
- 动态阈值:基于用户场景(如普通用户阈值 0.7,管理员阈值 0.6)、查询类型(如简单查询阈值 0.8,复杂查询阈值 0.6)动态调整,减少不必要的改写触发;
- 分级改写:简单查询用规则改写(耗时<10ms),仅复杂查询触发 LLM 改写,降低 LLM 调用占比。
效果:优化后整体检索链路耗时从平均 800ms 降至 200ms 内,满足线上服务 P99<500ms 的要求。
问题 5:角色与组织标签如何集成到检索模块,实现精细化权限管控和数据隔离?
核心回答:
采用「标签打标 + 全流程过滤」的方案,确保 “数据能检索到的前提是用户有权限”,核心流程:
标签体系设计:
- 维度:角色标签(普通用户 / 管理员 / 财务)+ 组织标签(华东区 / 华北区 / 总部)+ 数据标签(公开 / 部门级 / 公司级);
- 打标方式:数据源入库时,通过 LLM + 规则自动打标(如 “华东区销售数据” 打标:组织 = 华东区、数据级别 = 部门级),人工审核兜底。
全流程权限过滤:
- 检索前过滤:用户发起查询时,先解析用户的角色 / 组织标签,生成 “权限过滤条件”(如华东区普通用户→仅能检索 “组织 = 华东区 + 数据级别≤部门级” 的数据源),过滤掉无权限的数据源,减少检索范围;
- 检索后过滤:对召回结果做二次校验,LLM 识别结果中的敏感数据(如跨组织数据),自动屏蔽 / 脱敏;
- 权限缓存:将用户权限标签缓存至本地,避免每次检索都查询权限系统,提升效率。
安全兜底:
- 审计日志:记录用户检索的数据源、结果、权限匹配情况,便于追溯;
- 熔断机制:若权限服务异常,直接返回 “权限验证失败”,避免数据泄露。
问题 6:自适应检索模块如何支撑多轮对话场景?
核心回答:
多轮对话的核心是 “上下文有效融合 + 意图漂移修正”,模块通过 3 个关键点支撑:
- 上下文管理:维护「用户会话上下文窗口」(最多保留最近 5 轮对话),并通过 LLM 做上下文摘要(避免窗口过长),摘要内容包含 “核心意图 + 已获取信息 + 待解决问题”;
- 多轮指代消解:首轮消解的基础上,每轮对话都将 “当前查询 + 上下文摘要” 送入 LLM,消解跨轮指代(如用户第 3 轮说 “它的环比呢?”,消解为 “2024 年 Q2 华东区销售数据的环比增长率呢?”);
- 意图漂移修正:若 LLM 检测到用户意图漂移(如从 “查销售数据” 变为 “查成本数据”),则重置检索策略(重新语义扩展 + 检索);若意图未漂移(仅补充信息),则复用历史检索结果,仅做局部改写。
问题 7:怎么衡量这个模块的优化效果?有哪些核心指标?
核心回答:
从「效果 + 性能 + 体验」三个维度设计指标,核心指标及优化效果如下:
| 维度 | 核心指标 | 优化前 | 优化后 |
|---|---|---|---|
| 效果 | 首轮意图识别准确率 | 75% | 92% |
| 检索召回率(Top20) | 68% | 85% | |
| 重排分数达标率 | 70% | 88% | |
| 性能 | 检索链路平均耗时 | 800ms | 200ms |
| LLM 调用占比 | 100% | 40% | |
| 体验 | 用户二次提问率 | 35% | 12% |
| 权限违规访问拦截率 | 90% | 100% |
补充:通过 A/B 测试验证效果,实验组为 “自适应检索模块”,对照组为 “传统检索”,持续监控指标并迭代阈值 / 改写策略。
二、核心难点及解决方案
| 核心难点 | 具体解决方案 |
|---|---|
| 1. 首轮意图识别的准确性(指代消解歧义、语义扩展过度 / 不足) | ① 规则 + LLM 双校验指代消解,设置消解置信度阈值;② 语义扩展限制数量(3 个以内),结合领域词库避免过度扩展;③ 离线标注意图样本,微调 LLM 提升行业适配性 |
| 2. LLM 改写的耗时与召回质量平衡 | ① 异步并行执行 LLM 改写与基础检索;② 高频查询缓存改写结果;③ 轻量 LLM 模型 + 批量调用降低耗时;④ 动态阈值减少不必要改写 |
| 3. 多轮对话上下文融合(意图漂移、上下文冗余) | ① 上下文摘要压缩窗口长度;② LLM 检测意图漂移并重置检索策略;③ 跨轮指代消解结合上下文摘要,保证意图连贯 |
| 4. 细粒度权限管控与检索性能的平衡 | ① 检索前过滤无权限数据源,减少检索范围;② 缓存用户权限标签,避免重复查询;③ 规则 + 轻量化 LLM 做检索后过滤,替代全量 LLM 校验 |
| 5. LLM 服务抖动 / 失败对检索链路的稳定性影响 | ① 设计降级策略:LLM 服务异常时,自动切换为 “规则改写 + 传统检索”;② 多 LLM 实例容灾,主实例故障自动切从实例;③ 超时控制(LLM 调用超时 100ms 则终止) |
| 6. 查询重写的有效性(改写后召回结果仍不达标的情况) | ① 离线构建改写模板库,LLM 基于模板生成改写查询;② 对改写结果做 “有效性预校验”(匹配核心词 / 领域词),无效则重新改写;③ 回退机制兜底,保证基础召回能力 |
统一多源文档格式
票据,扫描件,手写,文件里的嵌入表格和数学公式
Word文件
文档格式.doc,docx,是Word文档的OPen XML格式.
块的分布 块与块之间的关系

文档解析工具
python-docx,langchain document loader,springlangchain4j,spring ai
文档解析逻辑
文字通过库直接解析,图片使用路径表示1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73def parse_docx(self, docx_path):
doc = DocxDocument(docx_path)
content = []
image_map = self._extract_images_from_docx(doc)
def parse_paragraph(paragraph):
def append_image_link(image_id, has_drawing, target_buffer):
"""Helper to append image link from image_map based on relationship type."""
rel = doc.part.rels[image_id]
if rel.is_external:
if image_id in image_map and not has_drawing:
target_buffer.append(image_map[image_id])
else:
image_part = rel.target_part
if image_part in image_map and not has_drawing:
target_buffer.append(image_map[image_part])
def process_run(run, target_buffer):
# Helper to extract text and embedded images from a run element and append them to target_buffer
if hasattr(run.element, "tag") and isinstance(run.element.tag, str) and run.element.tag.endswith("r"):
# Process drawing type images
drawing_elements = run.element.findall(
".//{http://schemas.openxmlformats.org/wordprocessingml/2006/main}drawing"
)
has_drawing = False
for drawing in drawing_elements:
blip_elements = drawing.findall(
".//{http://schemas.openxmlformats.org/drawingml/2006/main}blip"
)
for blip in blip_elements:
embed_id = blip.get(
"{http://schemas.openxmlformats.org/officeDocument/2006/relationships}embed"
)
if embed_id:
rel = doc.part.rels.get(embed_id)
if rel is not None and rel.is_external:
# External image: use embed_id as key
if embed_id in image_map:
has_drawing = True
target_buffer.append(image_map[embed_id])
else:
# Internal image: use target_part as key
image_part = doc.part.related_parts.get(embed_id)
if image_part in image_map:
has_drawing = True
target_buffer.append(image_map[image_part])
# Process pict type images
shape_elements = run.element.findall(
".//{http://schemas.openxmlformats.org/wordprocessingml/2006/main}pict"
)
for shape in shape_elements:
# Find image data in VML
shape_image = shape.find(
".//{http://schemas.openxmlformats.org/wordprocessingml/2006/main}binData"
)
if shape_image is not None and shape_image.text:
image_id = shape_image.get(
"{http://schemas.openxmlformats.org/officeDocument/2006/relationships}id"
)
if image_id and image_id in doc.part.rels:
