将一个图像中的风格应用在另一图像之上,即风格迁移(style transfer)这里我们需要两张输入图像:一张是内容图像,另一张是风格图像。 我们将使用神经网络修改内容图像,使其在风格上接近风格图像。
使用预训练模型进行迁移

首先,我们初始化合成图像,例如将其初始化为内容图像。
该合成图像是风格迁移过程中唯一需要更新的变量,即风格迁移所需迭代的模型参数。 然后,我们选择一个预训练的卷积神经网络来抽取图像的特征,其中的模型参数在训练中无须更新。 这个深度卷积神经网络凭借多个层逐级抽取图像的特征,我们可以选择其中某些层的输出作为内容特征或风格特征。
接下来,我们通过前向传播(实线箭头方向)计算风格迁移的损失函数,并通过反向传播(虚线箭头方向)迭代模型参数,即不断更新合成图像。 风格迁移常用的损失函数由3部分组成:
- 内容损失使合成图像与内容图像在内容特征上接近;
- 风格损失使合成图像与风格图像在风格特征上接近;
- 全变分损失则有助于减少合成图像中的噪点。
最后,当模型训练结束时,我们输出风格迁移的模型参数,即得到最终的合成图像。
使用一个预训练模型,比如VGG提取内容与特征.1
pretrained_net = torchvision.models.vgg19(pretrained=True)
为了抽取图像的内容特征和风格特征,我们可以选择VGG网络中某些层的输出。
一般来说,越靠近输入层,越容易抽取图像的细节信息;反之,则越容易抽取图像的全局信息。 为了避免合成图像过多保留内容图像的细节,我们选择VGG较靠近输出的层,即内容层,来输出图像的内容特征。
我们从VGG中选择不同层的输出来匹配局部和全局的风格,这些图层也称为风格层。 VGG网络使用了5个卷积块。可以选择第四卷积块的最后一个卷积层作为内容层,选择每个卷积块的第一个卷积层作为风格层。1
2
3style_layers, content_layers = [0, 5, 10, 19, 28], [25]
net = nn.Sequential(*[pretrained_net.features[i] for i in
range(max(content_layers + style_layers) + 1)])1
2
3
4
5
6
7
8
9
10
11def extract_features(X, content_layers, style_layers):
contents = []
styles = []
for i in range(len(net)):
X = net[i](X)
# forward pass 如果是选定的风格层或者是内容层 添加到列表中
if i in style_layers:
styles.append(X)
if i in content_layers:
contents.append(X)
return contents, styles1
2
3
4
5
6
7
8
9def get_contents(image_shape, device):
content_X = preprocess(content_img, image_shape).to(device)
contents_Y, _ = extract_features(content_X, content_layers, style_layers)
return content_X, contents_Y
def get_styles(image_shape, device):
style_X = preprocess(style_img, image_shape).to(device) # 得到tensor数据 放入网络中 将输出这张图像的内容和风格
_, styles_Y = extract_features(style_X, content_layers, style_layers)
return style_X, styles_Y
get_contents函数对内容图像抽取内容特征; get_styles函数对风格图像抽取风格特征。 因为在训练时无须改变预训练的VGG的模型参数,所以我们可以在训练开始之前就提取出内容特征和风格特征。
由于合成图像是风格迁移所需迭代的模型参数,我们只能在训练过程中通过调用extract_features函数来抽取合成图像的内容特征和风格特征.1
2
3
4
5
6
7
8
9
10
11
12
13
14rgb_mean = torch.tensor([0.485, 0.456, 0.406])
rgb_std = torch.tensor([0.229, 0.224, 0.225])
def preprocess(img, image_shape):
transforms = torchvision.transforms.Compose([
torchvision.transforms.Resize(image_shape),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=rgb_mean, std=rgb_std)])
return transforms(img).unsqueeze(0)
def postprocess(img):
img = img[0].to(rgb_std.device)
img = torch.clamp(img.permute(1, 2, 0) * rgb_std + rgb_mean, 0, 1)
return torchvision.transforms.ToPILImage()(img.permute(2, 0, 1))
preprocess与postprocess分别将PIL数据转为tensor,tensor转为PIL数据.