append_image_link(image_id, has_drawing, target_buffer)
# Find imagedata element in VML
image_data = shape.find(".//{urn:schemas-microsoft-com:vml}imagedata")
if image_data is not None:
image_id = image_data.get("id") or image_data.get(
"{http://schemas.openxmlformats.org/officeDocument/2006/relationships}id"
)
if image_id and image_id in doc.part.rels:
append_image_link(image_id, has_drawing, target_buffer)
if run.text.strip():
target_buffer.append(run.text.strip())
dify中word提取逻辑,Word 文档(.docx)本质上是一个压缩的 XML 文件。D通过解析这些底层的 XML 标签来重构表格和布局。
- 图片转存逻辑
- 处理位置:
_extract_images_from_docx(self, doc)方法。 - 具体细节:
- 它遍历
doc.part.rels(文档关系表)。 - 如果是内部图片,直接读取
rel.target_part.blob。 - 如果是外部图片 URL,使用
ssrf_proxy.get(url)下载(重点:通过代理下载以防止 SSRF 攻击)。 - 存储与映射:调用
storage.save()将图片存入系统,并向数据库UploadFile表写入记录。最后返回image_map,其 Key 是图片在 XML 中的 ID,Value 是 Markdown 格式的链接:。
- 它遍历
- 表格转 Markdown 逻辑
- 处理位置:
_table_to_markdown(self, table, image_map)及其调用的_parse_row和_parse_cell。 - 具体细节:
- 对齐处理:计算表格的最大列数
total_cols。 - 格式构造:手动拼接 Markdown 的分隔符
| --- |。 - 单元格合并处理:在
_parse_row中,通过cell.grid_span获取单元格跨越的列数,确保合并单元格在 Markdown 转换后不会导致列偏移,保持数据结构的对齐。
- 对齐处理:计算表格的最大列数
- 复杂文本与链接提取
- 处理位置:
parse_paragraph(在parse_docx内部定义的函数)。 - 具体细节:
- 普通文本:遍历
run.text。 - 现代超链接:处理
w:hyperlink标签。 - 旧式超链接 (Field):这是最难处理的部分,代码通过正则匹配
HYPERLINK "url"并结合w:fldChar(字段开始/分隔/结束状态机)来提取那些隐藏在 Word 指令字段中的链接。
- 普通文本:遍历
直接提取纯文本会丢失表格的行级/列级对应关系。转换为 Markdown 后,大模型能够通过分隔符明确识别表格数据的关联性,减少幻觉。
实际研发场景中,使用 Document Loader 文档加载器模块时,需要根据具体的业务需求编写自定义的文档后处理逻辑。针对业务需求,开发者可以自行编写和实现对不同文档内容的解析,例如对标题、段落、表格、图片等元素的特殊处理。
PDF解析
尽管PDF文件的内容在表达图像、文字和表格信息,但其本质上是一系列显示和打印指令的集合。,即使是一个仅包含 “Hello World” 文字的简单PDF,其文件内容也是一长串的打印指令。

PDF文件的显示效果不受设备、软件或系统的影响,但对计算机而言,它是一种非数据结构化的格式,储存的信息无法直接被理解。此外,大模型的训练数据中不包含直接的PDF文件,无法直接理解。
PDF解析,对于纯文本格式可以转换为文本字符串,而对于包含多种元素的复杂格式,选择 MarkDown 文件作为统一的输出格式最为合适。这是因为MarkDown文件关注内容本身,而非打印格式,能够表示多种文档元素内容。MarkDown格式被广泛接受于互联网世界,其信息能够被大模型理解。
PDF文件分为电子版和扫描版。PDF电子版可以通过规则解析,提取出文本、表格等文档元素。目前,有许多开源库可以支持,例如 pyPDF2、PyMuPDF、pdfminer、pdfplumber和papermage 等。这些库在 langchain_community.document_loaders 中基本都有对应的加载器,方便在不同场景下切换使用。
在基于规则的开源库中,pdfplumber对中文支持较好,且在表格解析方面表现优秀,但对双栏文本的解析能力较差;pdfminer和PyMuPDF对中文支持良好,但表格解析效果较弱;pyPDF2对英文支持较好,但中文支持较差;papermage集成了pdfminer和其他工具,特别适合处理论文场景。开发者可以根据实际业务场景的测试结果选择合适的工具,pdfplumber或pdfminer都是当前不错的选择。
扫描版PDF
PDF扫描版需要经过文本识别和表格识别PDF扫描图像,才能提取出文档中的各类元素。同时要真正实现文档解析的目标,无论扫描版还是电子版均需进行版面分析和阅读顺序的还原,将内容解析为一个包含所有文档元素并且具有正确阅读顺序的MarkDown文件。单纯依赖规则解析是无法实现这一目标的.
目前支持这些功能的多为基于深度学习的开源库,如 Layout-parser、PP-StructureV2、PDF-Extract-Kit、pix2text、MinerU、marker等。
由于PDF文档解析整体流程用到了多个深度学习模型组合,真正在生产场景中会遇到效率问题。商业闭源库由于其部署的云端集群可以做并行处理和工程效率优化,所以在精度和效率上都能做到生产中的级别,比如TextIn.com、Doc2x、mathpix、庖丁PDFlux、腾讯云文档识别等,当然商业库会存在成本问题,你可以按需选择。
PDF内容提取逻辑,参考dify
- 图片格式识别(Magic Bytes)
- 实现位置:类属性
IMAGE_FORMATS和_extract_images内部。 - 逻辑:代码通过检查文件头的“魔数”(Magic Bytes)来精准识别图片格式(如 JPEG 的
\xff\xd8\xff,PNG 的\x89PNG),而不是简单依赖文件后缀。这保证了即使 PDF 内部图像流没有明确标签,也能正确保存为.jpg或.png。
- 图像转存与持久化
- 处理位置:
_extract_images(self, page)。 - 具体细节:
- 对象过滤:使用
filter=(pdfium_c.FPDF_PAGEOBJ_IMAGE,)仅提取页面中的图像对象。 - 二进制提取:调用
obj.extract()。注意其中的fb_format="png",这意味着对于非 JPEG 格式的图像,代码会自动将其回退(Fallback)并渲染为 PNG 格式以保证兼容性。 - 存储与数据库:图片字节流被存入
storage,同时向UploadFile数据库表写入元数据。返回的 Markdown 链接允许前端或大模型直接通过 URL 预览提取到的图片。
- 对象过滤:使用
- 内存与资源管理
- 处理位置:
parse方法中的finally块及autoclose=True。 - 逻辑:代码显式调用
text_page.close()、page.close()和pdf_reader.close()。在处理包含数千张图片的 PDF 时,及时释放 C 级底层的 PDF 句柄是防止内存泄漏的关键。
优化解析逻辑
布局恢复:目前提取的是“平铺”文本,PDF 中的多栏布局或页眉页脚可能会混入正文。可以考虑引入 pypdfium2 的坐标分析功能来过滤页眉页脚,或者使用OCR提取布局信息。
表格识别: pdf底层存储的是字符及其坐标,需要通过定位页面中的表格区域。尝试理解表格的行列逻辑,并将其转换为标准的 Markdown 表格格式(|---|)。结合布局分析和表格重建 infiniflow/ragflow
OCR 介入:如果 PDF 是扫描件(图片生成的 PDF),get_text_range() 将返回空。此时应触发 OCR 流程对提取出的图片进行二次文字识别。
表格识别:引入OCR
采取 “混合解析策略”:
- 预判断:先尝试用
pypdfium2读取文本,如果返回字符数极少,判定为扫描件,触发 OCR。 - 工具选型:
- 追求开源/本地部署:集成
Marker或Unstructured库。 - 追求极致效果:使用多模态 API(如 GPT-4o-mini)专门处理表格页。
- 追求开源/本地部署:集成
- 标准化输出:无论后端用什么工具,统一输出为 Markdown,因为这能最大程度保留表格的语义逻辑供大模型检索。
推荐工具对比:
| 需求场景 | 推荐工具 | 集成难度 |
|---|---|---|
| 追求极致速度 | 维持现状 (pypdfium2) | - |
| 精准处理多栏/论文 | 集成 Marker | 中(需要额外 Python 依赖) |
| 完美还原复杂表格 | Unstructured + PaddleOCR | 高(环境配置较复杂) |
| 万能适配 | 多模态 LLM 视觉解析 | 低(仅需 API 调用) |
在Marker中,使用深度学习模型和启发式算法来解析PDF中的多栏布局和表格。多栏文本通过TextProcessor检测和合并,表格通过TableProcessor进行结构化提取,并可选择性使用LLM增强准确性
开源系统不支持的文件类型
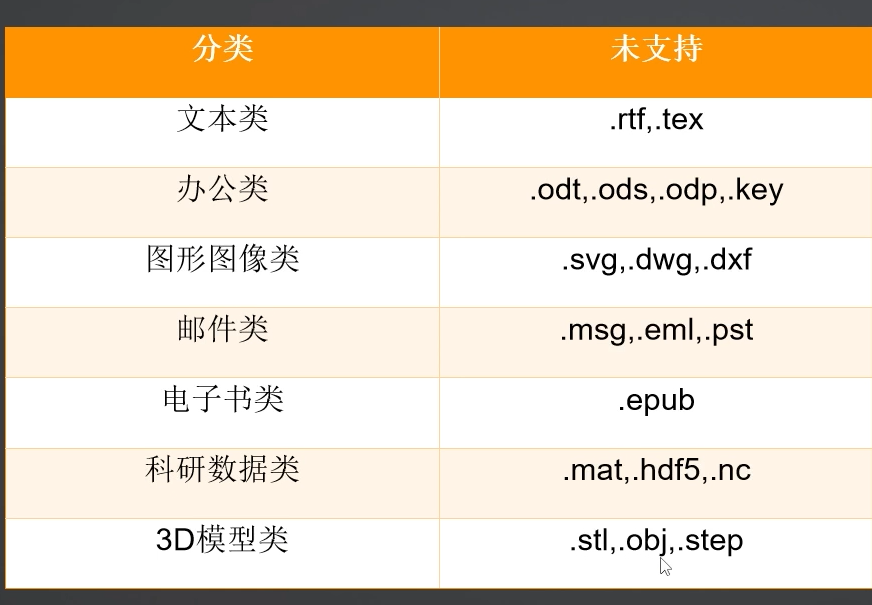

难点
跨页表格怎么自动对齐
在处理 PDF 解析时,跨页表格(Multi-page Tables)是最具挑战性的场景之一。由于 PDF 在分页处会强制打断表格结构,并可能插入页眉、页脚或重复表头,简单的流式提取会导致表格断裂或数据错位。
关键技术方案
表头一致性,判断是否为同一张表的重复表头
表格位置分析,判断相邻页中的表格是否在文档布局中连续
自动拼接与去重,对于相同表头的多个分页表格,按行拼接,并去除重复的表头行
- 布局检测
mineru
- 文档格式检测
- 文档格式识别
- OCR处理
- 表格预测
数据预处理

构建领域术语词库,识别输入中领域术语,替换
术语混淆直接影响信息检索的精确度与生成内容质量.
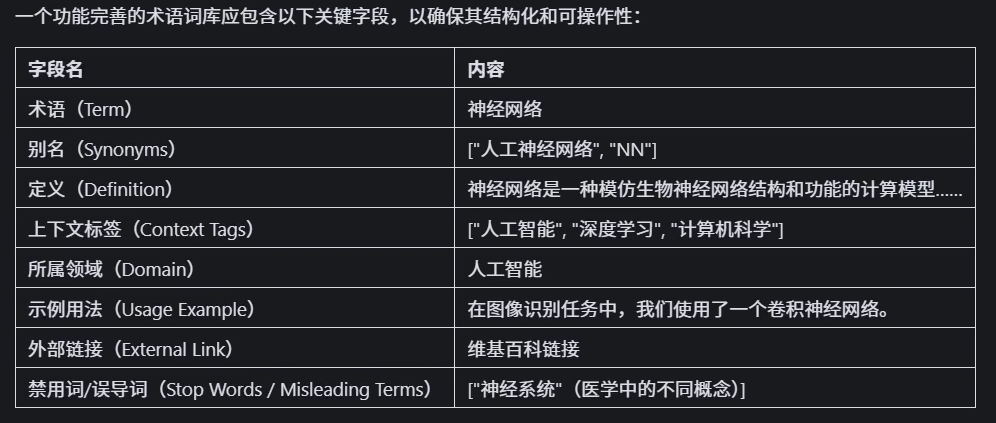
术语词库构建与维护
产生术语混淆
术语多义性,同义词,领域差异以及企业专属术语
术语词库构建流程
- 收集术语来源
- 标准化术语
- 建立别名映射关系
- 添加上下文信息
- 构建术语索引
术语词库与RAG集成
方式1:预处理阶段替换术语
方式2:检索增强
方式3:重排序
方式4:后处理解释
维护术语词库
分块策略与Embedding技术

数据分块(Chunking/切片) 的质量直接决定了检索的精准度。如果切片太小,会丢失上下文;如果切片太大,会引入噪声并稀释语义。
Token-based chunking TokenTextSplitter 严格限制模型窗口时物理边界控制精准
SentenceSplitter 通用文本文档语义保真度高,配置简单 目标是在保持语义完整性的前提下,尽可能按句子边界切分。
工作原理:它会尝试按照段落 (\n\n)、换行 (\n)、句子、单词的优先级递归切分。
核心作用:它能确保切片不会在句子中间断开。
关键参数:chunk_size(块大小)和 chunk_overlap(重叠大小)。
窗口切分, SentenceWindowNodeParser
| 文档类型 | 推荐切片类 (LlamaIndex) | 选择理由 |
|---|---|---|
| 标准说明书/公文 | SentenceSplitter | 段落结构清晰,按句子切分能最大程度保留语义。 |
| README/技术手册 | MarkdownNodeParser | 强推。 必须按 H1-H3 标题切分,否则正文会脱离标题,导致检索到正文却不知道在说哪个产品。 |
| 代码库 (Python/JS) | CodeSplitter | 依据语法树(AST)切分,保证一个函数或一个类在一个 Chunk 里。 |
| 扫描件/复杂 PDF | SemanticSplitter | 慎用。 建议先用 Marker 转为 Markdown,再用 MarkdownNodeParser 处理。 |
“全家桶”组合 通常是:
- MarkdownNodeParser(用于格式化内容)
- SentenceSplitter(作为 fallback 处理长段落)
- MetadataExtractor(注入标题和上下文)
- RedisCache(放在 IngestionPipeline 里加速重复解析
滑动窗口切分=sentenceSplitter+SentenceWindowSplitter
滑动窗口
滑动窗口结合关键词
- 初步切片,使用滑动窗口对文档进行基础分段
- 关键词检测,分析每个切片的边界,识别是否存在关键词或语义单元的中断
- 动态调整,根据关键词位置和上下文语境,微调切片边界,确保语义完整
语义切分

SemanticSplitter 的工作逻辑可以分为以下四个步骤:
- 句子分割:首先将原始文档拆分成一个个基础的句子。
- 向量化(Embedding):利用 Embedding 模型将每个句子(或句组)转化为高维向量。
- 计算相似度:计算相邻句子之间的余弦相似度(Cosine Similarity)。
- 设定阈值(Threshold):
- 如果相邻两句的意思非常接近,它们会被合并在同一个块(Chunk)里。
- 如果相似度突然下降,超过了设定的阈值,系统就认为“话题发生了转换”,并在此处建立切片断点。
1 | from llama_index.core.node_parser import SemanticSplitterNodeParser |
动态切片策略与重叠机制
RecursiveTextSplitter(递归字符切片器)是 RAG 开发中最常用、也是性价比最高的文本切片工具。它被广泛集成在 LangChain 等框架中,旨在解决简单字符切片容易“切断语义”的问题。
它的核心理念是:尽可能保持段落、句子和词语的完整性。
RecursiveTextSplitter 维护了一个分隔符列表(默认通常是 ["\n\n", "\n", " ", ""])。其工作流程如下:
- 段落切分:首先尝试用双换行符
\n\n(段落边界)来切分文档。 - 检查大小:如果切出来的块小于设定的
chunk_size,则保留。 - 降级递归:如果某个块仍然超过了
chunk_size,它会针对这个超长的块,换用下一个分隔符(如单换行符\n)继续尝试切分。 - 最小单位:如果连换行符切完都太大,它会寻找空格
" "(单词边界)。如果连空格都解决不了(比如一个极长的化学单词),最后才会按字符""强制切断。
结构化文档失效:如果你处理的是 Markdown(带有很多 # 标题)或代码,普通的递归切片可能会切断标题和正文的联系。此时应该使用专用的 MarkdownHeaderTextSplitter 或 CodeSplitter。
不识别语义转折:它只看物理符号(如换行符),不看意思。如果一个段落里讨论了两个完全不同的主题,它还是会把它们放在一起。这种情况需要 SemanticSplitter。
TopicNodeParser
命题化检索
TopicNodeParser 通常利用 LLM 或高精度的 Embedding 模型来识别文档中的“话题转换点”(Topic Drift)。
其工作流程通常如下:
- 初始分割:将文档初步拆分为较小的单元(如句子或短段落)。
- 主题建模/识别:
- 方法 A(LLM 驱动):让 LLM 扫描文本块,判断:“这里是否开启了一个新话题?”