损失函数
内容损失
容损失通过平方误差函数衡量合成图像与内容图像在内容特征上的差异。 平方误差函数的两个输入均为extract_features函数计算所得到的内容层的输出1
2
3
4def content_loss(Y_hat, Y):
# 我们从动态计算梯度的树中分离目标:
# 这是一个规定的值,而不是一个变量。
return torch.square(Y_hat - Y.detach()).mean()
风格损失
风格损失与内容损失类似,也通过平方误差函数衡量合成图像与风格图像在风格上的差异。 为了表达风格层输出的风格,我们先通过extract_features函数计算风格层的输出。 假设该输出的样本数为1,通道数为c,高和宽分别为h和w,我们可以将此输出转换为矩阵X,其有c行和hw列。 这个矩阵可以被看作由c个长度为hw的向量x1,…,xc组合而成的。其中向量xi代表了通道i上的风格特征。1
2
3
4def gram(X):
num_channels, n = X.shape[1], X.numel() // X.shape[1]
X = X.reshape((num_channels, n))
return torch.matmul(X, X.T) / (num_channels * n)
风格损失的平方误差函数的两个格拉姆矩阵输入分别基于合成图像与风格图像的风格层输出。这里假设基于风格图像的格拉姆矩阵gram_Y已经预先计算好了1
2def style_loss(Y_hat, gram_Y):
return torch.square(gram(Y_hat) - gram_Y.detach()).mean()
全变分损失
有时候,我们学到的合成图像里面有大量高频噪点,即有特别亮或者特别暗的颗粒像素。 一种常见的去噪方法是全变分去噪(total variation denoising): 假设xi,j表示坐标(i,j)处的像素值,降低全变分损失∑i,j|xi,j−xi+1,j|+|xi,j−xi,j+1|
能够尽可能使邻近的像素值相似。1
2def tv_loss(Y_hat):
return 0.5 * (torch.abs(Y_hat[:, :, 1:, :] - Y_hat[:, :, :-1, :]).mean() +torch.abs(Y_hat[:, :, :, 1:] - Y_hat[:, :, :, :-1]).mean())
损失函数1
2
3
4
5
6
7
8
9content_weight, style_weight, tv_weight = 1, 1e3, 10
def compute_loss(X, contents_Y_hat, styles_Y_hat, contents_Y, styles_Y_gram):
# 分别计算内容损失、风格损失和全变分损失
contents_l = [content_loss(Y_hat, Y) * content_weight for Y_hat, Y in zip(contents_Y_hat, contents_Y)]
styles_l = [style_loss(Y_hat, Y) * style_weight for Y_hat, Y in zip(styles_Y_hat, styles_Y_gram)]
tv_l = tv_loss(X) * tv_weight
# 对所有损失求和
l = sum(10 * styles_l + contents_l + [tv_l])
return contents_l, styles_l, tv_l, l
contents_l表示内容损失,
初始化合成图像
1 | def get_inits(X, device, lr, styles_Y): |
1 | class SynthesizedImage(nn.Module): |
训练模型
1 | def train(X, contents_Y, styles_Y, device, lr, num_epochs, lr_decay_epoch): |
1 | device, image_shape = d2l.try_gpu(), (300, 450) |
合成图像保留了内容图像的风景和物体,并同时迁移了风格图像的色彩。例如,合成图像具有与风格图像中一样的色彩块,其中一些甚至具有画笔笔触的细微纹理
结果展示

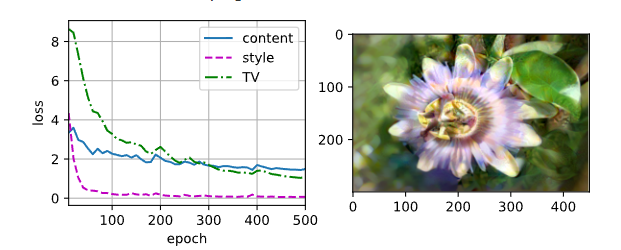
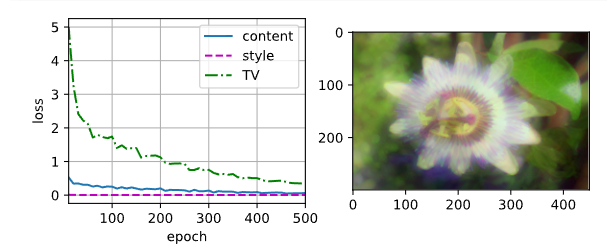
可以尝试改动style_weight,看看风格变换.比如style_weight增大,发现style loss太小了,而且会影响content loss
- 风格迁移常用的损失函数由3部分组成:(1)内容损失使合成图像与内容图像在内容特征上接近;(2)风格损失令合成图像与风格图像在风格特征上接近;(3)全变分损失则有助于减少合成图像中的噪点。
- 我们可以通过预训练的卷积神经网络来抽取图像的特征,并通过最小化损失函数来不断更新合成图像来作为模型参数。
- 我们使用gram矩阵表达风格层输出的风格
使用GAN进行风格迁移
GANs是生成艺术图像的好方法。另一种有趣的技术是所谓的风格转换,它获取一个内容图像,然后用不同的风格重新绘制,从风格图像中应用过滤器。
工作方式如下:
我们从随机噪声图像开始(或从内容图像开始,但为了理解起见,从随机噪声开始更容易)
我们的目标是创建这样一个图像,它将接近内容图像和风格图像。这将由两个损失函数确定:基于CNN在当前图像和内容图像的某些层提取的特征来计算内容损失,使用Gram矩阵巧妙地计算当前图像和风格图像之间的风格损失
为了使图像更平滑并去除噪声,我们还引入了全变分损失,它计算相邻像素之间的平均距离
优化方式使用梯度下降(或一些其他优化算法)调整当前图像,以最小化总损失,总损失是所有三个损失的加权和。
在代码上与之前的差别是使用高斯分布采样得到的噪音作为需要优化的参数,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49img_style = load_image('images/style.jpg')
img_content = load_image('images/image.jpg')
img_result = np.random.uniform(size=(img_size,img_size,3))
vgg = tf.keras.applications.VGG16(include_top=False, weights='imagenet')
vgg.trainable = False
def layer_extractor(layers):
outputs = [vgg.get_layer(x).output for x in layers]
model = tf.keras.Model([vgg.input],outputs)
return model
content_layers = ['block4_conv2']