- 方法 B(语义聚类):计算连续块之间的相似度,当相似度曲线出现“断崖式”下跌时,判定为主题切换。
- 节点构建:将属于同一个主题的所有文本块合并为一个
Node,并自动为该 Node 提取一个主题标签(Topic Label)作为元数据。
上下文割裂:一个关于“安装步骤”的描述可能被切成了两半,检索时只搜到后半部分,导致步骤缺失。
语义混杂:一个 1024 Token 的块里,前一半在说“硬件规格”,后一半在说“软件配置”,这会导致该块的向量表征变得“平庸”,检索相关度下降。

Dify中的父子模式
在普通的切片模式下,开发者常面临一个“鱼与熊掌不可兼得”的困局:
- 分段太小:检索非常精准(向量表征集中),但由于上下文(Context)太少,LLM 回答时容易断章取义。
- 分段太大:包含了足够的背景,但一个段落里讲了三个主题,导致向量表征模糊,搜索时很难排在前面。
父子模式的对策:将原本的大段落(父)进一步拆解为多个小片段(子)。
工作原理
存储阶段:
- 父分段 (Parent):通常是较长的文本块(如 1000 Tokens),保留了完整的逻辑和上下文。
- 子分段 (Child):将父分段进一步切碎(如 200 Tokens)。
- 数据库关联:系统在向量数据库中索引“子分段”,但每一个子分段都关联着其对应的“父分段” ID。
- 检索阶段:
- 用户提问后,系统去匹配最相关的子分段。
- 还原阶段(关键步):
- 一旦命中了某个子分段,Dify 不会将子分段的内容发给 LLM,而是自动根据关联 ID,找回它所属的父分段内容。
- 生成阶段:
- LLM 接收到的是语义丰富的父分段,从而能根据完整的背景生成高质量答案
开启“父子模式”通常需要调整以下参数:
- 父分段规则:设定父块的大小(建议 800-1000 字符)。
- 子分段规则:设定子块的大小(建议 200-300 字符)。
- 检索策略:
- 通常配合混合检索(Hybrid Search)使用,即:子分段的向量检索 + 全文检索。
适用文档:逻辑严密但篇幅较长的文档,如法律条文、技术规范、深度行业报告。
配合 Rerank:在父子模式下,强烈建议开启 Rerank(重排序)。因为子块召回可能较多,通过 Rerank 选出最准确的子块对应的父块,能显著降低 Token 消耗并提升准确度。

传统的 RAG 工具(如 LangChain 或 Dify 默认模式)往往采用“一刀切”的规则来切片,而 RAGFlow 的模板化逻辑是:先看文档长什么样,再决定怎么拆。
不同的文档有完全不同的逻辑结构。如果用同一种算法去切,会发生以下惨剧:
- 财务报表:表格被拆散成一堆毫无意义的数字。
- 科研论文:双栏排版的文字被横向读取,左右两栏混在一起。
- 调查问卷:问题和选项被强行切断。
RAGFlow 的模板化方案:预设了多种针对特定场景的解析逻辑,确保数据从 PDF/Word 转化为数据库向量时,逻辑依然是完整的。
RAGFlow 提供了多种内置模板,每种模板背后都有一套专门的布局识别(Layout Analysis)算法
切片的核心作用:为后续混合检索,重排,查询转换等提供高质量数据
最后也需要构建评估体系,持续验证与迭代优化
检索增强阶段
在初步召回的基础上,进一步优化检索结果的广度与精度.

查询扩展与重写
生成 3 到 5 个不同表述但语义相同的查询变体。这些变体应从不同的侧重点出发,帮助从向量数据库中找回最相关的文档。其核心依据是语义向量空间的不确定性。
利用大语言模型(LLM)将用户的一个问题转化为多个语义相似但措辞不同的问题,然后分别进行检索。
传统的向量检索(Vector Search)高度依赖用户输入的措辞。
- 痛点:如果用户的问题和文档中的词汇不匹配,或者提问比较模糊,向量空间中的距离可能较远,导致检索不到核心内容。
- 例子:用户问“如何对齐 PDF 表格?”,文档里写的可能是“PDF 表格解析与重组方案”。两者字面上不完全一致。
- 查询生成:LLM 接收原始问题,生成 3-5 个不同角度的变体(例如:“PDF 表格错位怎么处理?”、“PDF 跨页表格对齐技术”等)。
- 并行检索:将这多个问题同时发给向量数据库,每个问题都会召回一批文档。
- 取并集(Union):将所有问题召回的文档汇总在一起。
- 去重与排序:剔除重复文档,最后将这组更全面的文档交给 LLM 生成答案
假设性文档HyDE
核心思想是与其直接用“问题”去搜答案,不如先让 AI 编一个“假答案”,然后用这个“假答案”去搜“真文档”。
在传统的向量检索中,我们计算的是 问题(Query) 和 文档(Document) 之间的相似度。
- 痛点:问题通常很短(如“HyDE 是什么?”),而文档通常很长且充满细节。在向量空间里,短问题和长文档的特征向量往往不对称,导致检索不到最相关的片段。
- HyDE 的逻辑:文档和文档之间是最像的。
- 生成假设文档:接收用户的问题,让 LLM(如 GPT-4)在不看任何外部资料的情况下,凭直觉写一篇“伪文档”或“假设性回答”。
- 向量化(Embedding):将这篇逻辑通顺但内容可能不准确的假设文档转化成向量。
- 检索真文档:用这个“伪向量”去数据库里匹配物理特征最接近的真实文档。
- 生成最终答案:把检索到的真文档喂给 AI,生成正式的回复。
OCR文件错漏
OCR识别错误可以分为:
字符识别错误,文字遗漏,多字重复,格式混乱
在OCR之前可以及逆行文本图像校正,纠正图像中文档扭曲,倾斜,透视变形等问题,另外进行版面区域检测,对文档图像进行内容解析和区域划分
识别后的内容可以通过LLM修正
生成控制与验证阶段

向量检索引擎
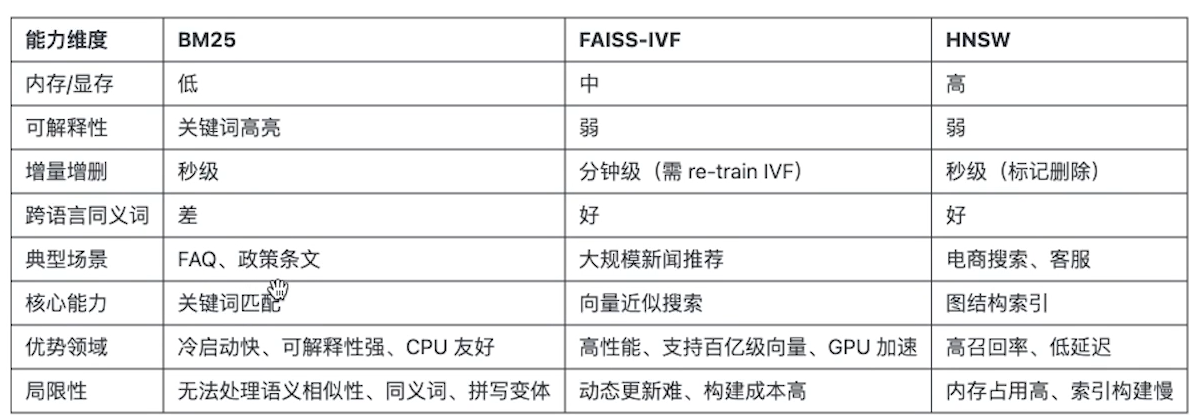
BM25是改进的TF-IDF排序,通过词频,文档长度归一化以及逆文档频率加权.
设计混合检索架构提高多阶段召回率
让AI返回结构化数据
Structured Generation with LLM,是指让LLM按照预先定义的schema,输出符合schema的结构化结果。
常见的应用场景有:
- 数据处理。主要功能为a -> b,即从源文本中抽取/生成符合schema的结果,例如给定新闻,进行分类、抽取关键词、生成总结等;
- Agent。主要功能是Tool Calling,即根据用户query,选择适当的tool和入参
如何从模型输出中准确提取自己所需的信息。例如,当我们希望模型输出 JSON 格式的数据时,由于模型生成的内容并不总是稳定,可能需要额外编写大量的正则表达式来匹配并提取其中的有效信息。然而,由于 LLM 的能力,导致其输出结构并不永远可靠。
现阶段, 让LLM按要求生成特定格式文本的主要方法有几种种:
- 微调:使模型的输出遵循特定格式
- OpenAI Json-mode/function-calling/Structured Outputs: 这些功能允许模型生成更严格、结构化的输出,但受限于openAI平台。
- 格式约束:在decoding阶段进行约束,限制模型的输出,
- Prompt Engineering: 最简单的办法,但不稳定。
- 多阶段prompting: 通过多个步骤的提示逐步引导模型生成所需的格式
- 提示词工程(Prompt Engineering)
这是最基础的方式,通过在 System Prompt 中明确要求 AI 返回特定的格式。
- 实现方式:在提示词末尾加上
“请以 JSON 格式返回结果,不要包含任何多余的解释文字”,并给出示例。 - 优点:
- 低成本:不需要额外的 API 参数或编程逻辑。
- 灵活性高:可以随时调整字段定义。
- 缺点:
- 不稳定:AI 可能会在 JSON 前后加上“好的,这是你要的结果”等废话(俗称 Chatty AI)。
- 解析失败:长文本下可能会出现 JSON 语法错误(如少个括号、引号未转义)。
Kor技术
使用Kor 进行structured generation的流程如下:
- 定义schema,包括结构、注释还有例子;
- Kor用特定的prompt template,将用户提供的schema和待处理的raw text,组装成prompt;
- 将prompt发送给LLM,借助其通用的In Context Learning能力,尽量生成符合schema的内容;
Kor对LLM的输出进行parse,返回符合schema的结构化结果,但也有概率没有返回(当LLM的输出不符合schema时)。
JSON Mode(JSON 模式)
主流模型(如 GPT-4、Gemini 1.5、Claude 3)都提供了专门的开关。
- 实现方式:在调用 API 时设置
response_format: { "type": "json_object" }。 - 优点:
- 格式强制:模型会确保输出是一个合法的 JSON,极大地减少了解析错误。
- 缺点:
- 不保证内容 Schema:虽然它是 JSON,但字段名可能会随机变化(比如这次叫
name,下次叫user_name)。 - 仍需引导:通常还是需要在 Prompt 中提示它是 JSON,否则模型可能不知道该写什么。
- 不保证内容 Schema:虽然它是 JSON,但字段名可能会随机变化(比如这次叫
仅特定模型和平台支持,需要在prompt中要求输出json格式,不能保证完全按要求的格式结构输出,Json-Mode 更多是对于输出json的格式进行检查.JSON Mode 的实现原理是受限解码,核心不是让模型“学会”写 JSON,而是在它每产生一个 Token 时,通过一个外部过滤器(Filter)强行剔除掉会导致语法错误的选项。
- 函数调用 / 工具调用(Function Calling / Tool Use)
这是目前最推荐、生产环境最常用的方式。
- 实现方式:预先定义一个函数的参数结构(通常使用 JSON Schema),AI 不直接回答问题,而是通过“调用函数”来填充这些参数。
- 优点:
- 强类型约束:严格遵循你定义的字段名和数据类型。
- 逻辑解耦:AI 负责提取信息,你的代码负责处理提取后的数据。
- 缺点:
- 延迟略高:模型需要额外的思考步骤来决定调用哪个函数。
- 成本:复杂的函数定义会占用更多的输入 Token。
Function Calling是构建agent的基石,也是各大LLM厂商的标配功能。要做到好的FC,LLM要能做到:
- 理解任务与function/tool的关系,知道是否要调用、需调用哪些function/tool、是否缺必要参数;
- 返回结构化内容,包括function name、arguments(json格式)
| 特性 | 普通 Prompt | JSON Mode | Function Calling |
|---|---|---|---|
| 约束目标 | 语义理解(靠 AI 配合) | 语法合规(保证是 JSON) | Schema 合规(保证字段对齐) |
| 字段准确度 | 差,经常乱起名 | 中,字段可能多写或漏写 | 极高,严格遵循定义 |
| 复杂结构 | 难以处理深层嵌套 | 较好 | 完美,支持复杂递归嵌套 |
| 稳定性 | 易受 Prompt 干扰 | 较稳 | 工业级稳定 |
Mistral模型的开源FC实现
mistral-nemo这样实现FC:
- 将tools按照特定的template,组装到prompt中去;
- LLM输出时,也遵循特定的template,call tool时加入特殊标记(TOOL_CALLS),并返回name和arguments。
mistral-nemo在fine-tuning时,按照这样的格式进行训练,FC的“要求”已经被encode到模型的参数中去了;
- 结构化输出(Structured Outputs)
很多开发者会用 Function Calling 来实现结构化输出(即使他们并不打算真的调用函数)。
- 原因:早期的模型不支持独立的 Structured Output 模式,但 Function Calling 训练得非常成熟,能极稳地吐出 JSON 参数包。
- 现状:现在像 OpenAI 的 Structured Outputs 已经是这两者的结合体——它既可以用在普通的回复里,也可以用在函数调用的参数提取里,保证 100% 的字段匹配。
这是 OpenAI 等厂商近期推出的最高级别约束方案。
- 实现方式:在 API 请求中提供具体的
json_schema,并开启strict: true模式。 - 优点:
- 100% 可靠:通过受限解码技术(Constrained Decoding),模型输出的每一个字符都受到 Schema 约束,完全不会偏离。
- 零冗余:不会有任何解释性文字。
- 缺点:
- 模型限制:目前仅支持部分最新型号(如 GPT-4o 系列)。
- Schema 校验严格:如果 Schema 写的有问题,请求会直接失败。
- 编程框架封装(Pydantic / LangChain / Instructor)
利用开源库在代码层面进行封装和后处理。
- 实现方式:使用 Python 的
Pydantic定义类,通过Instructor库调用 AI,自动完成“请求 -> 提取 -> 验证 -> 重试”的闭环。 - 优点:
- 开发体验极佳:像调用普通函数一样获取 AI 结果。
- 自动重试:如果 AI 第一次返回的 JSON 缺字段,框架会自动反馈错误并让 AI 重写。
- 缺点:
- 依赖性:增加了项目的库依赖。
| 需求场景 | 推荐方式 | 稳定等级 |
|---|---|---|
| 快速原型、简单测试 | 提示词工程 | ⭐⭐ |
| 需要合法 JSON 但字段多变 | JSON Mode | ⭐⭐⭐ |
| 生产环境、复杂业务逻辑 | Function Calling | ⭐⭐⭐⭐ |
| 高严苛金融/政务系统 | Structured Outputs (Strict) | ⭐⭐⭐⭐⭐ |
开源实现
Outlines
对于json schema,outlines首先将其转为正则表达式,然后再转为token-level的Finite State Machine
随后,模型的生成过程就变成在state之间的跳转:首先从初始state出发,随后在有限的输出路径中选一条,到达下一个state,直到到达最后一个state,完成生成。
其中”有限的输出路径“就是前文所提到的tokens输出范围。
Outlines 的精髓在于它不直接处理 JSON,而是处理 FSM(有限状态机)。
- 解析 Schema:当你传入一个 Pydantic 模型或正则表达式时,
Outlines会解析其结构。 - 构建 FSM:它利用
interegular等库,将复杂的规则(如 JSON 语法或正则)转换成一个高度优化的有限状态机。 - 状态映射:在这个状态机中,每个状态都代表了当前已经生成的字符串序列。状态机明确知道:在当前状态下,下一个字符可以是哪些,不可以是哪些。
- FSM的缺点是无法准确表示复杂的schema。
guidance
Guidance 的本质是将 确定性的程序逻辑 与 不确定性的 AI 生成 缝合在一起。
在生成过程中,Guidance 采取“接力赛”模式:
- 程序控制阶段:框架直接向模型注入确定的字符串(如 JSON 的键名
{"name":)。这部分不消耗模型的推理计算,是直接“贴”上去的。 - 模型生成阶段:框架将控制权交给 AI,但限制 AI 只能在指定的“坑”里填空。填完后,框架立刻收回控制权,跳过冗余字符,直接进入下一个字段。
Instructor
主要依赖于 Pydantic、Python 动态类型以及底层模型的 Function Calling 协议
① 模式转换 (Model to Schema)
当你定义一个 Pydantic 模型并传给 Instructor 时,它会利用 Pydantic 内置的 model_json_schema() 方法,自动将这个 Python 类转换成标准的 JSON Schema。
② 协议适配 (Protocol Adaptation)
Instructor 会根据你使用的模型,将 Schema 包装进正确的 API 参数中:
- 对于 OpenAI:它会将 Schema 放入
tools或新的response_format(Structured Outputs)中。 - 对于 Anthropic/Gemini:它会调整为对应的
Tool Use或JSON Mode格式。
③ 采样约束与解析 (Sampling & Parsing)
模型返回 JSON 字符串后,Instructor 会立即进行 反序列化。
- 它尝试用你定义的 Pydantic 模型去实例化这个 JSON。
- 关键点:如果 JSON 缺少字段或类型不对,Pydantic 会抛出验证错误(ValidationError)。
④ 自动重试机制 (Self-Correction/Retries)
这是 Instructor 最强大的功能。如果解析失败,它不会直接报错,而是:
- 把 Pydantic 抛出的具体错误信息(例如:
age 字段缺失)作为新的 User Message 发回给 AI。 - 告诉 AI:“你刚才的输出不对,报错如下,请修正后重新生成。”
- 这个过程会重复 N 次,直到获取合规数据。
生产实现
在 Java 生态中,尤其是 LangChain4j 和 Spring AI 实现结构化输出的底层逻辑,其实是把“复杂的协议通信”封装成了开发者熟悉的“对象映射”。
实现方式主要分为两类:基于 API 协议的强约束(类似 OpenAI 官方方案)和 基于 Prompt 的后置解析。
- 强约束方案:基于 Function Calling (推荐)
这是 LangChain4j 等库默认的首选方式。它利用了模型厂商提供的专用接口。
- 实现步骤:
- 内省 (Introspection):当你定义一个 Java
Record或POJO时,框架会利用 Java 的反射机制读取字段名、类型和@Description注解。 - Schema 转换:框架将这些 Java 信息翻译成 JSON Schema。
- 协议请求:在调用模型 API 时,框架不会把 Schema 塞进 Prompt,而是塞进参数里的
tools或response_format字段。 - 模型输出:由于模型底层开启了“受限采样”,它会直接吐出一个干净的 JSON 字符串。
- 反序列化:框架内部使用 Jackson 或 Gson 将 JSON 字符串瞬间转回 Java 对象。
- 内省 (Introspection):当你定义一个 Java
- 弱约束方案:基于指令与 Parser (Spring AI 常用)
如果模型不支持强约束接口(如某些早期的开源模型),Java 框架会回退到这种模式。
- 实现步骤:
- 注入指令:
BeanOutputParser会生成一段非常长且严厉的 Prompt 片段,告诉 AI:“你必须只返回 JSON,字段必须叫 XXX,类型必须是 int…”。 - 后置处理:AI 返回一段包含 JSON 的文本。
- 正则提取:Java 框架会用正则表达式从一堆废话中捞出
{ ... }这一部分。 - 验证与纠错:如果 Jackson 转换失败,部分框架(如 LangChain4j)会把错误日志发回给 AI,说“你刚才生成的 JSON 少了个逗号,请重写”,这就是自动修复机制。
- 注入指令:
有效评估与改进RAG应用
首先我们要明确业务目标,然后根据业务目标制定指标,再根据实际的指标值改进检索技术。这种方法一步到位,
RAGAS
- 与竞品相比,文档相对较完备。
- 专业度比较高,专注于做RAG评测。
- 支持与LLamaIndex、LangChain等11种RAG框架集成。
Ragas目前实现了十项评估指标,我们挨个来看看。
忠实度(Faithfulness)指标用于衡量生成答案与给定上下文的事实一致性。如果生成答案中的所有声明都可以从给定的上下文中推断出来,则认为该答案是忠实的。
答案相关性(Answer Relevance)侧重于评估生成答案与给定提示的相关性。对于不完整或包含冗余信息的答案,会给出较低的分数,而较高的分数表示更好的相关性。这个指标是通过问题、上下文和答案来计算的。答案相关性定义为原始问题与基于答案生成(逆向工程)的若干人工问题之间的平均余弦相似度。
上下文查准率(Context Precision)用于判断上下文中存在的所有真实相关项,是否都排在了较高的位置。理想情况下,所有相关的信息块都应该出现在顶部排名。这个指标是通过问题、真实答案和上下文来计算的,其值范围在0到1之间,分数越高表示查准率越高。
上下文利用率(Context utilization):上下文利用就像是上下文查准率指标的无参考版本。也就是关注是否利用了所有可用的信息块,而忽略掉它们的顺序如何。
上下文查全率(Context Recall),它衡量的是检索到的上下文与作为真实答案的标注答案的一致程度。该指标是通过问题、真实答案和检索到的上下文来计算的,其值范围在0到1之间,数值越高表示性能越好。为了从真实答案中估计上下文召回率,会分析真实答案中的每个声明,以确定它是否可以归因于检索到的上下文。在理想情况下,真实答案中的所有声明都应该可以归因于检索到的上下文。
上下文实体查全率(Context entities Recall),衡量从真实答案中召回的实体比例的一个指标。具体就是根据真实答案和上下文中存在的实体数量相对于单独在真实答案中存在的实体数量,来衡量检索到的上下文的召回率。
这个指标在有事实依据的用例中很有用,比如旅游咨询台、历史问答等。这个指标可以帮助评估基于与真实答案中实体的比较的实体检索机制,因为在实体重要的情况下,我们需要覆盖这些实体的上下文。
答案语义相似度(Answer semantic similarity),用于评估生成答案与真实答案之间的语义相似度。这个评估是基于真实答案和答案进行的,其值在0到1的范围内。分数越高,表示生成的答案与真实答案间的一致性越好。
答案正确度(Answer Correctness),用衡量生成的答案与真实答案相比的准确性。这个评估依赖于真实答案和答案,分数范围从0到1。分数越高表示生成的答案与真实答案之间的一致性越好,意味着正确度更高。
答案正确度包括两个关键方面:生成答案与真实答案之间的语义相似度以及事实相似度。这些方面通过加权方案结合起来,形成答案正确性分数。用户还可以选择使用一个“阈值”值将结果分数四舍五入为二进制(如果需要)。
特定领域评估(Domain Specific Evaluation),特定领域评估指标用于评估模型在特定领域的性能。评分标准包含了每个分数的描述,通常范围在从1到5分。
摘要分数(Summarization Score),这个指标衡量摘要在捕捉上下文重要信息方面的表现如何。这个指标背后的直觉是,一个好的摘要应该包含上下文所有重要信息。我们首先从上下文中提取一组重要的关键词。然后使用这些关键词生成一组问题。接着我们向摘要提出这些问题,并计算摘要得分为正确回答的问题数与问题总数的比率。
现如果你想直接把刚刚这些Ragas指标用到我们前面实战案例的评估,就会发现门槛还是有点高,难度比较大。为什么呢?因为我们没有评估所需要的基础数据,所以我们需要先采集相关数据。
那如何采集评估所需要的基础数据呢?一种方法是让数据标注员人工提问和标注,这种方法成本很高。目前最常见,也是最容易的方法是让用户直接提供反馈,然后收集这些结果,再让数据标注员分析和标注。
Precision、Recall、F1、MRR
这三个指标通常用于评估二分类模型或非排序的检索结果。
Precision (精确率/查准率):
衡量“检索出的结果中,有多少是真正相关的”。
Recall (召回率/查全率):
衡量“所有真正相关的结果中,有多少被成功找回了”。
F1-Score:
精确率和召回率的调和平均数。当两者出现冲突时(例如一个高一个低),$F1$ 提供了一个平衡的评估标准。
在搜索和推荐场景中,相关条目的排名越靠前,用户体验越好。
MRR (Mean Reciprocal Rank, 平均倒数排名):
它只关注第一个相关结果出现的位置。
计算逻辑:对于一个查询,如果第一个相关结果排在第 $n$ 位,其倒数排名就是 $1/n$。将所有查询的倒数排名取平均值即为 MRR。
公式:
特点:MRR 越高,说明系统能越快地让用户找到想要的第一个信息。
RRF 倒数排名
RRF (Reciprocal Rank Fusion, 倒数排名融合) 严格来说不是一种单纯的“评估指标”,而是一种将多个排序列表融合为一个的算法。它在混合搜索(Hybrid Search,如:关键词检索 + 向量检索)中非常流行。
原理:它不依赖各个检索系统给出的具体分数(因为不同系统的分数尺度不同,无法直接相加),而是只依赖它们的排名。
核心公式:
对于文档 $d$,其在所有排名列表 $R$ 中的总分为:
- $r(d)$:文档 $d$ 在列表 $r$ 中的排名位置。
- $k$:一个常数(平滑因子),通常取 60。
为什么有用?
RRF 具有“二八定律”的特性:排在前面的文档权重会迅速衰减,而多个列表共同排在前面的文档会获得极高的总分。它能非常简单且有效地结合语义搜索和传统搜索的优点。
其他RAG技术
GraphRAG
GraphRAG是一种结合了知识图谱的检索增强生成技术,旨在通过构建知识图谱和社区检测算法,提升大模型在理解和生成复杂信息方面的能力。它通过图结构信息,能够更精确地检索和生成与上下文相关的回答,从而在处理大规模数据集时展现出显著的性能提升
规范化RAG应用
RAG链路级优化

从知识入库处理到最终生成评估.