content_extractor = layer_extractor(content_layers)
content_target = content_extractor(preprocess_input(tf.expand_dims(img_content,axis=0)))
def content_loss(img):
z = content_extractor(preprocess_input(tf.expand_dims(255*img,axis=0)))
return 0.5*tf.reduce_sum((z-content_target)**2)
def gram_matrix(x):
result = tf.linalg.einsum('bijc,bijd->bcd', x, x)
input_shape = tf.shape(x)
num_locations = tf.cast(input_shape[1]*input_shape[2], tf.float32)
return result/(num_locations)
style_layers = ['block1_conv1','block2_conv1','block3_conv1','block4_conv1']
def style_extractor(img):
return [gram_matrix(x) for x in layer_extractor(style_layers)(img)]
style_target = style_extractor(preprocess_input(tf.expand_dims(img_style,axis=0)))
def style_loss(img):
z = style_extractor(preprocess_input(tf.expand_dims(255*img,axis=0)))
loss = tf.add_n([tf.reduce_mean((x-target)**2)
for x,target in zip(z,style_target)])
return loss / len(style_layers)
def variation_loss(img):
img = tf.cast(img,tf.float32)
x_var = img[ :, 1:, :] - img[ :, :-1, :]
y_var = img[ 1:, :, :] - img[ :-1, :, :]
return tf.reduce_sum(tf.abs(x_var)) + tf.reduce_sum(tf.abs(y_var))
def total_loss_var(img):
return content_loss(img)+150*style_loss(img)+30*variation_loss(img)
img.assign(clip(np.random.normal(-0.3,0.3,size=img_content.shape)+img_content/255.0))
train(img,loss_fn=total_loss_var)
注意,提取风格的层数一般选择每个特征块的前面几层,而提取内容的层数一般选择特征块的后面几块.
风格迁移与迁移学习存在不可区分的关系,因为我们将一些知识从一个神经网络模型转移到另一个。在迁移学习中,我们通常从预先训练的模型开始,该模型已经在一些大型图像数据集(如ImageNet)上进行了训练。
预训练模型比如:
- VGG-16/VGG-19,它们是相对简单的模型,仍然提供良好的精度。经常将VGG作为第一次尝试是了解迁移学习如何运作的好选择。
- ResNet是微软研究院于2015年提出的一系列模型。它们有更多的层,因此占用更多的资源。
- MobileNet是一系列尺寸较小的型号,适用于移动设备。如果你缺乏资源,并且可能会牺牲一点准确性,那么就使用它们。
使用pytorch加载预训练模型.1
2vgg = torchvision.models.vgg16(pretrained=True)
vgg
结构如下,可以看见有features,avgpool以及classifier1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
查看每一层后的结果
利用torchinfo库查看1
summary(vgg,input_size=(1,3,224,224))

可以看到输入一张3通道224的图像特征层输出是512通道的宽高为7的特征
提取图像特征1
2
3
4res = vgg.features(sample_image).cpu()
plt.figure(figsize=(15,3))
plt.imshow(res.detach().view(512,-1).T)
print(res.size())
利用feature层提取特征,然后利用预训练模型提取的特征,直接拿一个简单的Linear层作为分类器进行训练,比如:1
2
3
4
5
6
7
8vgg_dataset = torch.utils.data.TensorDataset(feature_tensor,label_tensor.to(torch.long))
train_ds, test_ds = torch.utils.data.random_split(vgg_dataset,[700,100])
train_loader = torch.utils.data.DataLoader(train_ds,batch_size=32)
test_loader = torch.utils.data.DataLoader(test_ds,batch_size=32)
net = torch.nn.Sequential(torch.nn.Linear(512*7*7,2),torch.nn.LogSoftmax()).to(device)
history = train(net,train_loader,test_loader)
net就是简单的线性层加一个激活函数
常用的加载数据流程1
2
3
4
5
6
7
8
9std_normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
trans = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
std_normalize])
dataset = torchvision.datasets.ImageFolder('data/PetImages',transform=trans)
trainset, testset = torch.utils.data.random_split(dataset,[20000,len(dataset)-20000])
如果图像在一个文件夹中,利用ImageFolder得到dataset.然后使用dl = torch.utils.data.DataLoader(dataset,batch_size=bs,shuffle=True)用于循环每个batch处理.