SpringAI智能面试平台+RAG
基于Tika实现多格式内容提取与解析
工具调用
Function Calling(函数调用)是让 LLM 能够使用外部工具的核心机制。Function Calling允许模型决定何时调用工具、调用哪个工具,以及传递什么参数。
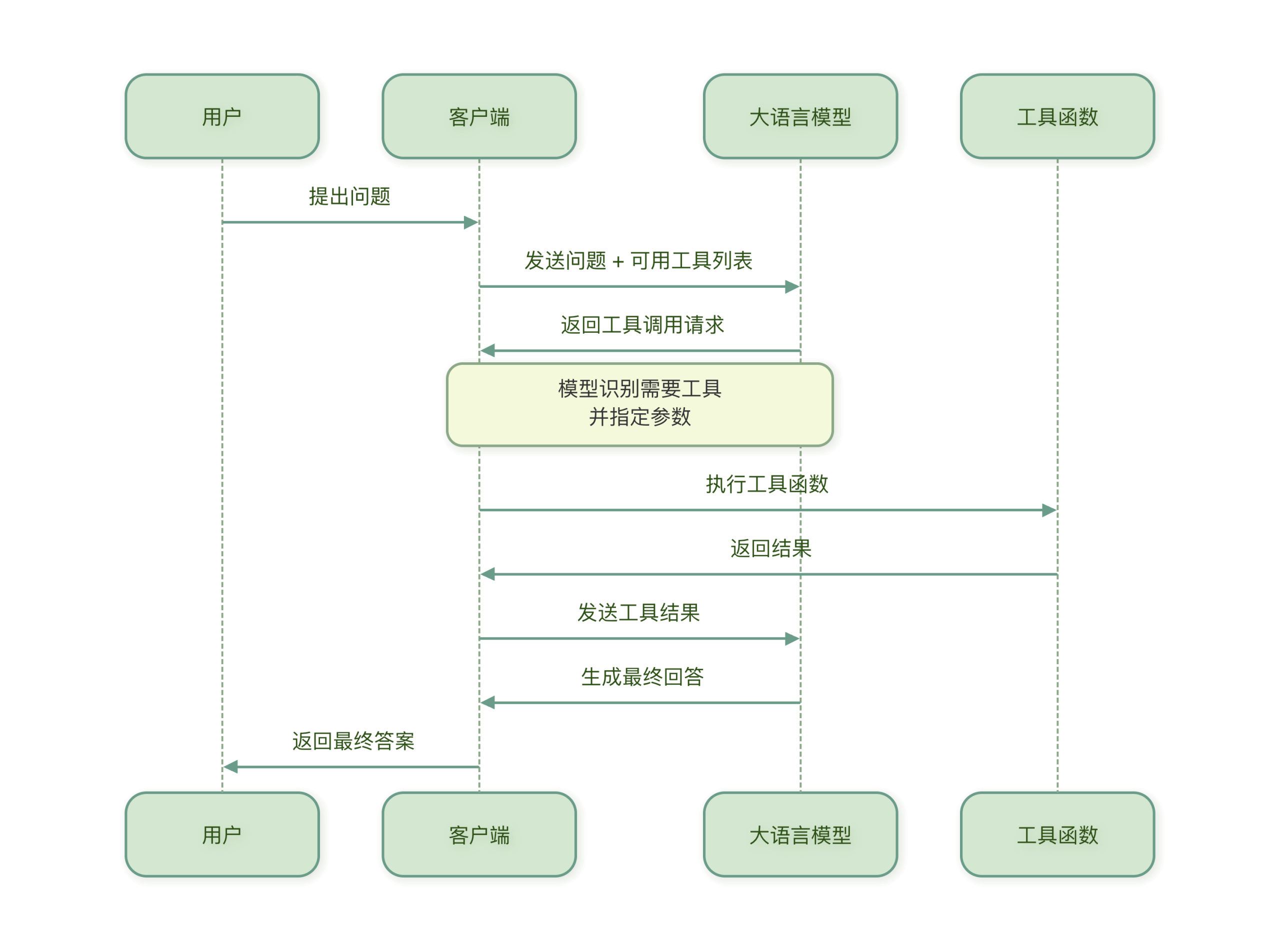 核心概念
核心概念
- 工具定义:描述一个工具的功能、参数和返回值
- 工具选择:LLM 根据用户问题选择合适的工具
- 参数提取:LLM 从问题中提取工具所需的参数
- 结果处理:将工具执行结果整合到最终回答中
假设我们有一个查询天气的工具,当用户问北京今天天气如何?时:
- LLM 识别出需要调用天气查询工具
- 从问题中提取参数:
city="北京",date="今天" - 调用天气 API 获取数据
- 将天气数据整合成友好的回答返回给用户
要让 LLM 正确使用工具,首先需要清晰地定义工具,好的工具定义应该像一份清晰的说明书,让 LLM 明白:
- 这个工具是做什么的?
- 什么时候使用它?
- 需要什么参数?
- 参数是什么格式?
工具定义的结构
一个完整的工具定义通常包含以下部分:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20# 工具定义示例结构
weather_tool = {
"name": "get_weather", # 工具名称
"description": "获取指定城市的天气信息", # 工具描述
"parameters": { # 参数定义
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称,如'北京'、'上海'"
},
"date": {
"type": "string",
"description": "日期,格式'YYYY-MM-DD',或'今天'、'明天'",
"enum": ["今天", "明天", "后天"]
}
},
"required": ["city"] # 必填参数
}
}
难点 1:参数提取不准确(最常见)
- 问题表现:模型漏提参数、提错参数类型(比如把 “北京” 识别成数字)、参数值不符合规则(比如城市名写成 “北京市市”)。
典型场景:用户说 “查下上海明天的空气质量”,模型可能漏提 “明天” 这个时间参数,只调用
get_air_quality(city="上海"),导致返回今天的数据。解决 “参数提取不准确”:结构化提示 + 参数校验
核心思路:
- 在提示词中明确参数的名称、类型、约束条件(比如城市名只能是中文,时间格式为 YYYY-MM-DD);
- 调用工具前加一层参数校验逻辑,不符合规则就让模型重新提取。
示例提示词:
1
2
3
4
5
6你需要调用工具解决用户问题,规则如下:
1. 工具:get_weather(city: str, date: str)
2. 参数约束:
- city:必须是中国城市的中文全称,如“北京”“上海”,不能加“市”;
- date:可选,格式为YYYY-MM-DD,默认是当天。
3. 若参数缺失或不符合规则,必须重新追问用户或修正。
参数校验逻辑1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26def validate_parameters(func_name, params):
"""校验函数参数"""
# 定义各函数的参数规则
func_rules = {
"get_weather": {
"city": {"type": str, "required": True, "pattern": r"^[\u4e00-\u9fa5]{2,4}$"},
"date": {"type": str, "required": False, "pattern": r"^\d{4}-\d{2}-\d{2}$"}
}
}
if func_name not in func_rules:
return False, "工具不存在"
rules = func_rules[func_name]
for param, rule in rules.items():
# 检查必填参数
if rule["required"] and param not in params:
return False, f"缺失必填参数:{param}"
# 检查参数类型
if param in params and not isinstance(params[param], rule["type"]):
return False, f"{param}类型错误,需为{rule['type'].__name__}"
# 检查参数格式(如正则)
if param in params and rule.get("pattern") and not re.match(rule["pattern"], params[param]):
return False, f"{param}格式错误,需符合规则:{rule['pattern']}"
return True, "参数校验通过"
2. 难点 2:输出格式不规范
- 问题表现:模型输出的调用指令不符合程序解析要求(比如 JSON 格式缺引号、多逗号、字段名写错),导致代码解析失败。
- 典型场景:要求输出
{"name":"get_weather","parameters":{"city":"北京"}},模型却输出{name:get_weather, parameters:{city:北京}}(缺引号),程序直接报错。
解决 “输出格式不规范”:强制格式约束 + JSON 模式
核心思路:
- 用JSON Schema 定义输出格式(明确字段名、类型),让模型严格遵循;
- 主流大模型(GPT-3.5/4、Claude、文心一言)都支持 “强制 JSON 输出”,直接指定格式即可。
1 | from openai import OpenAI |
大模型的 “强制 JSON 输出” 不是单一技术,而是训练阶段的格式对齐 + 推理阶段的约束机制 共同作用的结果,
训练阶段:给模型 “植入” JSON 语法认知
这是所有模型能输出合法 JSON 的基础,也是 “强制输出” 的底层前提。
数据层面:大规模 JSON 格式数据注入
做法
:在模型预训练 / 微调阶段,加入海量的 “自然语言 ↔ JSON” 配对数据,比如:
- 输入:“提取北京明天的气温” → 输出:
{"city":"北京","date":"明天","action":"查气温"}; - 输入:“计算 1+2” → 输出:
{"operation":"add","num1":1,"num2":2,"result":3};
- 输入:“提取北京明天的气温” → 输出:
目的:让模型学习 “自然语言需求” 和 “合法 JSON 结构” 的强映射关系,理解 JSON 的语法规则(双引号、键值对、无多余逗号等)。
关键细节:
- 数据中会包含大量 “错误 JSON 案例 + 修正结果”(比如缺少双引号的 JSON → 模型输出修正后的合法 JSON);
- 对 GPT-4 这类原生支持 JSON 的模型,还会单独构建 “JSON 语法专项数据集”(包含 JSON Schema 约束、嵌套 JSON、数组等复杂场景)。
模型架构层面:针对性的格式约束模块(GPT 专属)
OpenAI 为 GPT-3.5-turbo-1106/4 新增了格式约束头(Format Constraint Head),这是其 “原生强制 JSON” 的核心:
- 位置:在模型的 decoder 层最后,加一个独立的 “语法校验模块”;
- 作用:
- 接收上层输出的 token 序列(比如
{"city":"北京"); - 实时校验是否符合 JSON 语法规则(比如是否漏双引号、是否有多余逗号);
- 对违规的 token 进行 “抑制”(比如模型想输出单引号
'北京',该模块会降低单引号 token 的概率,提升双引号"的概率);
- 接收上层输出的 token 序列(比如
- 对比:Claude / 文心一言暂未在模型架构层加这类硬件模块,而是靠后续推理阶段的规则弥补。
微调阶段:指令调优(RLHF)强化 JSON 格式
做法
:在人类反馈强化学习(RLHF)阶段,加入 “JSON 格式正确性” 的奖励机制:
- 如果模型输出合法 JSON → 给予高奖励(提升该输出路径的概率);
- 如果输出非法 JSON(比如缺引号、多逗号)→ 给予惩罚(降低该路径概率);
GPT 额外操作:对 “response_format=json_object” 这类参数,单独做了 “指令调优”,让模型识别到该参数后,直接激活 “JSON 约束模式”。
推理阶段:实时约束输出,确保 JSON 合法
训练阶段是 “让模型会写 JSON”,推理阶段是 “强制模型必须写合法 JSON”,这是 “强制输出” 的核心执行层。
- GPT 系列:原生语法锁(硬限制)
当调用 response_format={"type":"json_object"} 时,模型推理过程会触发以下底层逻辑:模型无法输出任何非 JSON 内容(比如 “以下是结果:” 这类文字),因为格式约束头会直接过滤掉这类 token;
如果模型无法生成合法 JSON(比如需求矛盾),会直接终止推理并返回 API 错误,而非输出错误 JSON;
生成过程中会自动补全 JSON 缺失部分(比如模型生成 {"city":"北京",会自动补全 }
2.Claude 系列:提示词引导 + 生成后校验(软限制)
Claude 没有模型层的 “JSON 语法锁”,其 “强制输出” 靠两步实现:
- 推理初期:提示词解析为格式规则
- 模型先解析用户提示词中的 JSON 要求(比如 “仅输出 JSON”“字段名双引号”),将其转化为内部的 “生成规则”;
- 生成时,模型会优先选择符合 JSON 语法的 token(基于训练阶段的认知)。
- 推理后期:生成后语法校验
- Claude 生成完文本后,会有一个轻量级的 “JSON 校验模块”(属于推理框架,非模型层);
- 如果检测到 JSON 非法(比如缺逗号),会自动修正后输出;如果无法修正,会重新生成。
- 特点:依赖提示词的清晰度,没有 GPT 那样的 “硬锁”,但通过训练数据的强引导,成功率接近 100%。
不管是哪种模型,“强制 JSON 输出” 最终都会落到 “token 生成的概率控制” 上(这是模型推理的最底层):
- Token 概率重加权
做法
:在生成每个 token 时,调整不同 token 的概率:
- 提升 JSON 合规 token 的概率(比如
"、{、}、,); - 降低违规 token 的概率(比如
'、:、中文逗号,、多余的空格);
- 提升 JSON 合规 token 的概率(比如
- 上下文窗口的格式记忆
- 模型会在推理的上下文窗口中,“记住” 当前的 JSON 结构状态:
- 比如已经生成了
{,模型会记住 “需要闭合}”; - 生成了