可以在训练过程中使用原始VGG-16网络作为一个整体来避免手动预计算特征.如下
- 将最终分类器替换为将产生所需数量的类的分类器。
- 冻结卷积特征提取器的权重,使得它们不被训练。建议最初进行这种冻结,因为否则未经训练的分类器层可能会破坏卷积提取器的原始预训练权重。冻结权重可以通过将所有参数的requires_grad属性设置为False来实现
1 | for x in vgg.features.parameters(): |
如果您的对象在视觉上与普通的ImageNet图像不同,则这种功能组合可能无法发挥最佳效果。因此,开始训练卷积层也是有意义的。 为此,我们可以解冻之前冻结的卷积滤波器参数。不过一般都会采用一些微调方法,比如LoRA等.
其他方向
domain knowledge,domain adaption或者是transfer learning,本质上都是像提取一些特征,这种特征能在多个domain上使用.我们可以考虑利用这种特征进行可视化或者对抗攻击等.
比如利用预训练模型作为分类器,尝试从下从正态分布采样得到噪声图,然后作为输入,优化这个输入使其被分类为想要的分类.这样的图像虽然被正确分类了但人眼还是能明显看出差别.

这种噪音对我们来说没有多大意义,但很可能它包含了很多需要的类别(比如猫)特有的低级别过滤器。然而,由于有很多方法可以优化输入以获得理想的结果,因此优化算法没有动机找到视觉上可理解的模式.
为了让它看起来不那么像噪音,我们可以在损失函数中引入一个附加项——变化损失。它测量图像的相邻像素的相似程度。如果我们将这个项添加到损失函数中,它将迫使优化器找到噪声较小的解决方案,从而具有更多可识别的细节
1 | def total_loss(target,res): |
也就是分类的损失加上全变分损失.全变分损失目的是减小噪声,得到图像图下
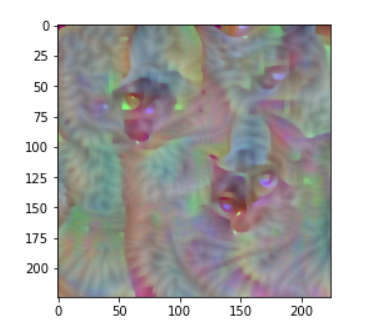
对抗攻击就利用一张本身是狗分类也确实是狗的图片,对这张图片进行优化1
2x = tf.Variable(np.expand_dims(img,axis=0).astype(np.float32)/255.0)
optimize(x,target,epochs=100)
在pytorch中使用autograd计算梯度.pytorch 中autograd.grad()函数的用法说明 | w3cschool笔记
最后推荐一下微软的Ai for beginners的课程,质量比较高,此外还有李沐的d2l,台湾李宏毅老师的深度学习课程以及fast.ai课程,都是比较好的.
我们能够在预先训练的CNN中可视化猫(以及任何其他物体)的理想图像,使用梯度下降优化来调整输入图像而不是权重。获得有意义的图像的主要技巧是使用变化损失作为额外的损失函数,这会使图像看起来更平滑。
参考资料
- 13.12. 风格迁移 — 动手学深度学习 2.0.0 documentation (d2l.ai)
- AI-For-Beginners/lessons/4-ComputerVision/10-GANs at main · microsoft/AI-For-Beginners (github.com)
- [1508.06576] A Neural Algorithm of Artistic Style (arxiv.org)
- AI-For-Beginners/lessons/4-ComputerVision/08-TransferLearning/README.md at main · microsoft/AI-For-Beginners (github.com)