"city":"北京",会记住 “下一个可能是,或}”;
- 比如已经生成了
- GPT 的格式约束头会专门维护这个 “JSON 状态机”,而 Claude 靠训练数据的记忆实现。
- 难点 3:工具匹配错误
- 问题表现:模型选错工具(比如用户要算加法,却调用了乘法工具),或没必要调用工具时强行调用(比如用户问 “1+1 等于几”,本可直接回答,却调用计算器工具)。
核心思路:
- 给每个工具写精准、唯一的描述(避免模糊,比如 “get_weather” 描述为 “仅用于获取城市气温,不包含空气质量、风力”);
对高风险调用(比如涉及付费 API),增加 “模型自我确认” 步骤,让模型先判断 “是否需要调用工具”“是否选对工具”。
难点 4:上下文丢失
- 问题表现:多轮对话中,模型忘记上一轮的参数(比如用户先问 “北京气温”,接着说 “空气质量呢”,模型没识别出 “北京” 这个上下文参数)。
核心思路:
- 把多轮对话中的参数缓存到上下文(比如用户先提 “北京”,后续对话自动带上
city="北京"); - 若参数缺失,让模型主动追问用户(比如用户说 “查气温”,模型回复 “请问你想查哪个城市的气温?”)
记忆系统
人类的记忆分为短期记忆和长期记忆,AI Agent 的记忆系统也采用了类似的设计。
理解这两种记忆的区别和用途,是构建智能 Agent 的基础。
短期记忆:Agent 的工作记忆
短期记忆就像是 Agent 的工作台,存储当前对话的上下文和临时信息。
特点:
- 容量有限:通常只能保存最近的几次对话(如最近的 10-20 轮对话)
- 快速访问:读取和写入速度很快
- 临时性:对话结束后通常会被清除或压缩
- 上下文相关:直接影响当前的响应生成
长期记忆:Agent 的知识库
长期记忆就像是 Agent 的档案室,存储重要的、需要长期保留的信息。
特点:
- 容量大:可以存储大量信息
- 持久化:信息会长期保存,不会自动清除
- 检索式访问:通过查询检索相关信息,而非顺序读取
- 结构化存储:信息通常以结构化方式存储,便于检索
主要用途:
- 存储用户的个人信息和偏好
- 积累知识和经验
- 记住重要的对话内容
- 保存任务执行结果
对话历史管理
基本的对话历史管理
1 | class ConversationManager: |
智能历史选择策略
不是所有历史对话都同样重要。智能的历史选择可以提高上下文的使用效率:
1. 基于时间的衰减
1 | def time_based_selection(history, current_time, max_items=10): |
2. 基于相关性的选择
1 | def relevance_based_selection(history, current_query, embedding_model, max_items=5): |
3. 混合选择策略
1 | class SmartHistorySelector: |
记忆压缩与总结策略
随着对话的进行,记忆会不断累积。为了避免信息过载和减少资源消耗,需要定期对记忆进行压缩和总结。
记忆压缩策略
1. 基于重要性的压缩
1 | class ImportanceBasedCompressor: |
2. 基于聚类的压缩
将相似记忆聚类,然后总结每个聚类:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72from sklearn.cluster import KMeans
import numpy as np
class ClusterBasedCompressor:
"""基于聚类的记忆压缩器"""
def __init__(self, embedding_model):
self.embedding_model = embedding_model
def compress_by_clustering(self, memories, n_clusters=None):
"""通过聚类压缩记忆"""
if len(memories) <= 3:
return memories # 记忆太少,不需要聚类
# 确定聚类数量
if n_clusters is None:
n_clusters = min(3, len(memories) // 2)
# 获取所有记忆的embedding
embeddings = []
for memory in memories:
embedding = self.embedding_model.encode(memory["content"])
embeddings.append(embedding)
embeddings = np.array(embeddings)
# 执行K-means聚类
kmeans = KMeans(n_clusters=n_clusters, random_state=42, n_init=10)
labels = kmeans.fit_predict(embeddings)
# 对每个聚类进行总结
compressed_memories = []
for cluster_id in range(n_clusters):
# 获取该聚类的所有记忆
cluster_memories = [
memories[i] for i in range(len(memories)) if labels[i] == cluster_id
]
if cluster_memories:
# 总结该聚类的记忆
summary = self.summarize_cluster(cluster_memories)
compressed_memories.append(summary)
return compressed_memories
def summarize_cluster(self, cluster_memories):
"""总结一个聚类的记忆"""
if len(cluster_memories) == 1:
# 只有一个记忆,直接返回
return cluster_memories[0]
# 合并所有记忆内容
all_content = "\n".join([m["content"] for m in cluster_memories])
# 使用LLM生成总结(这里简化实现)
# 实际应调用LLM生成高质量的总结
summary_content = f"相关主题的{len(cluster_memories)}条记忆摘要:{all_content[:500]}..."
# 合并元数据
merged_metadata = {
"type": "cluster_summary",
"original_count": len(cluster_memories),
"compressed": True,
"timestamp": time.time()
}
return {
"content": summary_content,
"metadata": merged_metadata
}
3. 增量总结策略
在对话过程中逐步总结,而不是一次性处理所有历史:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78class IncrementalSummarizer:
"""增量总结器"""
def __init__(self, llm_client, summary_interval=5):
self.llm = llm_client
self.summary_interval = summary_interval # 每多少轮对话总结一次
self.conversation_buffer = []
self.summaries = []
def add_conversation(self, user_input, assistant_response):
"""添加对话到缓冲区"""
self.conversation_buffer.append({
"user": user_input,
"assistant": assistant_response,
"timestamp": time.time()
})
# 检查是否需要总结
if len(self.conversation_buffer) >= self.summary_interval:
self.create_summary()
def create_summary(self):
"""创建总结"""
if not self.conversation_buffer:
return
# 将对话缓冲区的所有内容总结为一段文字
conversation_text = ""
for exchange in self.conversation_buffer:
conversation_text += f"用户: {exchange['user']}\n"
conversation_text += f"助理: {exchange['assistant']}\n\n"
# 使用LLM生成总结
prompt = f"""
请将以下对话内容总结为一个简短的段落,保留核心信息和重要细节:
对话内容:
{conversation_text}
总结要求:
1. 不超过200字
2. 保留用户的主要需求和助理的关键回答
3. 忽略问候语、重复内容和无关细节
总结:
"""
summary = self.llm.generate(prompt, max_tokens=200)
# 保存总结
self.summaries.append({
"content": summary,
"timestamp": time.time(),
"original_count": len(self.conversation_buffer)
})
# 清空缓冲区
self.conversation_buffer.clear()
def get_context(self, include_recent=True, include_summaries=True):
"""获取上下文"""
context_parts = []
if include_summaries and self.summaries:
# 添加所有总结
for i, summary in enumerate(self.summaries[-3:]): # 最多3个总结
context_parts.append(f"[对话总结 {i+1}]\n{summary['content']}")
if include_recent and self.conversation_buffer:
# 添加最近的对话
for exchange in self.conversation_buffer[-3:]: # 最多3轮最近对话
context_parts.append(f"用户: {exchange['user']}")
context_parts.append(f"助理: {exchange['assistant']}")
return "\n\n".join(context_parts)
